简介: Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF)的问题。
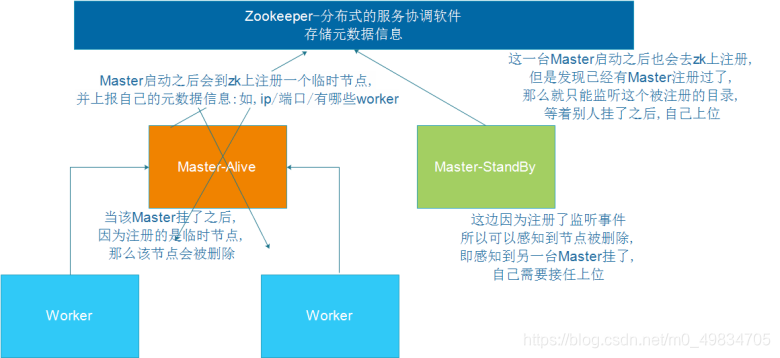
- StandaloneHA的模式: 本质是基于ZK做一个leader的选举
- 搭建过程: 基于前面的Standalone模式做一些配置文件的修改就行了
- 在node01上配置:
vim /export/server/spark/conf/spark-env.sh
注释或删除MASTER_HOST内容:
# SPARK_MASTER_HOST=node1
增加如下配置
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"
参数含义说明:
spark.deploy.recoveryMode:恢复模式
spark.deploy.zookeeper.url:ZooKeeper的Server地址
spark.deploy.zookeeper.dir:保存集群元数据信息的文件、目录。包括Worker、Driver、Application信息。
- 将spark-env.sh分发集群
cd /export/server/spark/conf
scp -r spark-env.sh root@node2:$PWD
scp -r spark-env.sh root@node3:$PWD
- 启动集群服务
启动ZOOKEEPER服务
zkServer.sh status
zkServer.sh stop
zkServer.sh start
node1上启动Spark集群执行
/export/server/spark/sbin/start-all.sh
在node2上再单独只起个master:
/export/server/spark/sbin/start-master.sh
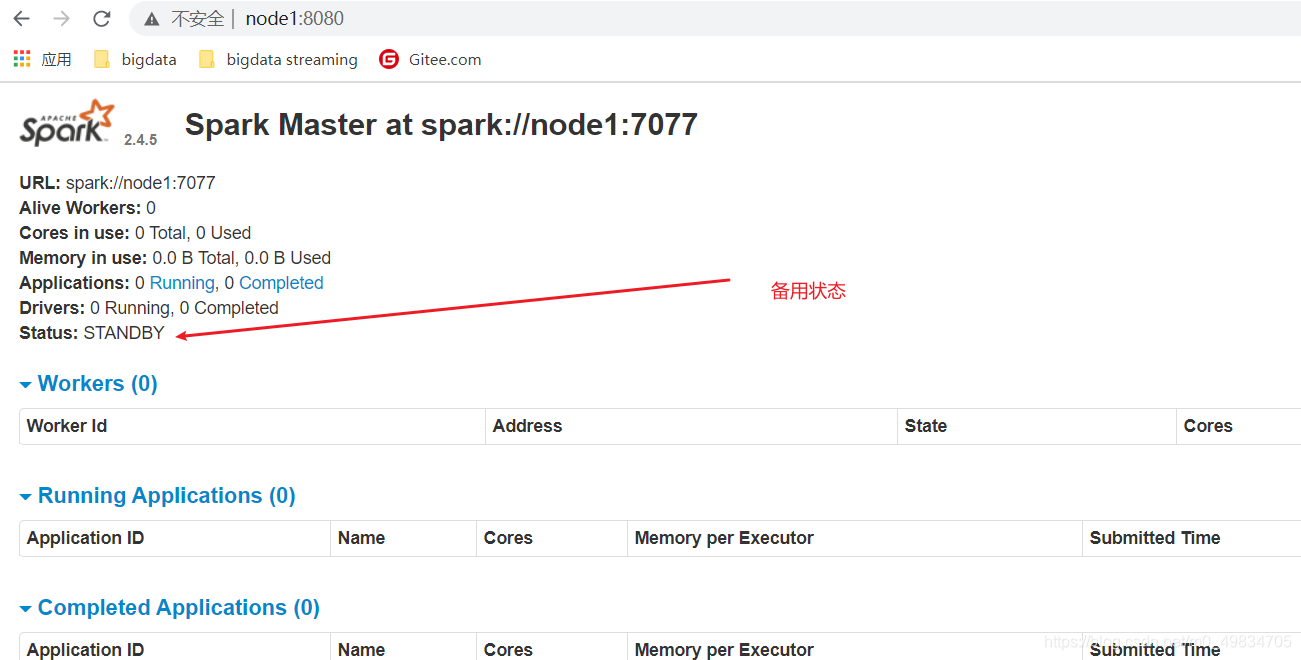
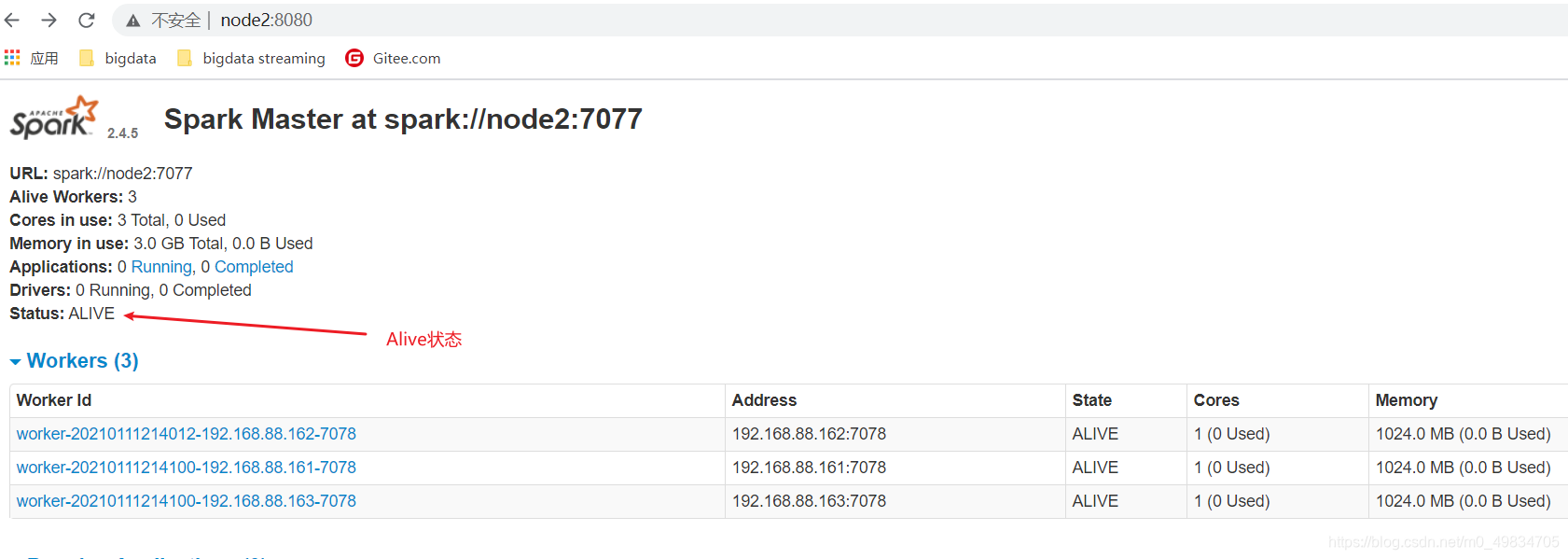
查看WebUI
http://node1:8080/
http://node2:8080/
- 完成搭建
测试:
- 使用SparkShell交互式命令行
bin/spark-shell --master spark://node1:7077,node2:7077
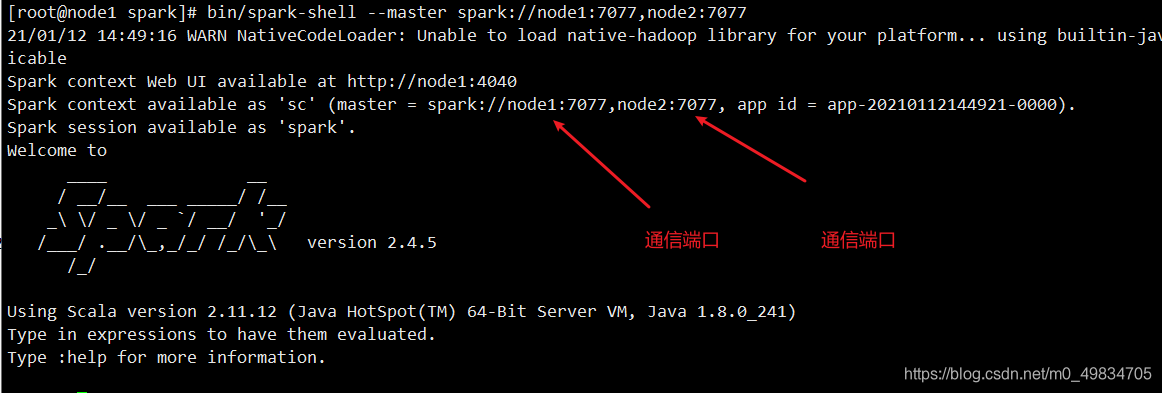
- wordcount测试:
sc.textFile("hdfs://node1:8020/wordcount/input/words.txt").flatMap(x=>x.split("\\s+")).map(x=>(x,1)).reduceByKey((a,b)=>a+b).collect
- 圆周率测试:
bin/spark-submit \
--master spark://node1:7077,node2:7077 \
--class org.apache.spark.examples.SparkPi \
/export/server/spark/examples/jars/spark-examples_2.11-2.4.5.jar \
10

- 验证HA模式:

效果 :
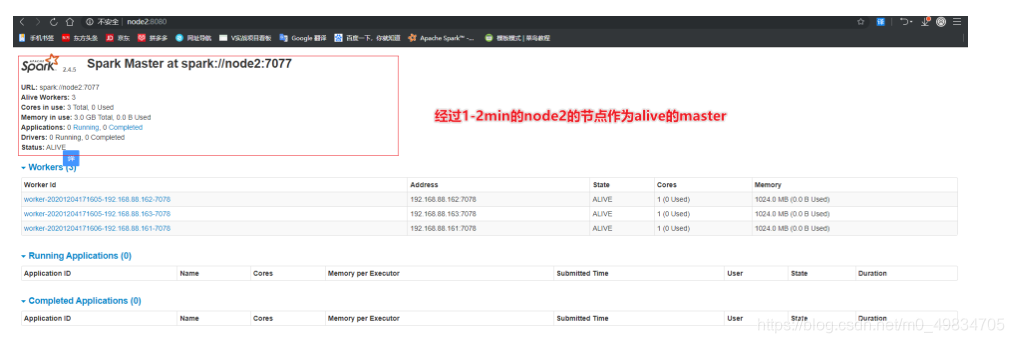
这里注意官网说的需要1-2min才可以从备用变成Alive状态