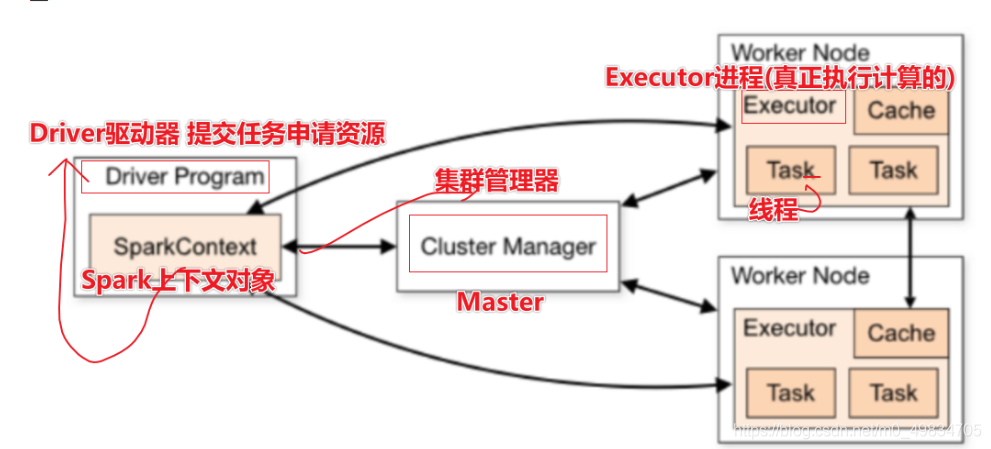
简介: Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
- Standalone集群使用了分布式计算中的master-slave模型,master是集群中含有Master进程的节点,slave是集群中的Worker节点含有Executor进程。
官网链介绍: http://spark.apache.org/docs/latest/cluster-overview.html

- Spark Standalone集群,类似Hadoop YARN,管理集群资源和调度资源:
- 主节点Master:管理整个集群资源,接收提交应用,分配资源给每个应用,运行Task任务
- 从节点Workers: 1) 管理每个机器的资源(CPU资源 + 内存资源),分配对应的资源来运行Task 2) 每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数
- 历史服务器HistoryServer(可选): Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。
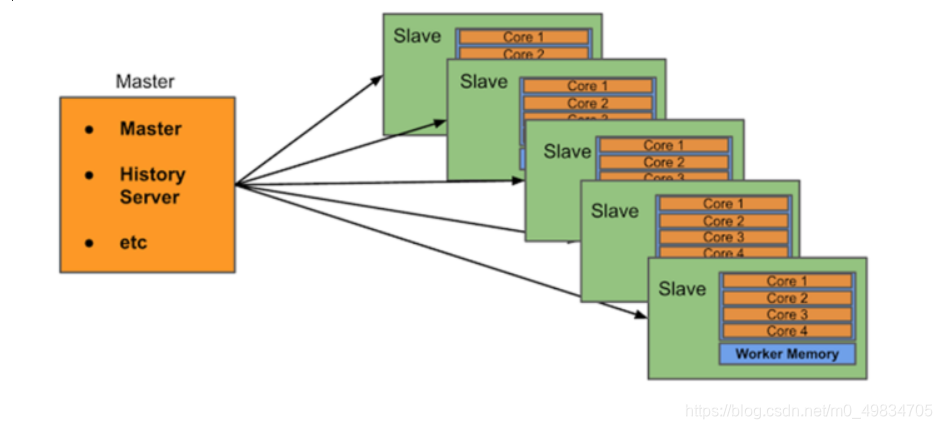
我本次搭建的集群规划:
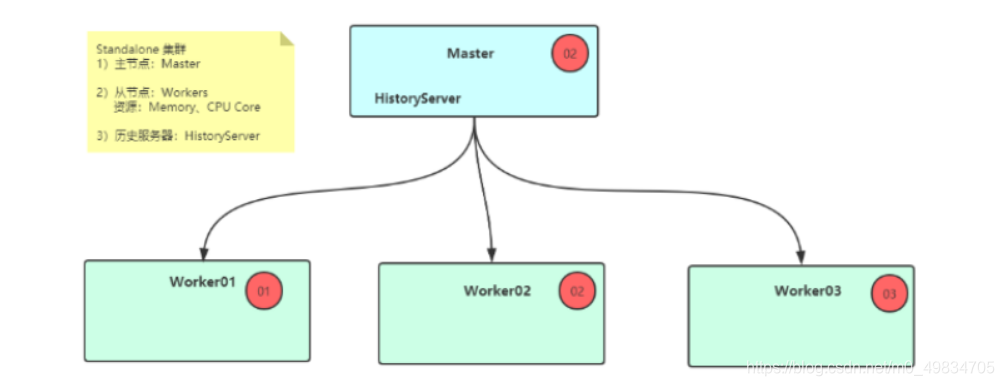
Standalone集群安装服务规划与资源配置:
node01:master/worker
node02:slave/worker
node03:slave/worker
官方文档:http://spark.apache.org/docs/2.4.5/spark-standalone.html
步骤:
- 1-修改slaves
进入配置目录
cd /export/server/spark/conf
修改配置文件名称
mv slaves.template slaves
vim slaves
内容如下:
node1
node2
node3
- 2-修改spark-env.sh
进入配置目录
cd /export/server/spark/conf
修改配置文件名称
mv spark-env.sh.template spark-env.sh
修改配置文件
vim spark-env.sh
增加如下内容:
## 设置JAVA安装目录
JAVA_HOME=/export/server/jdk #改成自己的JDK目录 看自己JDK配置的环境变量
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
export SPARK_MASTER_HOST=node1 #主机名
export SPARK_MASTER_PORT=7077 #通信端口
SPARK_MASTER_WEBUI_PORT=8080 #webUI端口
SPARK_WORKER_CORES=1 #CPU核数
SPARK_WORKER_MEMORY=1g #内存
SPARK_WORKER_PORT=7078 #通信端口
SPARK_WORKER_WEBUI_PORT=8081 #webUI端口
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true" #sparklog需要自己创建
- 3-创建EventLogs存储目录
启动HDFS服务,创建应用运行事件日志目录,命令如下:
hdfs dfs -mkdir -p /sparklog/
- 4-配置Spark应用保存EventLogs
## 进入配置目录 对于历史服务器的设置
cd /export/server/spark/conf
## 修改配置文件名称 将【$SPARK_HOME/conf/spark-defaults.conf.template】名称命名为【spark-defaults.conf】
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
## 添加内容如下:
spark.eventLog.enabled true #log是否可以用
spark.eventLog.dir hdfs://node1:8020/sparklog/ #目录是哪一个
spark.eventLog.compress true #是否启动压缩
- 5-设置日志级别
## 进入目录
cd /export/server/spark/conf
## 修改日志属性配置文件名称 将【$SPARK_HOME/conf/log4j.properties.template】名称命名为【log4j.properties】,修改级别为警告WARN。
mv log4j.properties.template log4j.properties
## 改变日志级别
vim log4j.properties
修改内容如下:

- 6-分发到其他机器
将配置好的将 Spark 安装包分发给集群中其它机器,命令如下:
cd /export/server/
scp -r spark-2.4.5-bin-hadoop2.7 root@node2:$PWD
scp -r spark-2.4.5-bin-hadoop2.7 root@node3:$PWD
##创建软连接
ln -s /export/server/spark-2.4.5-bin-hadoop2.7 /export/server/spark
到这里就搭建好啦 !!!
- 启动Spark
启动方式1:集群启动和停止
在主节点上启动spark集群
/export/server/spark/sbin/start-all.sh
在主节点上停止spark集群
/export/server/spark/sbin/stop-all.sh
启动方式2:单独启动和停止
在 master 安装节点上启动和停止 master:
start-master.sh
stop-master.sh
在 Master 所在节点上启动和停止worker(work指的是slaves 配置文件中的主机名)
start-slaves.sh
stop-slaves.sh
- WEB UI页面
http://node1:8080/
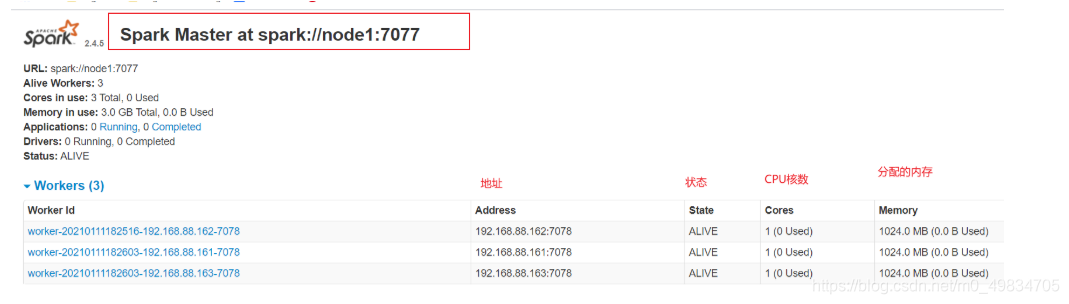
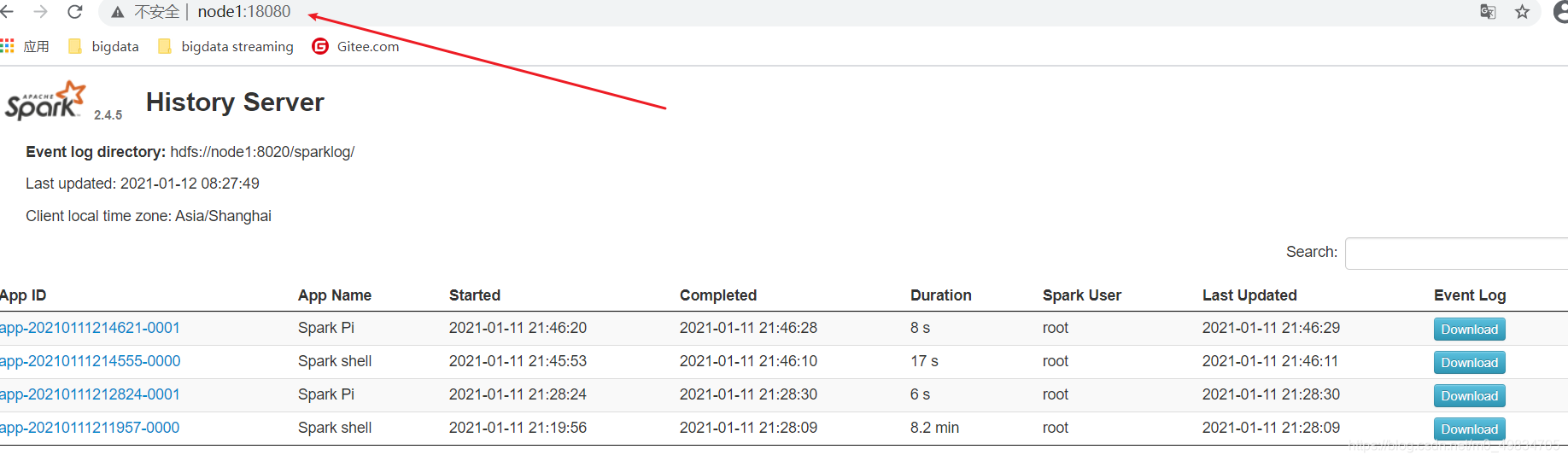
- 历史服务器HistoryServer:
/export/server/spark/sbin/start-history-server.sh
WEB UI页面地址:http://node1:18080
- StandAlone模式如何通过交互式命令写代码?
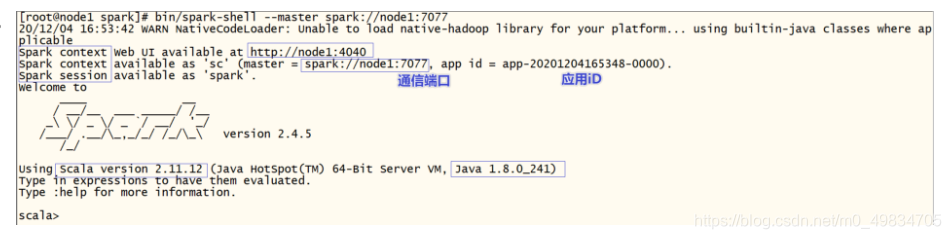
bin/spark-shell --master spark://node1:7077
wordcount案例:
sc.textFile("hdfs://node1:8020/wordcount/input/words.txt").flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_).collect
- Standalone模式应该如何提交任务
bin/spark-submit \
--master spark://node1:7077 \
--class org.apache.spark.examples.SparkPi \
/export/server/spark/examples/jars/spark-examples_2.11-2.4.5.jar \
10

- 补充: Driver 和Executors 图片