python爬虫实战之异步爬取数据
前言
python中异步编程的主要三种方法:回调函数、生成器函数、线程大法。
以进程、线程、协程、函数/方法作为执行任务程序的基本单位,结合回调、事件循环、信号量等机制,以提高程序整体执行效率和并发能力的编程方式。
如果在某程序的运行时,能根据已经执行的指令准确判断它接下来要进行哪个具体操作,那它是同步程序,反之则为异步程序。(无序与有序的区别)
同步/异步、阻塞/非阻塞并非水火不容,要看讨论的程序所处的封装级别。例如购物程序在处理多个用户的浏览请求可以是异步的,而更新库存时必须是同步的。
优点:异步操作无须额外的线程开销,并且使用回调的方式进行处理。在设计良好的情况下,处理函数可以不必使用共享变量(即使无法完全不使用共享变量,至少可以减少共享变量的数量),减少了死锁的可能性。
缺点:异步编程复杂度较高,且难以调试。最大的问题在于回调,这增加了软件上的设计难度
一、需求
- 使用 asyncio 和 aiohttp 模块来异步爬取数据
- 控制异步的并发量
- 爬取页面的数据
二、使用步骤
1.思路
- 访问网站分析要爬取的数据
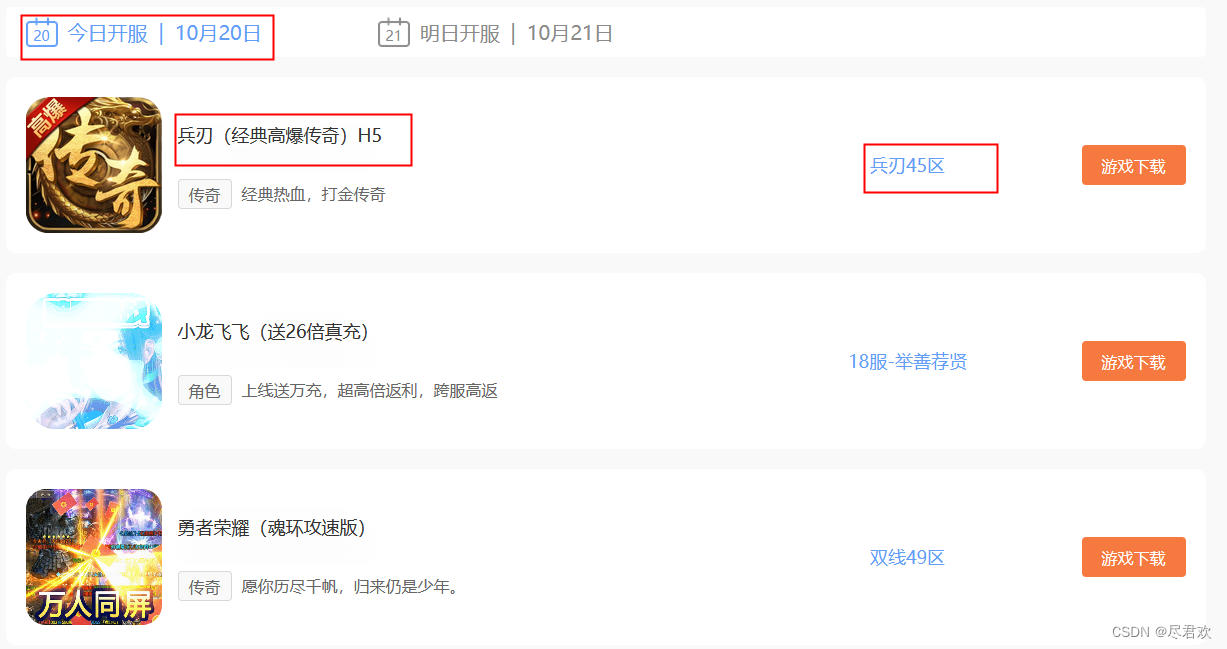
- 通过异步来实现一次访问所有要爬取的页面来获取数据
- 设置一个控制异步一次访问的数据
代码如下(示例):
2.引入库
代码如下(示例):
import asyncio
import aiohttp
import json
import time
import requests
import re
from lxml import etree
import datetime
3.代码如下
代码如下(示例):
import asyncio
import aiohttp
import json
import time
import requests
import re
from lxml import etree
import datetime
CONCURRENCY = 5
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
# URL = 'http://127.0.0.1:30328'
# asyncio 的 Semaphore 来控制并发量
semaphore = asyncio.Semaphore(CONCURRENCY)
url_3011 = 'xxxx'
response_3011 = requests.get(
url='xxxx', headers=headers)
HTML_1 = etree.HTML(response_3011.text)
# 数据列表
json_data_list = []
tasks = []
async def scrape_api(session, URL):
# 控制并发量
async with semaphore:
# print('scraping', URL)
# 请求网站,获取html代码和状态码
async with session.get(URL, headers=headers) as response:
await asyncio.sleep(1)
# 关闭会话
# await session.close()
return await response.text()
async def session_url(url):
# 设置超时
timeout = aiohttp.ClientTimeout(total=7)
# 用 with as 可以自动关闭会话
# 请求库由 requests 改成了 aiohttp,通过 aiohttp 的 ClientSession 类的 get 方法进行请求
async with aiohttp.ClientSession(timeout=timeout) as session:
html = await scrape_api(session, url)
print('scraping', url)
pages_1 = etree.HTML(html)
for b in pages_1.xpath('/html/body/div[2]/div[3]/ul/li'):
game_name = b.xpath('div[2]/div[1]/a/text()')[0]
service = b.xpath('div[3]/text()')[0].strip()
print({
"game": game_name, "server": service,
"mobile": "安卓", "time": timestamp})
json_data_list.append(
{
"game": game_name, "server": service, "mobile": "安卓", "time": timestamp})
def url_list():
for number1, day in enumerate(HTML_1.xpath('/html/body/div[2]/div[2]/div'), 1):
day1 = day.xpath('a/div[1]/text()')[0]
# 转换成时间数组
timeArray = time.strptime(str(datetime.datetime.now().year) + '-' + str(
datetime.datetime.now().month) + '-' + str(day1) + ' ' + '00:00:00', "%Y-%m-%d %H:%M:%S")
# 转换成时间戳
global timestamp
timestamp = int(time.mktime(timeArray))*1000
urls = ('https://www.3011.cn/server/%s/1.html' % (number1))
response_3011_page = requests.get(url=urls, headers=headers)
pattern_page = r'<li>共(\d+)页</li>'
pages = re.findall(pattern_page, response_3011_page.text, re.S)[0]
for a in range(1, int(pages)+1):
# 生成访问链接
urls_1 = ('https://www.3011.cn/server/%s/%s.html' % (number1, a))
yield urls_1
async def main():
scrape_index_tasks = []
for url1 in url_list():
# ensure_future 方法,返回结果也是 task 对象,这样的话我们就可以不借助 loop 来定义
scrape_index_tasks.append(asyncio.ensure_future(session_url(url1)))
# 声明了 10000 个 task,将其传递给 gather 方法运行,已经生成的任务
await asyncio.gather(*scrape_index_tasks)
# scrape_index_tasks = [asyncio.ensure_future(scrape_api()) for _ in range(10000)]
# 声明了 10000 个 task,将其传递给 gather 方法运行
# await asyncio.gather(*scrape_index_tasks)
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
总结
以上就是今天要讲的内容,本文仅仅简单介绍了asyncio 和 aiohttp的使用,通过使用这两个模块可以大大提高爬虫的速度。