1. 训练误差和泛化误差
把学习器的实际预测输出与样本真实输出值之间的差异称为“误差”。
训练误差:学习器在训练数据上的误差,可做为模型调参的依据。
泛化误差:学习器在新样本上的误差,反映了学习器对未知数据的预测能力。将学习器对未知数据的预测能力称为泛化能力,泛化误差越小,泛化能力越强,越是符合我们的期望。
2. 过拟合与欠拟合
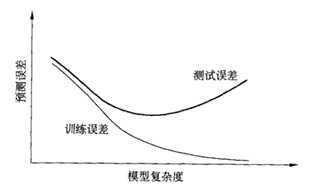
过拟合:学习器对已知数据学习的太好了,以至于把训练样本特有的一些性质当作了所有样本都具有的性质,即:模型的复杂度高于实际“真模型”,在已知数据上表现很好,在未知数据上表现很差。
欠拟合:学习器连已知样本的一般性质都没有学好,即:模型复杂度低于实际“真模型”,导致学习能力不足,在已知数据和未知数据的预测表现都较差。
从图中可以看到,当模型复杂度增加时,训练误差不断下降,而测试误差先降低后增加,这是因为在模型复杂度过高时发生了过拟合造成的,因此在实际模型训练中,我们需要选择复杂度适当的模型,以达到测试误差最小、泛化能力最强的目的。而过拟合是无法避免的,只能通过早停、正则化等方法进行缓解,而欠拟合可以通过增加模型复杂度克服。
3. 常用的模型评估方法
可以通过实验测试的方式评估学习器的泛化能力选择恰当的模型复杂度。在实际中,未知样本我们是事先不知道的,因此无法直接计算泛化误差。通常可将已有数据划分为互斥的两部分,一部分作为训练集,进行学习器的学习,另一部分对于学习过程是不可见的,称为测试集,利用学习器在测试集上的测试误差衡量学习器的泛化能力,进行学习器的选择。常见的划分数据集的方法有留出法、交叉验证、自助法。
(1) 留出法
留出法是将数据集划分成两个完全互斥的集合,一个作为训练集,一个作为测试集,利用训练集进行学习器的训练,利用测试集估计泛化误差。一般训练样本数量占全部数据的比例在2/3~4/5之间,在数据类别不均衡时,可采用分层抽样避免因采样带来的误差,保证训练集/测试集中数据分布与原始数据集的分布一致。单次使用留出法划分数据集得到的结果可能存在数据集划分造成的误差,结果往往缺乏可靠性和稳定性,因此一般采用多次划分试验后取平均值作为最终结果。留出法可通过sklearn中的train_test_split实现:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,stratify = y)
其中stratify = y表示按照标签类别的分布进行分层抽样。
(2) 交叉验证
交叉验证是将数据集等额划分为k个互斥子集,依次从中取出k-1个子集作为训练集,剩余一个子集作为测试集,循环此过程k次,使得每个子集都作为一次测试集,最终产生k个测试结果。类比于留出法,将数据集划分为k个子集时,存在多种划分方式,为减少因数据集划分造成的误差,往往对数据集划分n次,这样一来,会产生n×k个评估结果,取平均值作为最终结果。这种方法称为n次k折交叉验证。
图中所示为一个十折交叉验证,即将数据集D划分为十份,每次不重复的取其中九份作为训练集,一份为测试集,最后得到十个测试结果,取这十个结果的平均值作为最终评估结果。

交叉验证可通过sklearn中的StratifiedKFold实现:
from sklearn.model_selection import StratifiedKFold
skf=StratifiedKFold(n_splits=10,shuffle=True)
for train_index, test_index in skf.split(X,y):
X_train=X.iloc[train_index]
X_test=X.iloc[test_index]
y_train=y.iloc[train_index]
y_test=y.iloc[test_index]
留一法是交叉验证的特例,即在子集划分时,将每一个样本划分为一个子集,这样每个子集只包含一个样本,不受随机样本划分方式的影响。留一法可通过sklearn中的LeaveOneOut实现:
from sklearn.model_selection import LeaveOneOut
loo = LeaveOneOut()
for train, test in loo.split(X,y):
X_train=X.iloc[train]
X_test=X.iloc[test]
y_train=y.iloc[train]
y_test=y.iloc[test]
(3) 自助法
在留出法和交叉验证中,我们都是从原始数据中拿出一部分作为测试集,在实际模型评估中,用到的样本不是全部原始数据,这就会引入一些因人为采样带来的误差。自助法是一种有放回采样,给定一个包含n个数据的数据集D,每次从中随机抽取一个样本,拷贝到数据集D’中,将该样本放回原始数据集,重复此过程n次,得到一个与原始数据集样本数量相同的数据集,但该数据集中的样本有一些样本出现了多次也有一些样本一次也没出现,根据统计学知识
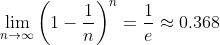
可知,大概有36.8%的样本未被抽到,这部分样本称为“袋外样本”,可作为测试集。在随机森林特征重要性衡量中一种重要的方法就是利用袋外样本度量特征重要性:
forest=RandomForestClassifier(oob_score=True, n_estimators=100,random_state=10)
4.模型评估方法对比
留出法:简单直接易用;适用于数据量较大
交叉验证:样本信息损失较少;计算量较大,开销较大,适用于数据量较少情况(留一法的训练集只比原始数据集少一个样本,所以其评估结果准确性更高,但其开销过大)
自助法:小样本适用;会使得数据分布改变
在进行数据集的划分时,要特别注意采样需要根据实际问题判断是否需要分层采样,保证数据分布一致性。