1/准备环节
先准备好几台服务器,最少3台。
确定好哪台是master节点,剩下的是slave节点(worker节点).
设置好master节点到其他work节点的ssh无密码登陆,这需要所有机器上有相同的用户账号。
如何实现ssh无密码登陆?
把master节点的.ssh/id_das.pub文件的内容写入到每台worker节点的.ssh/authorized_keys文件中
具体实现步骤:
<1>在主节点master上:运行ssh-keygen并接受默认选项
$ ssh-keygen -t dsa
Enter file in which to save the key (/home/you/.ssh/id_dsa): [回车]
Enter passphrase (empty for no passphrase): [空]
Enter same passphrase again: [空]
<2>在工作节点worker上:
# 把主节点的~/.ssh/id_dsa.pub文件复制到工作节点上,然后使用:
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
复制代码
2/登录到master节点服务器(以下所有操作都是在master节点上操作的)
<1>到官网下载spark安装包(确定操作系统和版本号),并且上传到master节点服务器
<2>解压
tar -zxvf spark-2.3.1-bin-hadoop2.6.tgz
复制代码
<3>更改文件名(改名或者不改其实都可以)
mv spark-2.3.1-bin-hadoop2.6 spark-2.3.1
复制代码
<4>cd到安装包的conf目录下,修改slaves.template文件
cd spark-2.3.1
mv slaves.template slaves
复制代码
<5>打开<4>中修改的文件slaves,添加集群中节点的主机名
vi slaves
然后添加主机名,如下所示,一行添加一个(该文件中,包含master节点的主机名)
node1
node2
node3
复制代码
<6>修改spark-env.sh.template 文件名为 spark-env.sh,然后编辑spark-env.sh文件
mv spark-env.sh.template spark-env.sh
填写如下内容
JAVA_HOME:配置java_home路径
SPARK_MASTER_HOST:master的ip
SPARK_MASTER_PORT:提交任务的端口,默认是7077
SPARK_WORKER_CORES:每个worker从节点能够支配的core的个数
SPARK_WORKER_MEMORY:每个worker从节点能够支配的内存数
复制代码
<7>把master节点上的spark安装包,同步到其他的worker节点
scp -r spark-2.3.1 node2:`pwd`
scp -r spark-2.3.1 node3:`pwd`
注意:worker节点存放spark安装包的路径要和master节点一样。
复制代码
<8>进入sbin目录下,执行当前目录下的./start-all.sh
注意:在主节点上运行sbin/start-all.sh(要在主节点上运行而不是在工作节点上)以启动集群。
要停止集群,在主节点上运行sbin/stop-all.sh
复制代码
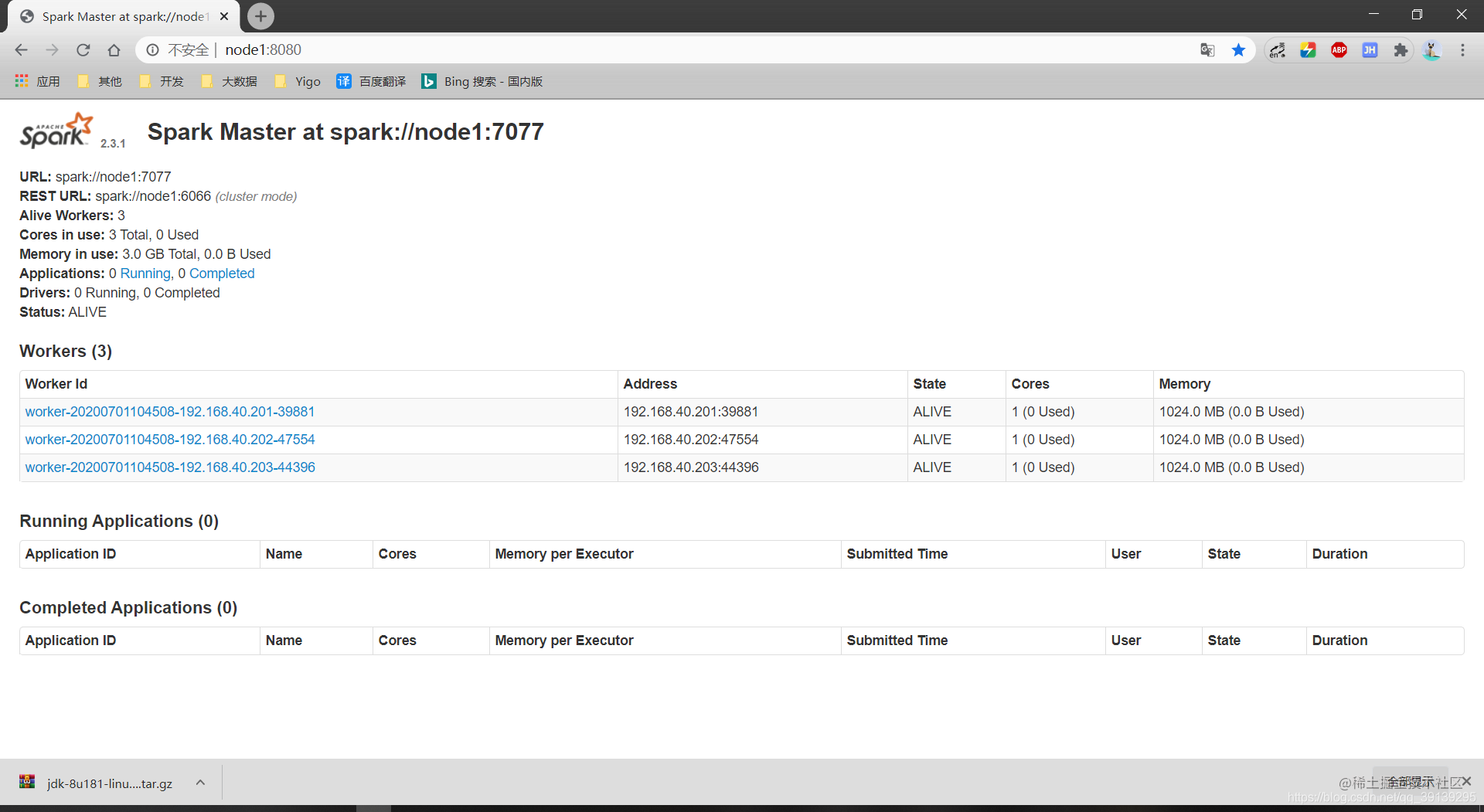
<9>访问master:8080端口