Python爬取全球COVID-19当日数据(网易版)
了解数据结构(右键检查–>Network–>XHR–>Ctrl+R):
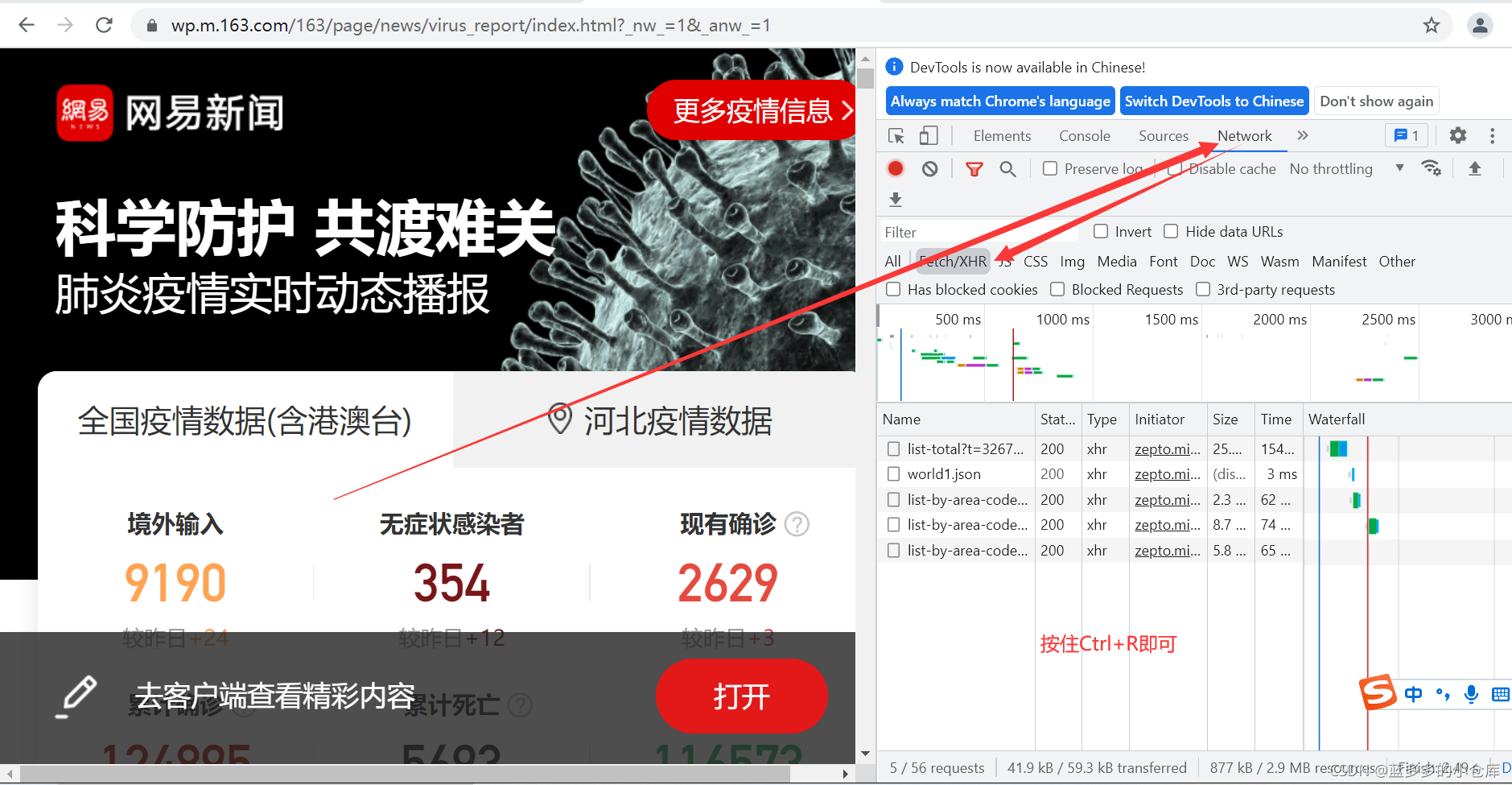
如箭头所示,我们需要的数据在这里:
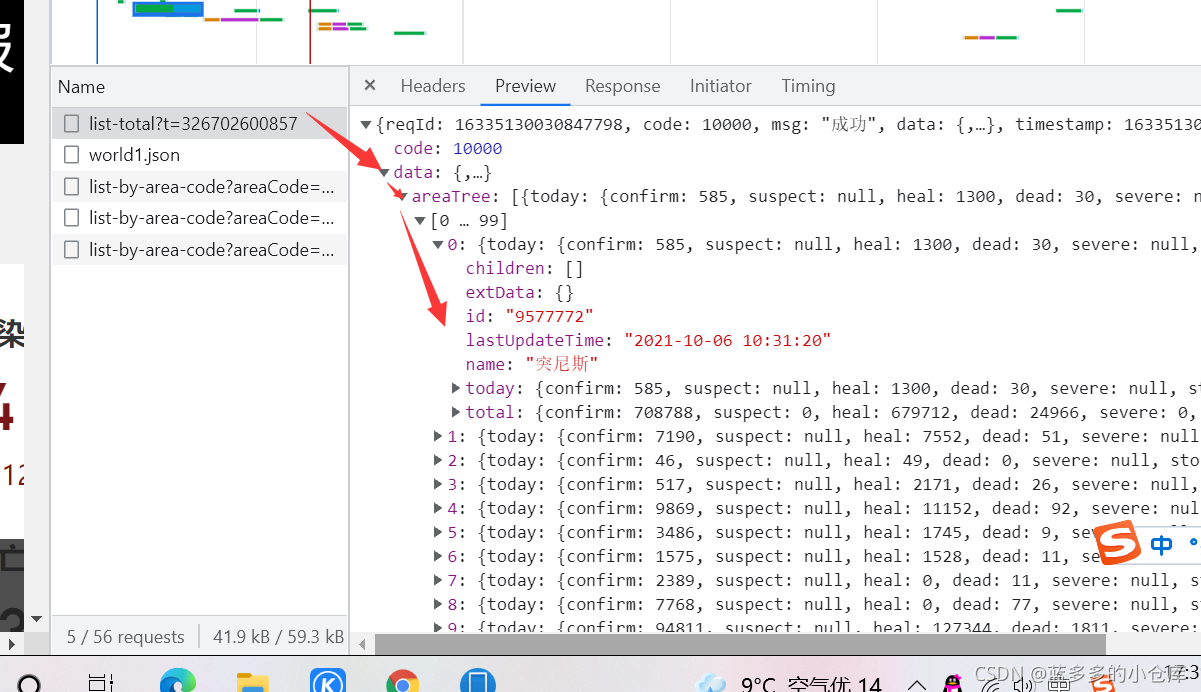
headers在这里获得:
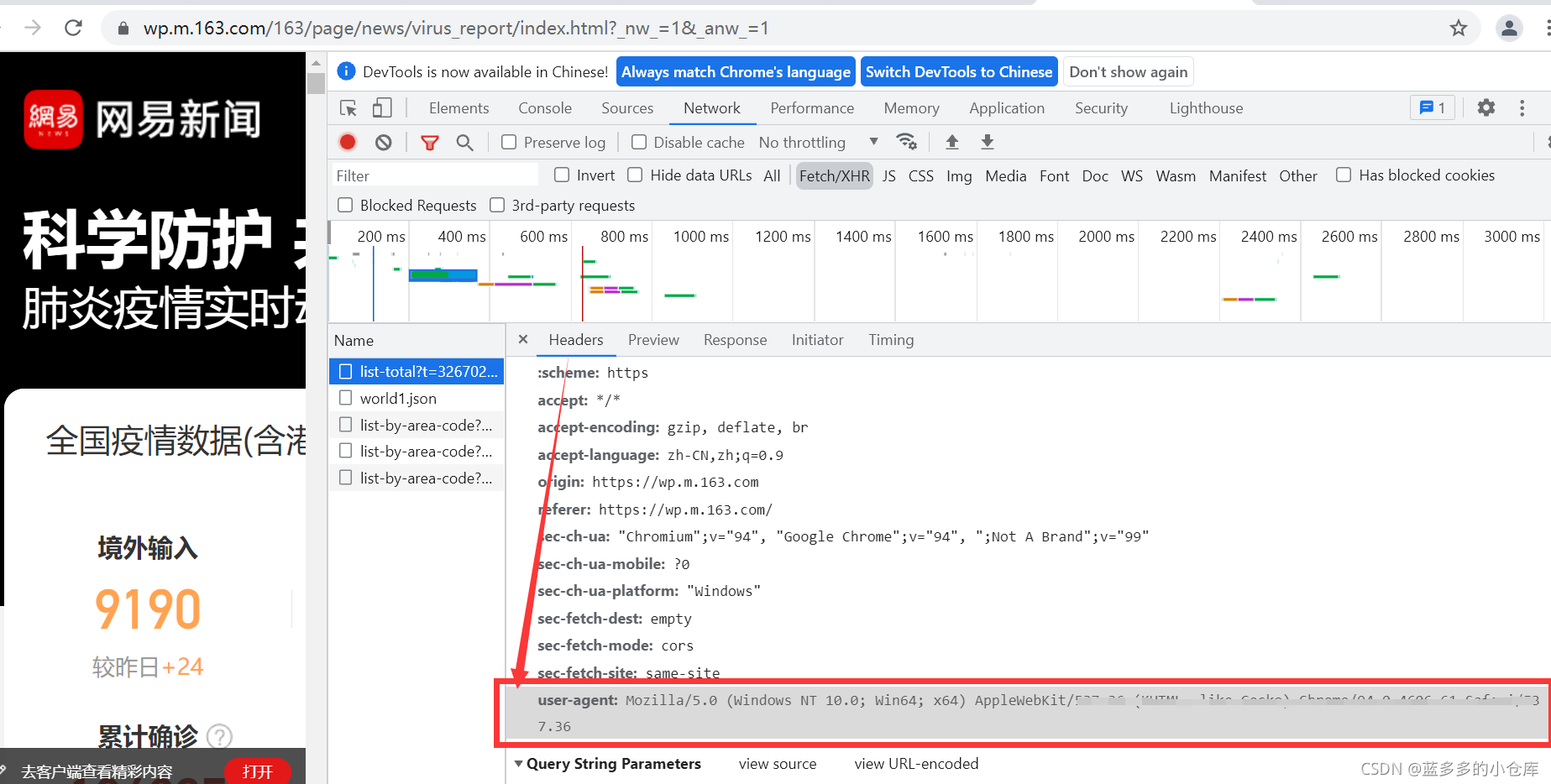
URL在这里获得:

代码:
import requests
import pandas as pd
import json
import time
def get_html (Url,Headers):
try:
ret = requests.get(url=Url, headers=Headers)
print(ret) # 打印请求状态
return ret.text
except:
print('呜呜呜,爬取失败了!\n学生请不要用校园网嗷')
def get_data (dic_data, index):
info = pd.DataFrame(dic_data)[index]
print(info)
tdy_data = pd.DataFrame([country["today"] for country in dic_data])
tdy_data.columns = ["today_" + col for col in tdy_data.columns]
ttl_data = pd.DataFrame([country["total"] for country in dic_data])
ttl_data.columns = ["total_" + col for col in ttl_data.columns]
return pd.concat([info, tdy_data, ttl_data], axis=1) #axis = 1 按列合并链接的轴
def data_save(data, name):
try:
f_name = time.strftime("%Y%m%d", time.localtime(time.time())) + name + ".csv"
data.to_csv(f_name, index=None, encoding="gbk")
print(f_name + " 已成功保存")
except:
print('数据保存失败')
if __name__ == "__main__":
start = time.time()
url="https://c.m.163.com/ug/api/wuhan/app/data/list-total"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/83.0.4103.61 Safari/537.36 "}
ret_txt = get_html(url,headers)
world_data = json.loads(ret_txt)["data"]["areaTree"]
index = ["id", "name", "lastUpdateTime"]
world_rlt_data = get_data(world_data, index)
data_save(world_rlt_data, "_World_COVID-19")
end = time.time()
print("本次爬虫历时:", end - start, "秒")
结果截图:
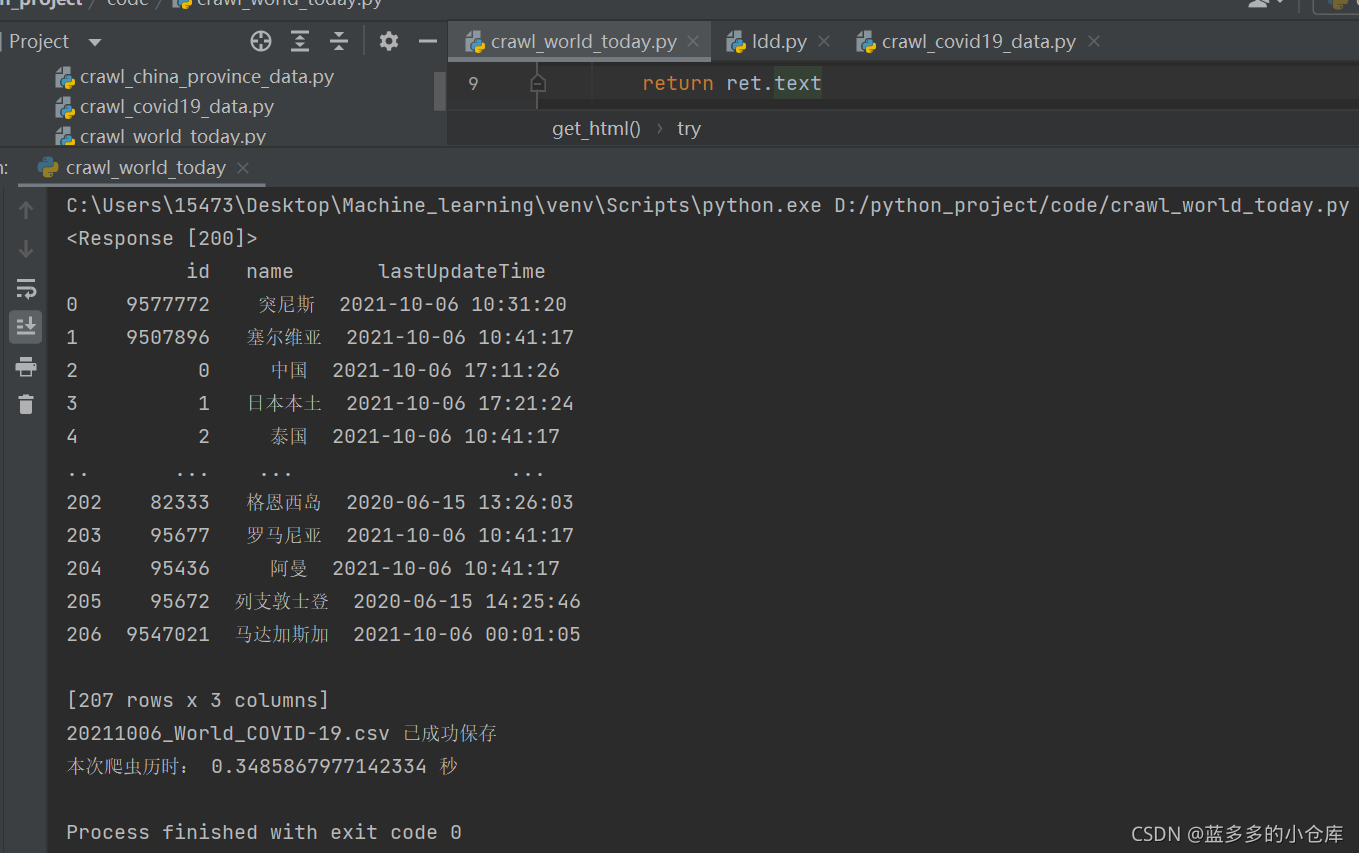
数据展示:
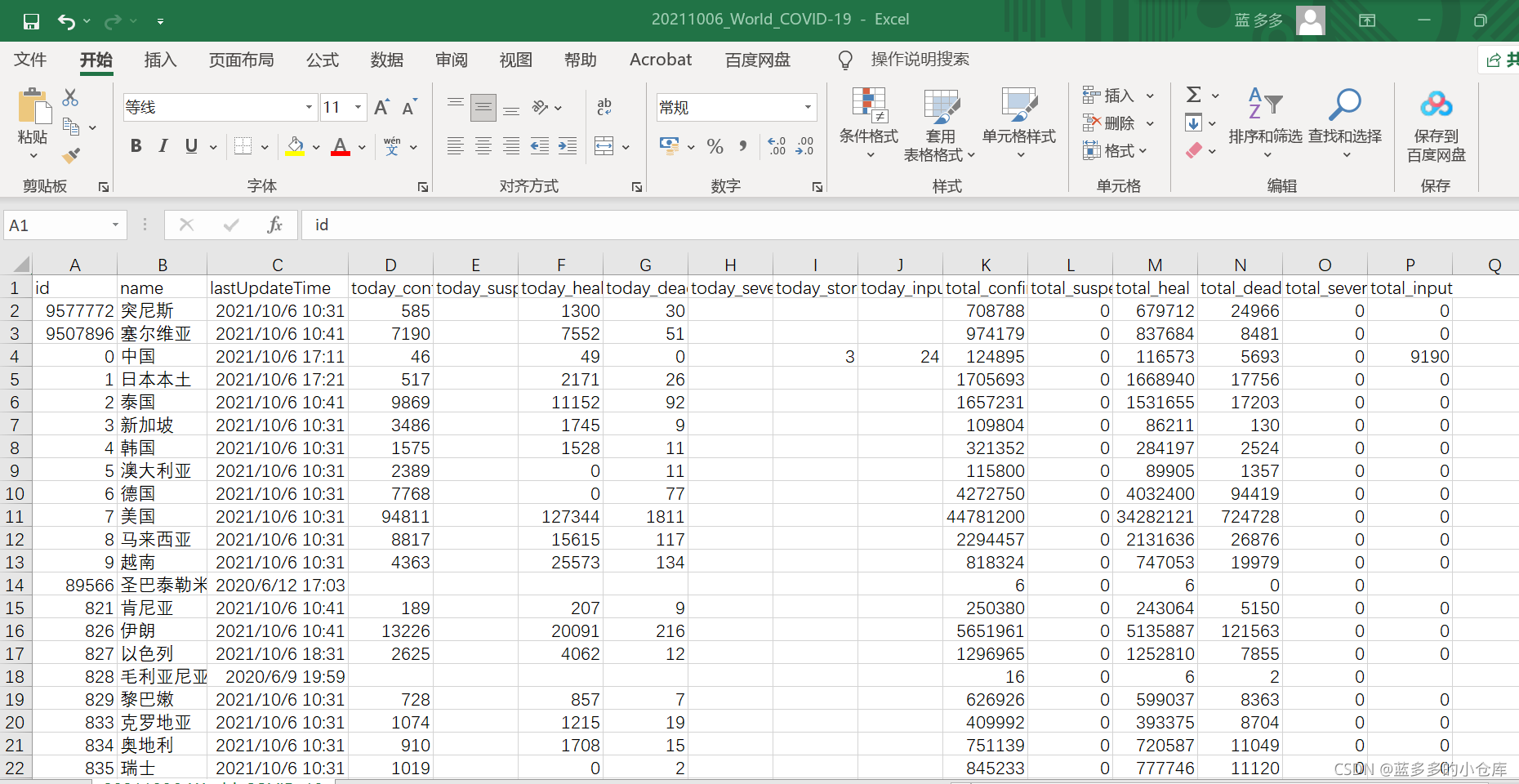
仅供学习使用。