Transformer
自Attention机制提出后,加入attention的Seq2seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型,具体原理可以参考传送门的文章。之后google又提出了解决sequence to sequence问题的transformer模型,用全attention的结构代替了lstm,在翻译任务上取得了更好的成绩。本文主要介绍《Attention is all you need》这篇文章,自己在最初阅读的时候还是有些不懂,希望可以在自己的解读下让大家更快地理解这个模型^ ^
1. 模型结构
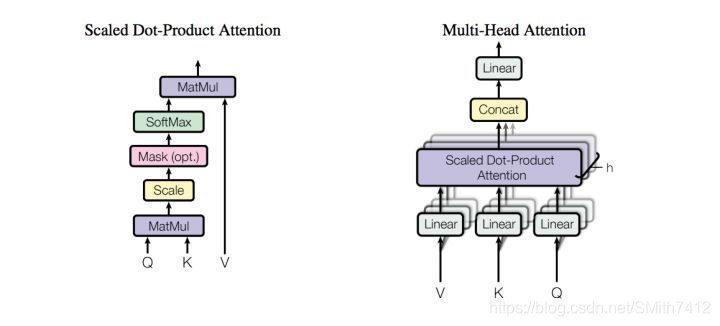
模型结构如下图:
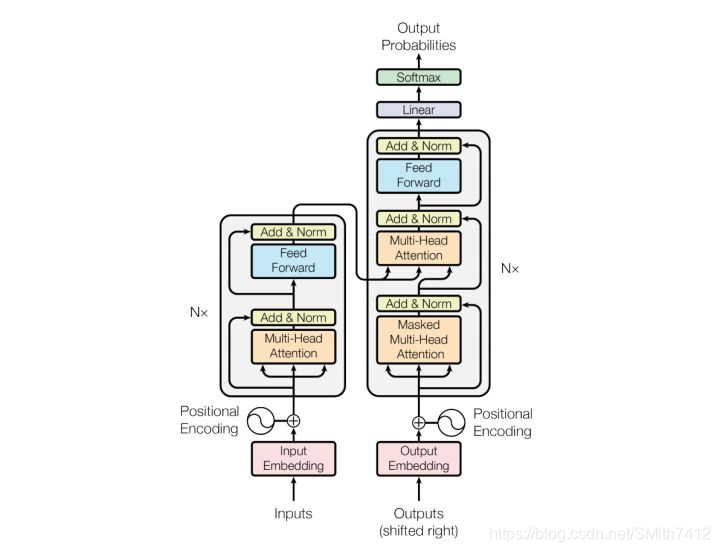
和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
1.1 Encoder
Encoder由N=6个相同的layer组成,layer指的就是上图左侧的单元,最左边有个“Nx”,这里是x6个。每个Layer由两个sub-layer组成,分别是multi-head self-attention mechanism和fully connected feed-forward network。其中每个sub-layer都加了residual connection和normalisation,因此可以将sub-layer的输出表示为:
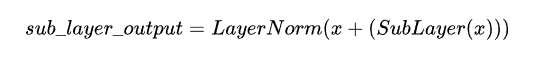
接下来按顺序解释一下这两个sub-layer:
Multi-head self-attention
熟悉attention原理的童鞋都知道,attention可由以下形式表示:
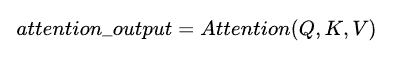
multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来: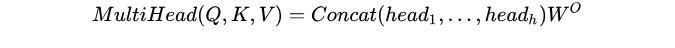
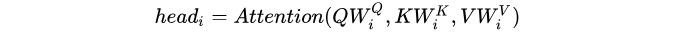
self-attention则是取Q,K,V相同。
另外,文章中attention的计算采用了scaled dot-product,即:
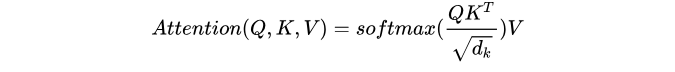
作者同样提到了另一种复杂度相似但计算方法additive attention,在 d_k 很小的时候和dot-product结果相似,d_k大的时候,如果不进行缩放则表现更好,但dot-product的计算速度更快,进行缩放后可减少影响(由于softmax使梯度过小,具体可见论文中的引用)。
Position-wise feed-forward networks
第二个sub-layer是个全连接层,之所以是position-wise是因为处理的attention输出是某一个位置i的attention输出。
1.2 Decoder
Decoder和Encoder的结构差不多,但是多了一个attention的sub-layer,这里先明确一下decoder的输入输出和解码过程:
输出:对应i位置的输出词的概率分布
输入:encoder的输出 & 对应i-1位置decoder的输出。所以中间的attention不是self-attention,它的K,V来自encoder,Q来自上一位置decoder的输出
解码:这里要特别注意一下,编码可以并行计算,一次性全部encoding出来,但解码不是一次把所有序列解出来的,而是像rnn一样一个一个解出来的,因为要用上一个位置的输入当作attention的query
明确了解码过程之后最上面的图就很好懂了,这里主要的不同就是新加的另外要说一下新加的attention多加了一个mask,因为训练时的output都是ground truth,这样可以确保预测第i个位置时不会接触到未来的信息。
加了mask的attention原理如图(另附multi-head attention):
1.3 Positional Encoding
除了主要的Encoder和Decoder,还有数据预处理的部分。Transformer抛弃了RNN,而RNN最大的优点就是在时间序列上对数据的抽象,所以文章中作者提出两种Positional Encoding的方法,将encoding后的数据与embedding数据求和,加入了相对位置信息。
这里作者提到了两种方法:
用不同频率的sine和cosine函数直接计算
学习出一份positional embedding(参考文献)
经过实验发现两者的结果一样,所以最后选择了第一种方法,公式如下: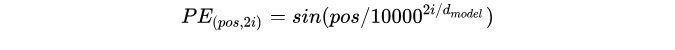
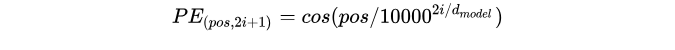
作者提到,方法1的好处有两点:

2. 如果是学习到的positional embedding,(个人认为,没看论文)会像词向量一样受限于词典大小。也就是只能学习到“位置2对应的向量是(1,1,1,2)”这样的表示。所以用三角公式明显不受序列长度的限制,也就是可以对 比所遇到序列的更长的序列 进行表示。
2. 优点
作者主要讲了以下三点:
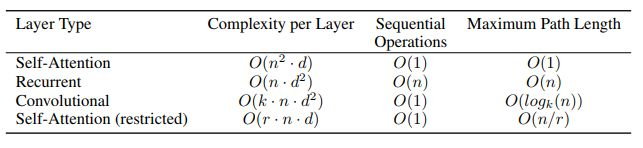
Total computational complexity per layer (每层计算复杂度)
2. Amount of computation that can be parallelized, as mesured by the minimum number of sequential operations required
作者用最小的序列化运算来测量可以被并行化的计算。也就是说对于某个序列x_1, x_2, …, x_n ,self-attention可以直接计算 x_i, x_j 的点乘结果,而rnn就必须按照顺序从 x_1 计算到 x_n
- Path length between long-range dependencies in the network
这里Path length指的是要计算一个序列长度为n的信息要经过的路径长度。cnn需要增加卷积层数来扩大视野,rnn需要从1到n逐个进行计算,而self-attention只需要一步矩阵计算就可以。所以也可以看出,self-attention可以比rnn更好地解决长时依赖问题。当然如果计算量太大,比如序列长度n>序列维度d这种情况,也可以用窗口限制self-attention的计算数量
- 另外,从作者在附录中给出的栗子可以看出,self-attention模型更可解释,attention结果的分布表明了该模型学习到了一些语法和语义信息
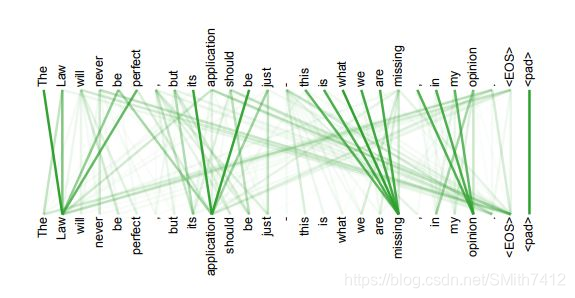
3. 缺点
缺点在原文中没有提到,是后来在Universal Transformers中指出的,在这里加一下吧,主要是两点:
实践上:有些rnn轻易可以解决的问题transformer没做到,比如复制string,尤其是碰到比训练时的sequence更长的时
理论上:transformers非computationally universal(图灵完备),(我认为)因为无法实现“while”循环
4. 总结
Transformer是第一个用纯attention搭建的模型,不仅计算速度更快,在翻译任务上也获得了更好的结果。Google现在的翻译应该是在此基础上做的,但是请教了一两个朋友,得到的答案是主要看数据量,数据量大可能用transformer好一些,小的话还是继续用rnn-based model
以上来自:https://zhuanlan.zhihu.com/p/44121378
BERT
BERT (Bidirectional Encoder Representations from Transformers)
10月11日,Google AI Language 发布了论文
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
提出的 BERT 模型在 11 个 NLP 任务上的表现刷新了记录,包括问答 Question Answering (SQuAD v1.1),推理 Natural Language Inference (MNLI) 等:
让我们先来看一下 BERT 在 Stanford Question Answering Dataset (SQuAD) 上面的排行榜吧:
https://rajpurkar.github.io/SQuAD-explorer/
BERT 可以用来干什么?
BERT 可以用于问答系统,情感分析,垃圾邮件过滤,命名实体识别,文档聚类等任务中,作为这些任务的基础设施即语言模型,
BERT 的代码也已经开源:
https://github.com/google-research/bert
我们可以对其进行微调,将它应用于我们的目标任务中,BERT 的微调训练也是快而且简单的。
例如在 NER 问题上,BERT 语言模型已经经过 100 多种语言的预训练,这个是 top 100 语言的列表:
https://github.com/google-research/bert/blob/master/multilingual.md
只要在这 100 种语言中,如果有 NER 数据,就可以很快地训练 NER。
BERT 原理简述
BERT 的创新点在于它将双向 Transformer 用于语言模型,
之前的模型是从左向右输入一个文本序列,或者将 left-to-right 和 right-to-left 的训练结合起来。
实验的结果表明,双向训练的语言模型对语境的理解会比单向的语言模型更深刻,
论文中介绍了一种新技术叫做 Masked LM(MLM),在这个技术出现之前是无法进行双向语言模型训练的。
BERT 利用了 Transformer 的 encoder 部分。
Transformer 是一种注意力机制,可以学习文本中单词之间的上下文关系的。
Transformer 的原型包括两个独立的机制,一个 encoder 负责接收文本作为输入,一个 decoder 负责预测任务的结果。
BERT 的目标是生成语言模型,所以只需要 encoder 机制。
Transformer 的 encoder 是一次性读取整个文本序列,而不是从左到右或从右到左地按顺序读取,
这个特征使得模型能够基于单词的两侧学习,相当于是一个双向的功能。
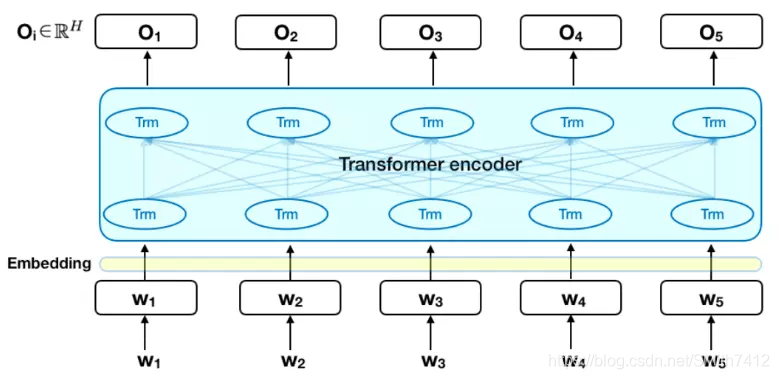
下图是 Transformer 的 encoder 部分,输入是一个 token 序列,先对其进行 embedding 称为向量,然后输入给神经网络,输出是大小为 H 的向量序列,每个向量对应着具有相同索引的 token。
当我们在训练语言模型时,有一个挑战就是要定义一个预测目标,很多模型在一个序列中预测下一个单词,
“The child came home from ___”
双向的方法在这样的任务中是有限制的,为了克服这个问题,BERT 使用两个策略:
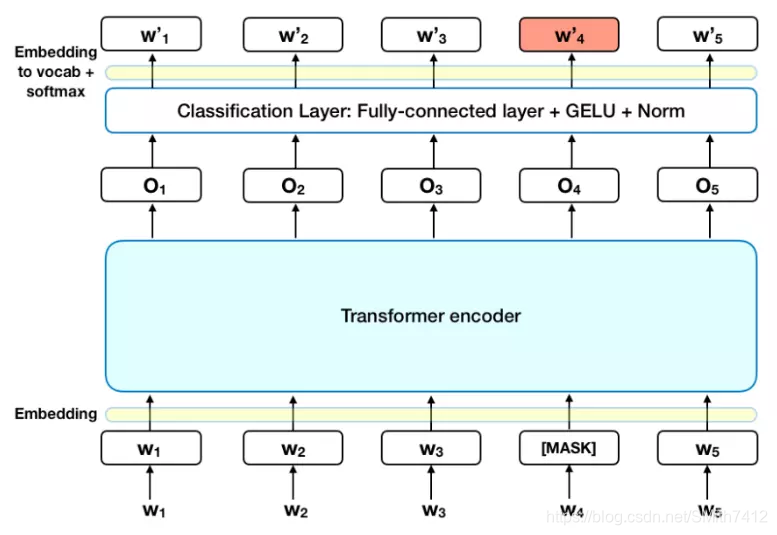
1. Masked LM (MLM)
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。 然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被掩盖的原单词。
这样就需要:
在 encoder 的输出上添加一个分类层
用嵌入矩阵乘以输出向量,将其转换为词汇的维度
用 softmax 计算词汇表中每个单词的概率
BERT 的损失函数只考虑了 mask 的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。
2. Next Sentence Prediction (NSP)
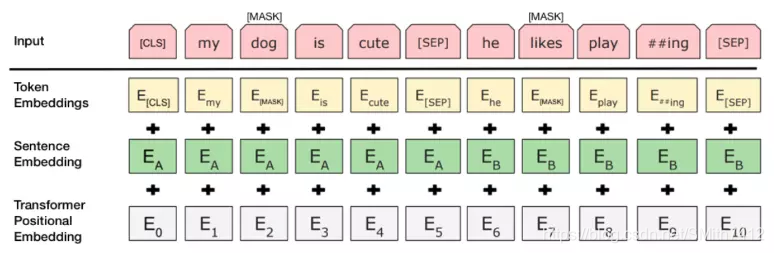
在 BERT 的训练过程中,模型接收成对的句子作为输入,并且预测其中第二个句子是否在原始文档中也是后续句子。
在训练期间,50% 的输入对在原始文档中是前后关系,另外 50% 中是从语料库中随机组成的,并且是与第一句断开的。
为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:
在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。
将表示句子 A 或句子 B 的一个句子 embedding 添加到每个 token 上。
给每个 token 添加一个位置 embedding,来表示它在序列中的位置。
为了预测第二个句子是否是第一个句子的后续句子,用下面几个步骤来预测:
整个输入序列输入给 Transformer 模型
用一个简单的分类层将 [CLS] 标记的输出变换为 2×1 形状的向量
用 softmax 计算 IsNextSequence 的概率
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
如何使用 BERT?
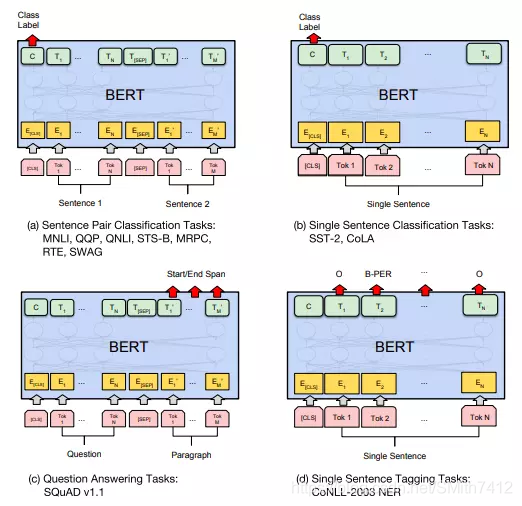
BERT 可以用于各种NLP任务,只需在核心模型中添加一个层,例如:
在分类任务中,例如情感分析等,只需要在 Transformer 的输出之上加一个分类层
在问答任务(例如SQUAD v1.1)中,问答系统需要接收有关文本序列的 question,并且需要在序列中标记 answer。 可以使用 BERT 学习两个标记 answer 开始和结尾的向量来训练Q&A模型。
在命名实体识别(NER)中,系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。 可以用 BERT 将每个 token 的输出向量送到预测 NER 标签的分类层。
在 fine-tuning 中,大多数超参数可以保持与 BERT 相同,在论文中还给出了需要调整的超参数的具体指导(第3.5节)。
参考自:https://www.jianshu.com/p/d110d0c13063
更多参考:
1、transformer github实现:https://github.com/Kyubyong/transformer
2、transformer pytorch分步实现:http://nlp.seas.harvard.edu/2018/04/03/attention.html
3、搞懂Transformer结构,看这篇PyTorch实现就够了:https://www.tinymind.cn/articles/3834
4、“变形金刚”为何强大:从模型到代码全面解析Google Tensor2Tensor系统:https://segmentfault.com/a/1190000015575985
bert:
5、bert系列1:https://medium.com/dissecting-bert/dissecting-bert-part-1-d3c3d495cdb3
6、bert系列2:https://medium.com/dissecting-bert/dissecting-bert-part2-335ff2ed9c73
7、bert系列3:https://medium.com/dissecting-bert/dissecting-bert-appendix-the-decoder-3b86f66b0e5f
8、5 分钟入门 Google 最强NLP模型:BERT:https://www.jianshu.com/p/d110d0c13063
9、BERT – https://www.lyrn.ai/2018/11/07/explained-bert-state-of-the-art-language-model-for-nlp/
10、google开源代码:https://github.com/google-research/bert
bert实践:
干货 BERT fine-tune 终极实践教程:干货 | BERT fine-tune 终极实践教程 - 简书
小数据福音!BERT在极小数据下带来显著提升的开源实现:小数据福音!BERT在极小数据下带来显著提升的开源实现
BERT实战(源码分析+踩坑):BERT实战(源码分析 踩坑) - 知乎
