1.首先导入2个第三方库,json库是标准库,用到的有Requests库,Beautisoup库,json库
2.分析网站,当然是f12 开发者工具了,firefox浏览器的开发者工具个人用着比chrome的好用一点。 用开发者工具之前要先明白你要找什么数据,我想抓取的是霹雳布袋戏的所有歌曲信息(顺便安利下霹雳布袋戏)
抖个机灵,通过我仔细观察,我发现通过改url的limit参数(每页显示的专辑数量),offset参数(当前页)就能获取某用户的所有专辑,这样能避免抓取的数据有很多页而要考虑下一页的情况。
"https://music.163.com/artist/album?id=12639&limit=200&offset=0"
为了验证我的想法,我用的是chrome的servistate插件,
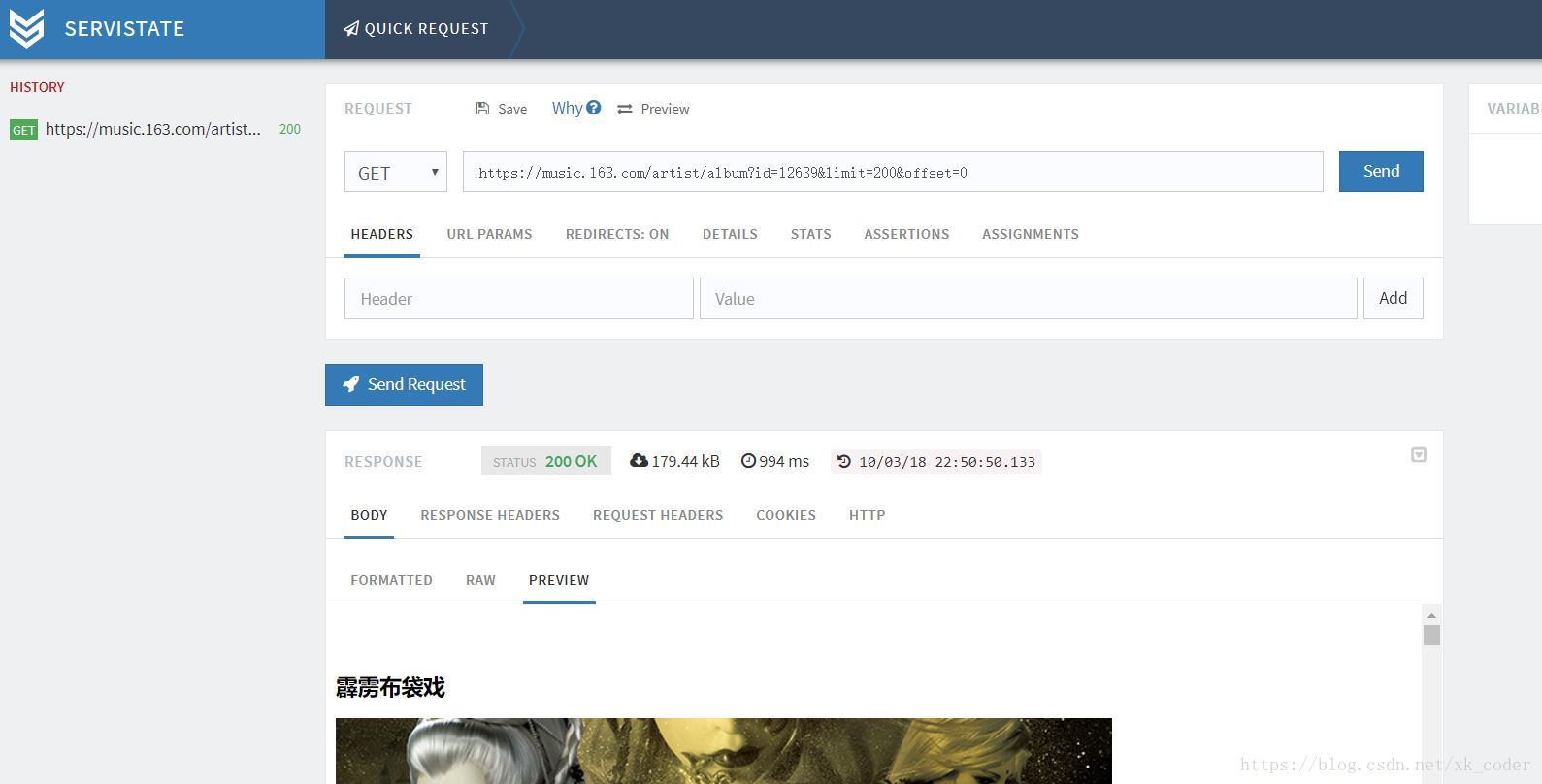
确认这个接口就是我们需要的。
3.动手写第一个函数,发送request请求,返回它的二进制格式,因为这个函数请求json数据的时候也会用到。
4.然后就是beautifulsoup库提取出我们想要的数据
通过观察get请求的响应内容,我发现专辑id放在"tit s-fc0"的标签里,同理找到专辑name和专辑的创作时间,我们用beautifulsoup对象的finda_all方法,将之提取出来。
5.专辑的id有了,我想要的是每一张专辑里面所有曲子的详细信息,同理我们再去找有歌曲信息的请求,找了半天发现每首曲子的信息是以json格式传给我们的,并且是个post请求,有两个参数是通过js加密生成的,一个是当前时间戳加密一个是随机字符,反正就是很麻烦。找了半天,又发现有一个通过get请求就可以获取到数据的接口。
"http://music.163.com/api/v1/resource/comments/R_SO_4_"+songid
就是这个接口,还是使用chrome的servistate插件验证一下我的猜测,
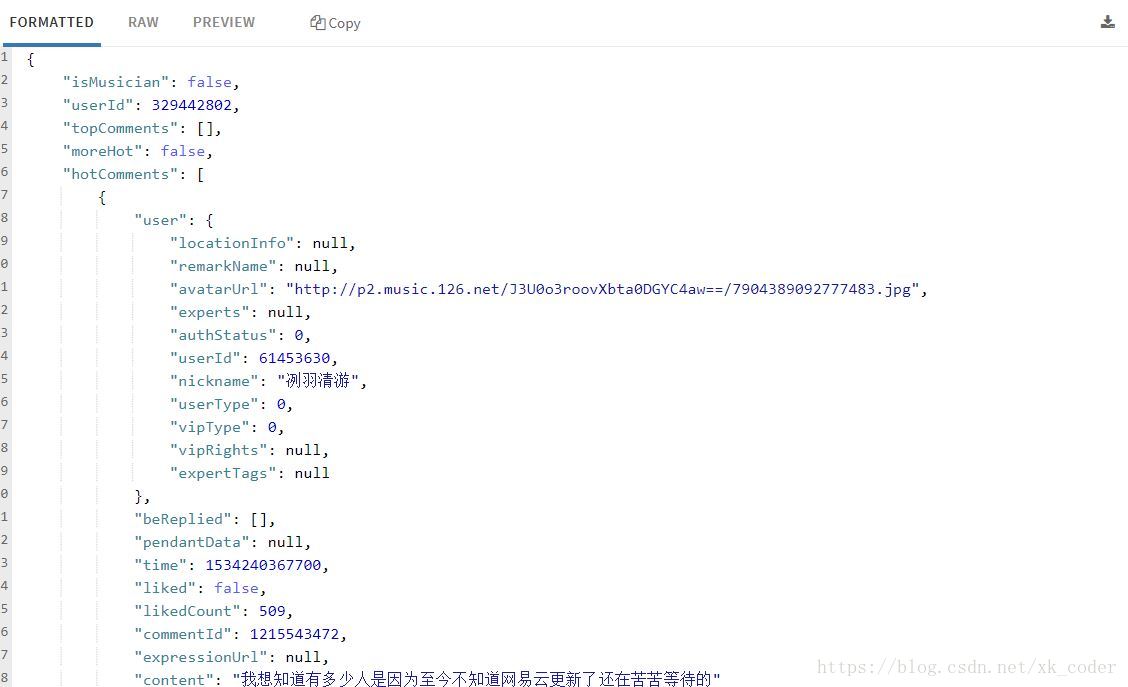
我们发现它返回的是json字符串,然后我们通过json库和beautifulsoup库解析提取出我们需要的数据。
我们需要的数据就抓取下来了,然后用xlwt库写入到excel表格中。学会使用开发者工具,需要明白的不只是python的知识,还需要html的知识,知道request请求和response响应。
下面贴出完整代码
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import json
print("开始抓取数据,请保持网络畅通。。。")
url='https://music.163.com/album?id=72301648'
header = {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
def gethtml(url): #获取专辑的html
try:
response=requests.request('get',url,headers=header,timeout=30)
response.raise_for_status()
response.encoding=response.apparent_encoding
html=response.content
except:
print("error:网络原因爬取出错!")
return html
def resolvehtml(html): #解析专辑的html,返回最终要输出的id(数字类型),name,title,专辑中的歌曲数量
index=BeautifulSoup(html,"html.parser")
lsul=index.find_all(class_="f-hide")[0] #返回的是无序列表,歌曲的id和name<li><a href="/song?id=1301575103">暗夜曙光</a>,用列表存储
title=(index.title.string)[:-21] #专辑的标题,字符串切片去掉最后21位
songid = []
songname = []
songnum=len(lsul)
for i in range(songnum):
songid.append(lsul.find_all("a")[i]["href"]) #取出所有a标签的href属性,并且存储为列表类型
songname.append((lsul.find_all("a")[i].string))#取出所有a标签的内容,并且存储为列表类型
songid[i]=int((str(songid[i]))[9:]) #将id信息改为纯数字id
return songid,songname,title,songnum
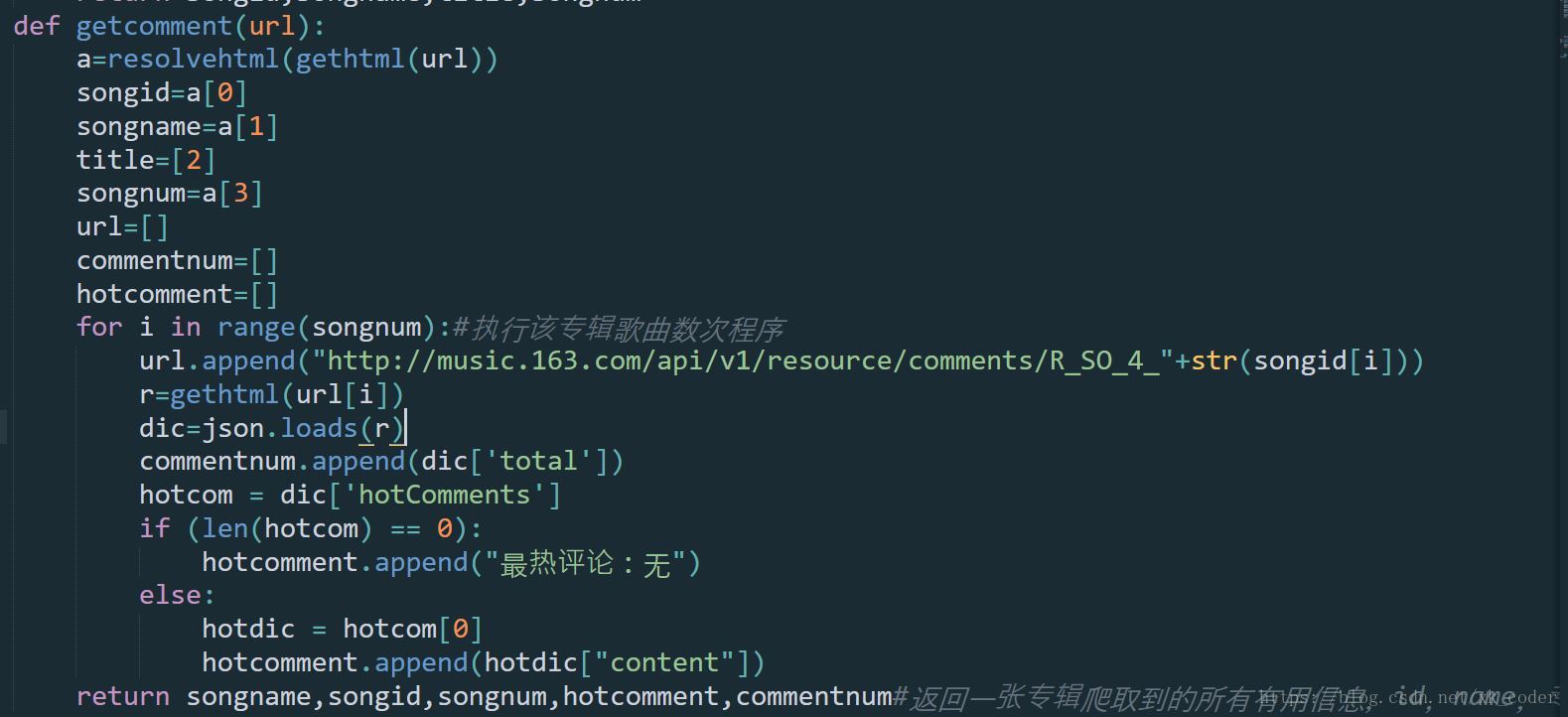
def getcomment(url):
a=resolvehtml(gethtml(url))
songid=a[0]
songname=a[1]
title=[2]
songnum=a[3]
url=[]
commentnum=[]
hotcomment=[]
for i in range(songnum):#执行该专辑歌曲数次程序
url.append("http://music.163.com/api/v1/resource/comments/R_SO_4_"+str(songid[i]))
r=gethtml(url[i])
dic=json.loads(r)
commentnum.append(dic['total'])
hotcom = dic['hotComments']
if (len(hotcom) == 0):
hotcomment.append("最热评论:无")
else:
hotdic = hotcom[0]
hotcomment.append(hotdic["content"])
return songname,songid,songnum,hotcomment,commentnum#返回一张专辑爬取到的所有有用信息,id,name,专辑歌曲数,热评,热评数
def albuminfo():
url = "https://music.163.com/artist/album?id=12639&limit=200&offset=0"#霹雳布袋戏的所有专辑页url
menuid = []
menuname = []
menutime = []
r=gethtml(url)
txt1=BeautifulSoup(r,'html.parser')
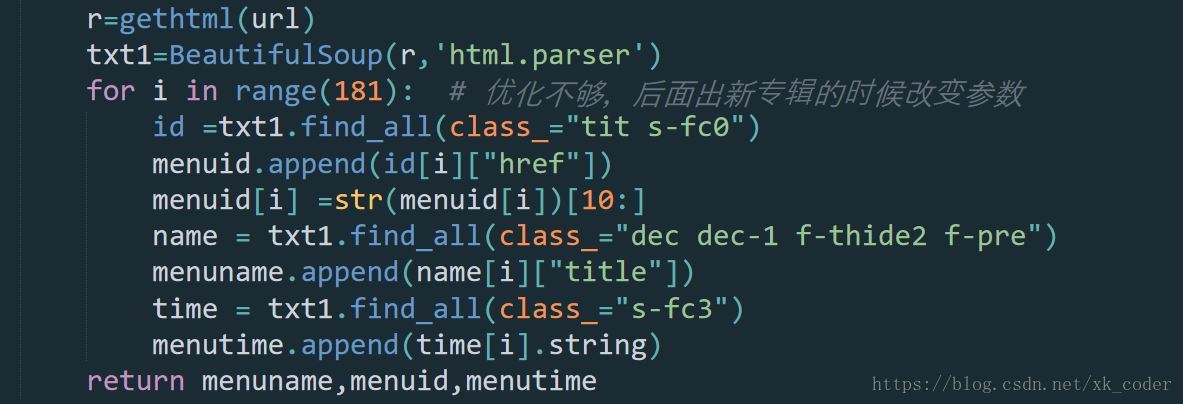
for i in range(181): # 优化不够,后面出新专辑的时候改变参数
id =txt1.find_all(class_="tit s-fc0")
menuid.append(id[i]["href"])
menuid[i] =str(menuid[i])[10:]
name = txt1.find_all(class_="dec dec-1 f-thide2 f-pre")
menuname.append(name[i]["title"])
time = txt1.find_all(class_="s-fc3")
menutime.append(time[i].string)
return menuname,menuid,menutime
fp = open("test.txt", 'a',encoding="utf-8")
def main():
result=albuminfo()
for i in range(181):
url='https://music.163.com/album?id='+(result[1])[i]
fp.write(str(getcomment(url)))
fp.close()
main()