致敬英雄,缅怀同胞
愿 花飨逝者 春暖斯人 山河无恙 世间皆安
注:从博文为实训项目,素材等来源自百知教育
这篇文章将分享腾讯疫情实时数据抓取,获取全国各地的数据,并将数据存储至数据库当中。希望这篇数据采集文章对您有所帮助,也非常感谢百知教育的分享,一起加油,战胜疫情!如果您有想学习的知识或建议,可以给作者留言~
1、通过数据库的方式存储疫情数据
同时推荐前面作者另外两个系列文章:
- 快速入门之Tableau系列:快速入门之Tableau
- 快速入门之爬虫系列:快速入门之爬虫
此篇博文可以看作是简单系列的疫情分析及可视化系列,如果想要看更加完整的可以看作者还未更新完的COVID-19分析专栏:
我们的目标网站是腾讯新闻网实时数据,其原理主要是通过Requests获取Json请求,从而得到各省、各市的疫情数据,在此推荐一篇原创文章:
一、准备阶段
1、分析网页结构
1、通过浏览器“审查元素”查看源代码及“网络”反馈的消息,如下图所示:
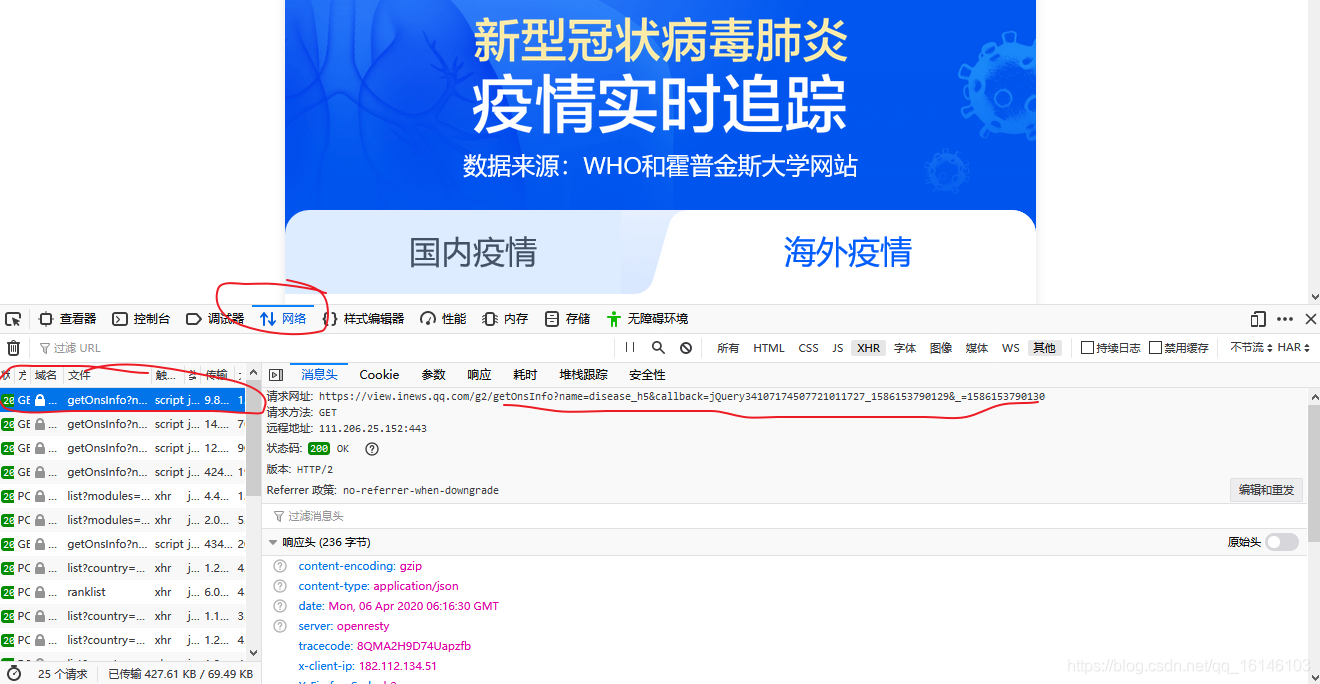
对应的响应头为:

2、发送请求并获取Json数据
通过分析url地址、请求方法、参数及响应格式,可以获取Json数据,注意url需要增加一个时间戳。
import time, json, requests
# 抓取腾讯疫情实时json数据
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410030722131703015076_1585221499806&_=1585221499807'
response = requests.get(url=url)
# 获得了返回的json串,其中 得到的数据不是正式的json数据,需要用切片切出我们需要的部分
data = json.loads(response.text[43:-1])
# data 中的目标数据,并非是一个字典,而是一个长得像字典的字符串---JSON串 相当于JSON中嵌套了一个JSON
data = json.loads(data['data'])
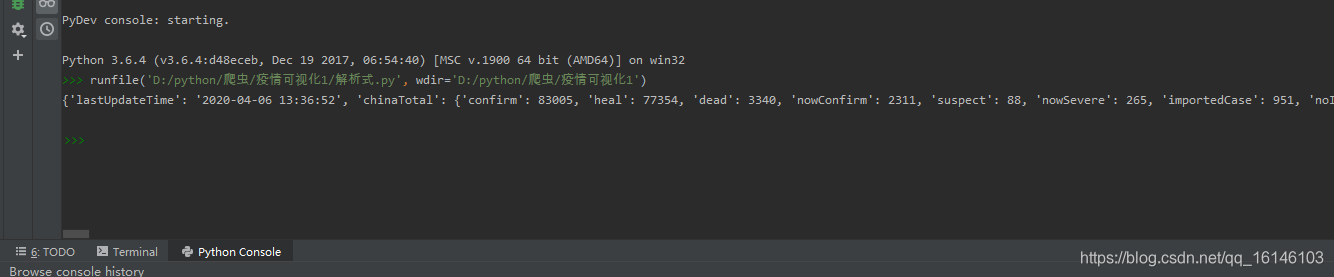
print(data)
# 获得国内累计所有数据
- 下图为所获得的所有数据
3、创建并完善数据库
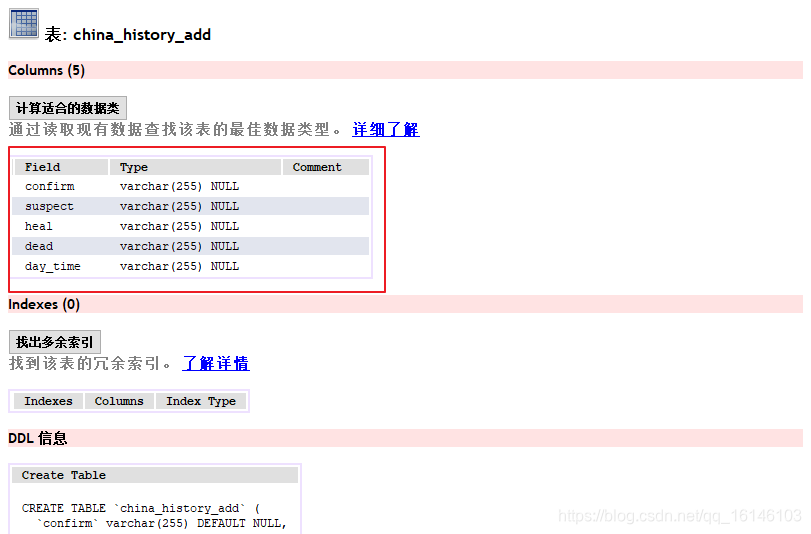
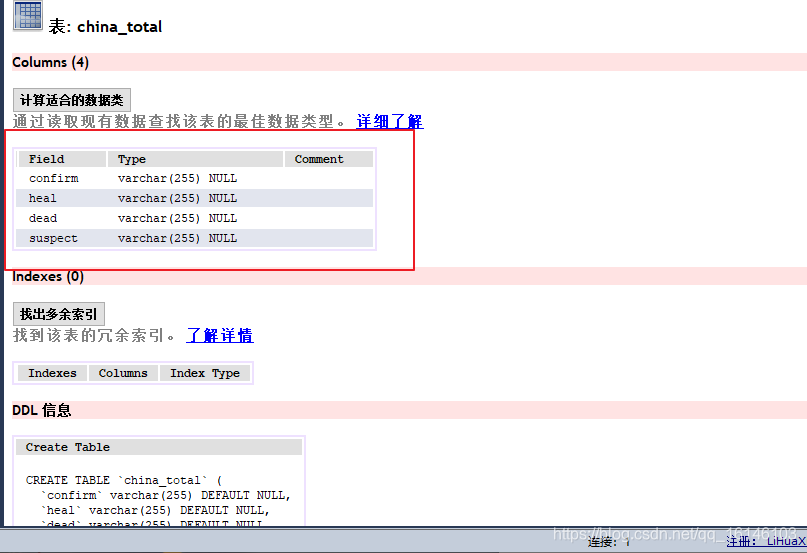
数据库我选用的是mysql+SQLyog
下图为所要创建的表以及基本参数:
我们总共需要创建四个表
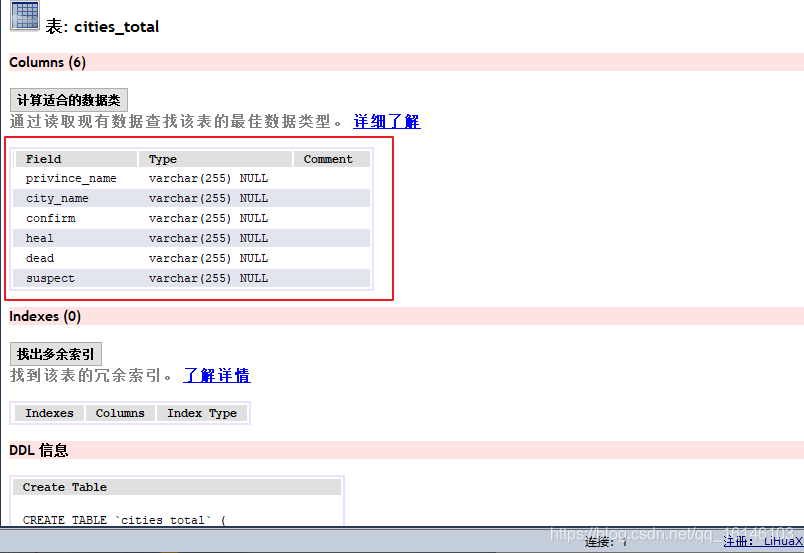
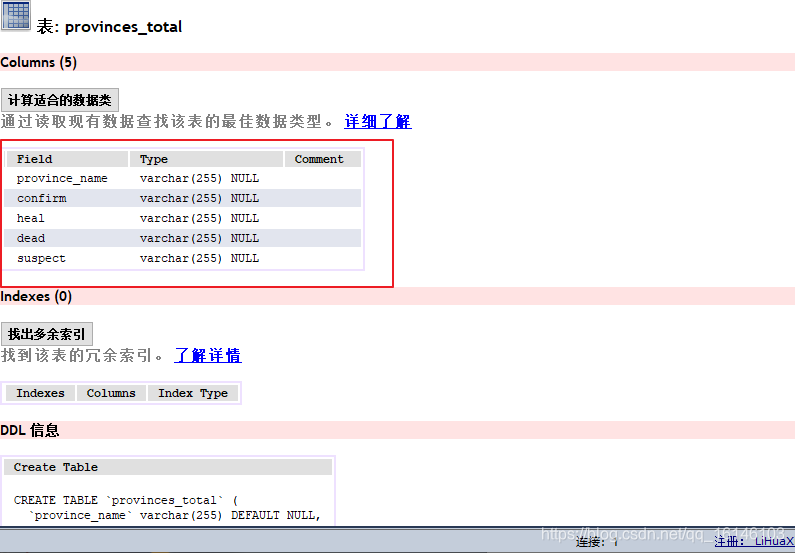
- 好了,以上即为我们需要提前准备的部分。
二、完整代码实现
# encoding: utf-8
# getOnsInfo?name=dease_h5:
# 国内累计数据 国内当日新增数据 各个省的当日信息和累计信息 各个市的当日信息和累计信息
import requests,json,pymysql
def get_database():
conn = pymysql.connect(host='localhost',
user='root',
password='199712',
db='yiqing',
charset='utf8')
# 创建游标
cursor = conn.cursor()
return conn,cursor
def close(conn,cursor):
cursor.close()
conn.close()
# 国内累计数据
def china_total_data():
#发送请求:
url='https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410030722131703015076_1585221499806&_=1585221499807'
response=requests.get(url=url)
# 获得了返回的json串,其中 得到的数据不是正式的json数据,需要用切片切出我们需要的部分
data=json.loads(response.text[43:-1])
# data 中的目标数据,并非是一个字典,而是一个长得像字典的字符串---JSON串 相当于JSON中嵌套了一个JSON
data = json.loads(data['data'])
# print(data)
# 获得国内累计所有数据
total_data=data['chinaTotal']
# 获得确诊数量
confirm=total_data['confirm']
# 获得治愈数量
heal=total_data['heal']
# 获得死亡数量
dead=total_data['dead']
# 获得疑似数量
suspect=total_data['suspect']
# ============================================数据处理完毕
# 数据入库: ---在使用数据库之前,一定要先创建好库表
conn,cursor=get_database()
# 准备sql
sql='insert into china_total(confirm,heal,dead,suspect) values(%s,%s,%s,%s)'
# 执行sql
cursor.execute(sql,args=[confirm,heal,dead,suspect])
conn.commit()
close(conn,cursor)
# 各个省累计数据
def provinces_total_data():
# 发送请求:
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410030722131703015076_1585221499806&_=1585221499807'
response = requests.get(url=url)
# 获得了返回的json串,其中 得到的数据不是正式的json数据,需要用切片切出我们需要的部分
data = json.loads(response.text[43:-1])
# data 中的目标数据,并非是一个字典,而是一个长得像字典的字符串---JSON串 相当于JSON中嵌套了一个JSON
data = json.loads(data['data'])
# print(data)
# 获得所有的省累计所有数据
privinces_data = data['areaTree'][0]['children']
for privince in privinces_data:
privince_name=privince['name']
total_data=privince['total']
# 获得确诊数量
confirm = total_data['confirm']
# 获得治愈数量
heal = total_data['heal']
# 获得死亡数量
dead = total_data['dead']
# 获得疑似数量
suspect = total_data['suspect']
# ============================================数据处理完毕
# 数据入库: ---在使用数据库之前,一定要先创建好库表
conn, cursor = get_database()
# 准备sql
sql = 'insert into provinces_total(province_name,confirm,heal,dead,suspect) values(%s,%s,%s,%s,%s)'
# 执行sql
cursor.execute(sql, args=[privince_name,confirm, heal, dead, suspect])
conn.commit()
close(conn, cursor)
# 各个市累计数据
def cities_total_data():
# 发送请求:
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410030722131703015076_1585221499806&_=1585221499807'
response = requests.get(url=url)
# 获得了返回的json串,其中 得到的数据不是正式的json数据,需要用切片切出我们需要的部分
data = json.loads(response.text[43:-1])
# data 中的目标数据,并非是一个字典,而是一个长得像字典的字符串---JSON串 相当于JSON中嵌套了一个JSON
data = json.loads(data['data'])
# print(data)
# 获得所有的省累计所有数据
p_total_data = data['areaTree'][0]['children']
for province in p_total_data:
# 获得省的名字
province_name = province['name']
for city in province['children']:
#获得市的名字
city_name=city['name']
# 获得总数据
total_data = city['total']
# 获得确诊数量
confirm = total_data['confirm']
# 获得治愈数量
heal = total_data['heal']
# 获得死亡数量
dead = total_data['dead']
# 获得疑似数量
suspect = total_data['suspect']
# ============================================数据处理完毕
# 数据入库: ---在使用数据库之前,一定要先创建好库表
conn, cursor = get_database()
# 准备sql
sql = 'insert into cities_total(privince_name,city_name,confirm,heal,dead,suspect) values(%s,%s,%s,%s,%s,%s)'
# 执行sql
cursor.execute(sql, args=[province_name,city_name, confirm, heal, dead, suspect])
conn.commit()
close(conn, cursor)
# 国内历史日增数据
def china_history_daily_data():
# 发送请求:
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_other&callback=jQuery34106126228069621358_1585225505936&_=1585225505937'
response = requests.get(url=url)
# print(response.text)
# 获得了返回的json串,其中 得到的数据不是正式的json数据,需要用切片切出我们需要的部分
data = json.loads(response.text[41:-1])
# data 中的目标数据,并非是一个字典,而是一个长得像字典的字符串---JSON串 相当于JSON中嵌套了一个JSON
data=json.loads(data['data'])
# print(data)
for daily_data in data['chinaDayList']:
confirm=daily_data['confirm']
suspect=daily_data['suspect']
heal=daily_data['heal']
dead=daily_data['dead']
day_time=daily_data['date']
# print(confirm,suspect,heal,dead,day_time)
# 入库
conn,cursor=get_database()
sql='insert into china_history_add(confirm,suspect,heal,dead,day_time) values(%s,%s,%s,%s,%s)'
cursor.execute(sql,args=[confirm,suspect,heal,dead,day_time])
conn.commit()
close(conn,cursor)
# 一键更新
def update():
conn,cursor=get_database()
l=['china_total','china_history_add','cities_total','provinces_total']
for table in l:
# 清空数据库
sql='TRUNCATE table %s'%table
cursor.execute(sql)
conn.commit()
close(conn, cursor)
# 重新获取新数据
china_total_data()
china_history_daily_data()
provinces_total_data()
cities_total_data()
if __name__ == '__main__':
china_total_data()
provinces_total_data()
cities_total_data()
china_history_daily_data()
update()
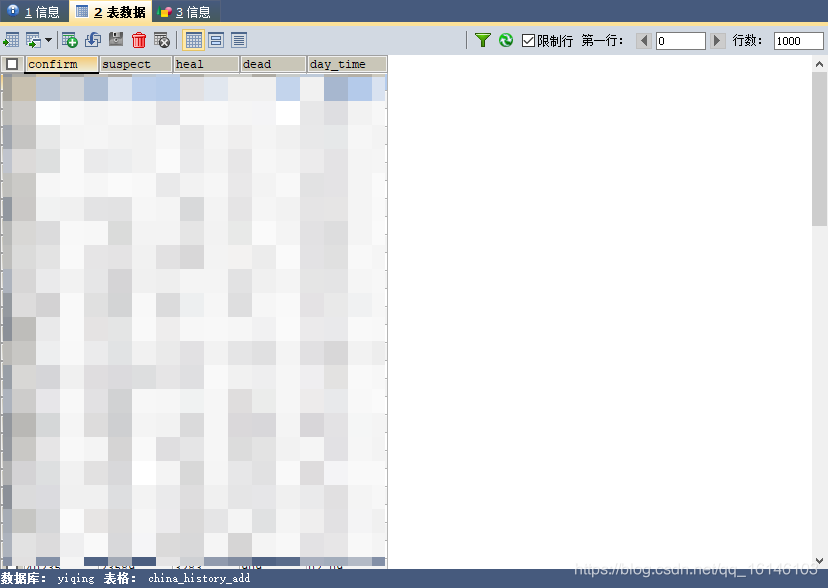
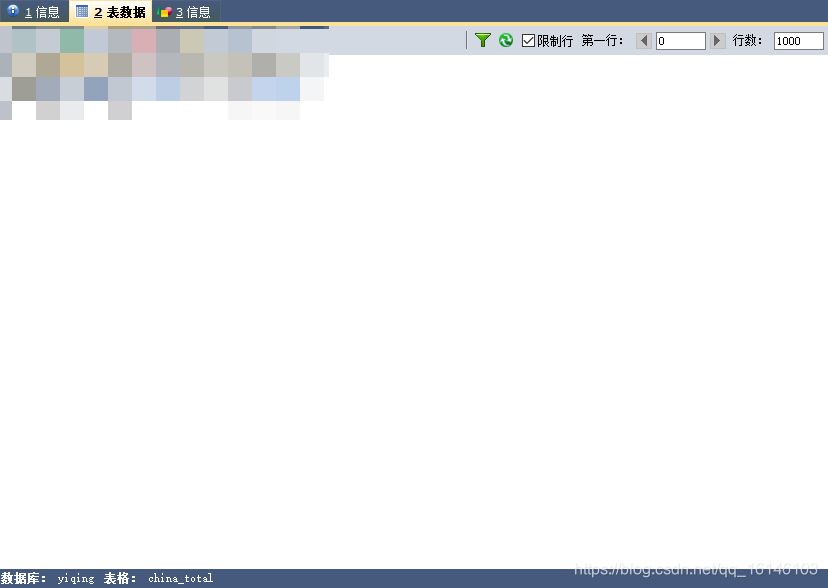
三、保存成功

在数据库中查看保存结果
因为设计疫情数据,没有新闻资质的平台和个人,不允许发布疫情数据类信息。所以各位在做的时候需要自己判定。

四、总结
- 仅仅只爬取并存储了国内的数据,可以自行添加爬取世界各国的数据。
- 写到这里,第一篇疫情分析的文章就讲解完毕,希望对您有所帮助。
我又来要赞了,还是希望各位路过的朋友,如果觉得可以学到些什么的话,点个赞再走吧,欢迎各位路过的大佬评论,指正错误,也欢迎有问题的小伙伴评论留言,私信。每个小伙伴的关注都是本人更新博客的动力!!!
