课程原地址:http://hbust.shiyanbar.com/course/91079
上课老师:李歆
实验时间:20180531
地点:云桌面
实验人:郭畅
实验目的
1) 熟悉spark集群搭建
2) 熟悉standalone运行模式
实验原理
spark基于standalone集群搭建,standalone是主从结构,分master,worker;app作业
首先,简单说明下Master、Worker、Application三种角色。
Application:带有自己需要的mem和cpu资源量,会在master里排队,最后被分发到worker上执行。app的启动是去各个worker遍历,获取可用的cpu,然后去各个worker launch executor。
Worker:每台slave起一个(也可以起多个),默认或被设置cpu和mem数,并在内存里做加减维护资源剩余量。Worker同时负责拉起本地的executor backend,即执行进程。
Master:接受Worker、app的注册,为app执行资源分配。Master和Worker本质上都是一个带Actor的进程
实验环境
jdk1.7.0_79+ scala-2.11.4+spark-1.6.1-bin-hadoop2.4
所需软件包都在/simple/soft目录下
实验步骤
一、Spark安装准备
1.1 解压安装包。在命令终端切换到/simple目录下,分别执行如下命令:
tar –zxvf /simple/soft/scala-2.11.4.tgz
tar –zxvf /simple/soft/spark-1.6.1-bin-hadoop2.4.tgz
解压后如下图1所示:
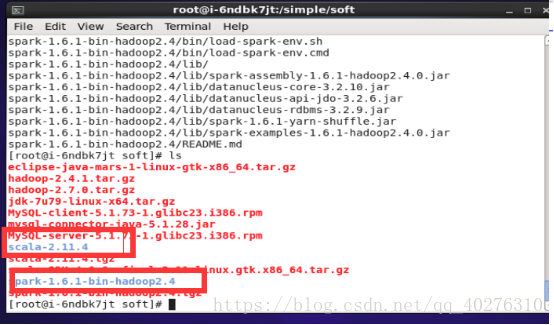
图1
1.2 环境变量配置。在任意目录下执行命令:vim /etc/profile编辑配置文件。如图2所示。要配置的参数由红框选中的内容。

图2
1.3 环境变量配置文件生效,执行命令:source /etc/profile。如图3所示

图3
1.4 查看本机IP,在任意目录下执行命令:ifconfig查看网卡信息。,如下图4所示,红色标记的为本节点ip。

图4
二、spark集群配置
2.1 切换至spark安装目录下的conf文件并执行命令:ls查看所有配置文件,并执行复制文件spark-env.sh.template和slaves.template命令生成spark-env.sh和slaves文件。如图5所示
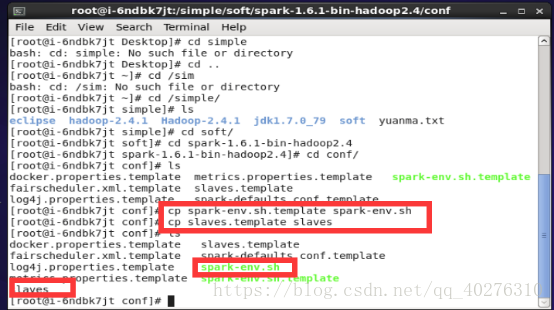
图5
2.2 配置spark-env.sh。在conf目录下执行命令:vim spark-env.sh并编辑其中内容(IP以实际主机IP为准),如图6所示

图6
2.3 配置slaves。在conf目录下执行命令:vim slaves并编辑其中内容,输入内容spark02。如图7所示 注:主机名随实际情况而定

图7
2.4 启动集群,首先切换到目录:cd /simple/spark-1.6.1-bin-hadoop2.4/sbin
执行启动脚本:./start-all.sh并查看spark进程。如图8所示
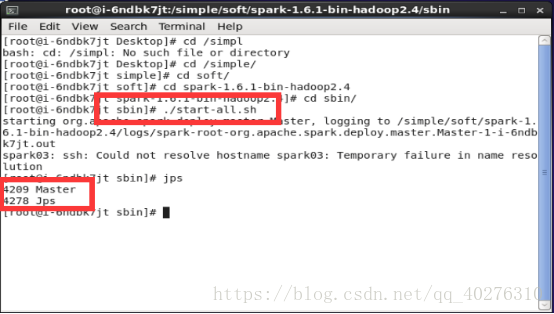
图8
2.5 集群启动是否成功,启动浏览器并输入地址(主机名以实际虚拟机主机名为主),如图9所示,显示部署成功。
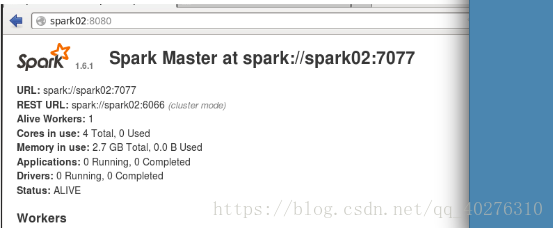
图9