小白学习:
转:https://zhuanlan.zhihu.com/p/26885412
1.cmd下
scrapy startproject 项目名
2.我一般都是在pycharm中编写代码,所以我会在idea中引入项目,这里不知道如何在pycharm中下载scrapy模块的童鞋,可看我前面的博客:
进入文件下
scrapy genspider 文件名 爬取的网站 scrapy genspider SZtianqi suzhou.tianqi.com会在文件夹下生成一个SZtianqi的文件
3.编写items.py这个文件,是我们想要封装的名字,在这里面定义
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
#我们将我们需要的名字加进去
class WeatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
date=scrapy.Field();#时间
week=scrapy.Field();#日期
img=scrapy.Field();#照片地址
temperature=scrapy.Field();#温度
weather=scrapy.Field();#天气
wind=scrapy.Field();#风速
4.编写SZtianqi.py:作用的从网站上抓取数据,这里和之前的get_html的方法一致,将网页的数据筛取存入item中
# -*- coding: utf-8 -*-
import scrapy
from weather.items import WeatherItem
class SztianqiSpider(scrapy.Spider):
name = "SZtianqi"
# 我们修改一下host,使得Scrapy可以爬取除了苏州之外的天气
allowed_domains = ["tianqi.com"]
# 建立需要爬取信息的url列表
start_urls = []
# 需要爬的城市名称
citys = ['nanjing', 'suzhou', 'shanghai']
# 用一个很简答的循环来生成需要爬的链接:
for city in citys:
start_urls.append('http://' + city + '.tianqi.com')
def parse(self, response):
'''
筛选信息的函数:
date = 今日日期
week = 星期几
img = 表示天气的图标
temperature = 当天的温度
weather = 当天的天气
wind = 当天的风向
'''
# 先建立一个列表,用来保存每天的信息
items = []
# 找到包裹着每天天气信息的div
sixday = response.xpath('//div[@class="tqshow1"]')
# 循环筛选出每天的信息:
for day in sixday:
# 先申请一个weatheritem 的类型来保存结果
item = WeatherItem()
# 观察网页,知道h3标签下的不单单是一行str,我们用trick的方式将它连接起来
date = ''
for datetitle in day.xpath('./h3//text()').extract():
date += datetitle
item['date'] = date
item['week'] = day.xpath('./p//text()').extract()[0]
item['img'] = day.xpath(
'./ul/li[@class="tqpng"]/img/@src').extract()[0]
tq = day.xpath('./ul/li[2]//text()').extract()
# 我们用第二种取巧的方式,将tq里找到的str连接
item['temperature'] = ''.join(tq)
item['weather'] = day.xpath('./ul/li[3]/text()').extract()[0]
item['wind'] = day.xpath('./ul/li[4]/text()').extract()[0]
items.append(item)
return items
这里面的
from weather.items import WeatherItem
是引入items.py的一个类,用与封装的
5.处理封装好的item对象,编写pipelins.py:作用的将数据存入本地或数据库
# -*- coding: utf-8 -*-
import os
import requests
import json
import codecs
import pymysql
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
'''
我们知道,pipelines.py是用来处理收尾爬虫抓到的数据的,
一般情况下,我们会将数据存到本地:
文本形式: 最基本的方式
json格式 :方便其他程序员调用
数据库: 数据量多时
'''
#写入txt文件
class WeatherPipeline(object):
def process_item(self, item, spider):
'''
处理每一个从SZtianqi传过来的
item
'''
#获取当前的工作目录
basc_dir=os.getcwd();
#把文件保存到data目录下
filename=basc_dir+'\\weather\\data\\weather.txt'
#已追加的方式打开文件并写入对应的信息
with open(filename,'a',encoding='utf-8') as f:
f.write(item['date']+'\n')
f.write(item['week']+'\n')
f.write(item['temperature']+'\n')
f.write(item['wind']+'\n')
f.write(item['weather']+'\n')
f.write(item['img']+'\n')
#下载图片
file_img=basc_dir+'\\weather\\data\\image\\'+item['date']+'.png'
with open(file_img,'wb') as f:
f.write(requests.get(item['img']).content)
#print('aaaaaaaaaaaaaaaaaaaaaaaaa')
return item
#写入json文件
class W2json(object):
def process_item(self, item, spider):
#获取本地文件
basc_dir=os.getcwd();
json_dir=basc_dir+'\\weather\\data\\weather.json'
# 打开json文件,向里面以dumps的方式吸入数据
# 注意需要有一个参数ensure_ascii=False ,不然数据会直接为utf编码的方式存入比如:“/xe15”
with codecs.open(json_dir,'a',encoding='utf-8') as f:
line=json.dumps(dict(item),ensure_ascii=False)+'\n'
f.write(line)
return item
#将数据存入数据库
class Rmysql(object):
def process_item(self, item, spider):
#抓取数据存入mysql
#将数据从item中拿出来
date=item['date'];
week=item['week'];
img=item['img']
temperature=item['temperature']
weather=item['weather']
wind=item['wind']
#和本地的数据库连接起来
connection=pymysql.connect(
host='localhost', # 连接的是本地数据库
user='root', # 自己的mysql用户名
passwd='123456', # 自己的密码
db='scrapyDB', # 数据库的名字
charset='utf8mb4', # 默认的编码方式:
cursorclass=pymysql.cursors.DictCursor)
#插库
try:
with connection.cursor() as cursor:
#创建更新数据库的sql
sql="""INSERT INTO WEATHER(date,week,img,temperature,weather,wind)
VALUES (%s, %s,%s,%s,%s,%s)"""
#执行sql
cursor.execute(sql,(date,week,img,temperature,weather,wind))
#提交插入数据
connection.commit()
finally:
#关闭资源 的第二个参数可以将sql缺省语句补全,一般以元组的格式
connection.close()
return item
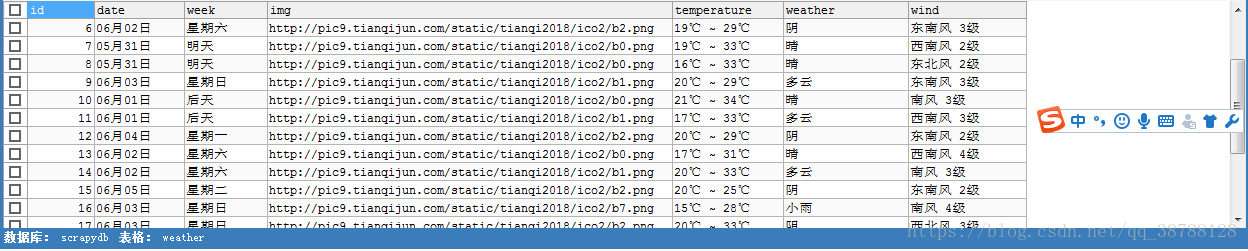
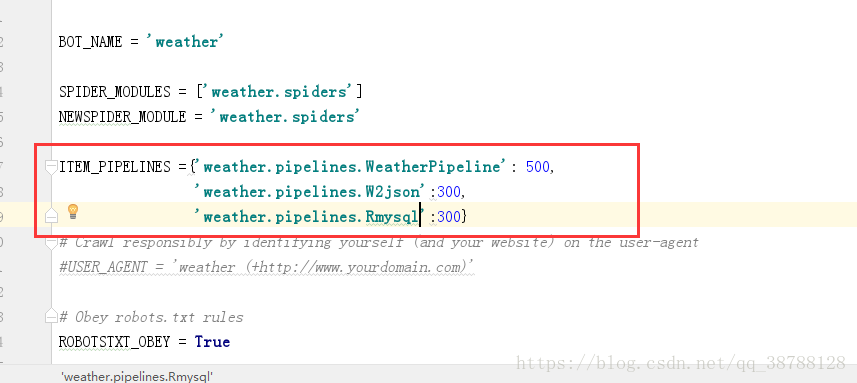
6.在settings中,调用pipelines的方法
7.执行项目
scrapy crawl SZtianqi
在编写代码是可一边测试一边编写从终端看结果
数据库结果