论文链接:http://openaccess.thecvf.com/content_cvpr_2017/papers/Qi_PointNet_Deep_Learning_CVPR_2017_paper.pdf
代码地址:https://github.com/fxia22/pointnet.pytorch
PointNet首次将点云数据直接拿来做端到端的训练。而在此之前,「体素化(Voxelization)+3d卷积」和「将点云投影到二维平面」是处理三维数据的常见方法。但3d数据最初始的形态就是点云,因此体素化和投影会造成一些问题,且3d卷积的代价较大;而且映射到2d会损失一些3d信息。
点云数据最大的一个问题就是无序性,有三种方法处理这个问题:(1)对无序数据进行排序;(2)将其看成一种序列,用RNN处理;(3)采用一种简单的对称函数,消除无序数据的影响,如max,sum,乘法等等。
作者采用了max pooling这一对称函数(Symmetric function),来解决点云数据的无序性特征。也就是说,无论输入数据的序列是否相同,经对称函数变换得到的结果都是一致的。

下面分析一下这个max pooling是怎么作用的,先贴一个PointNet模型结构图:
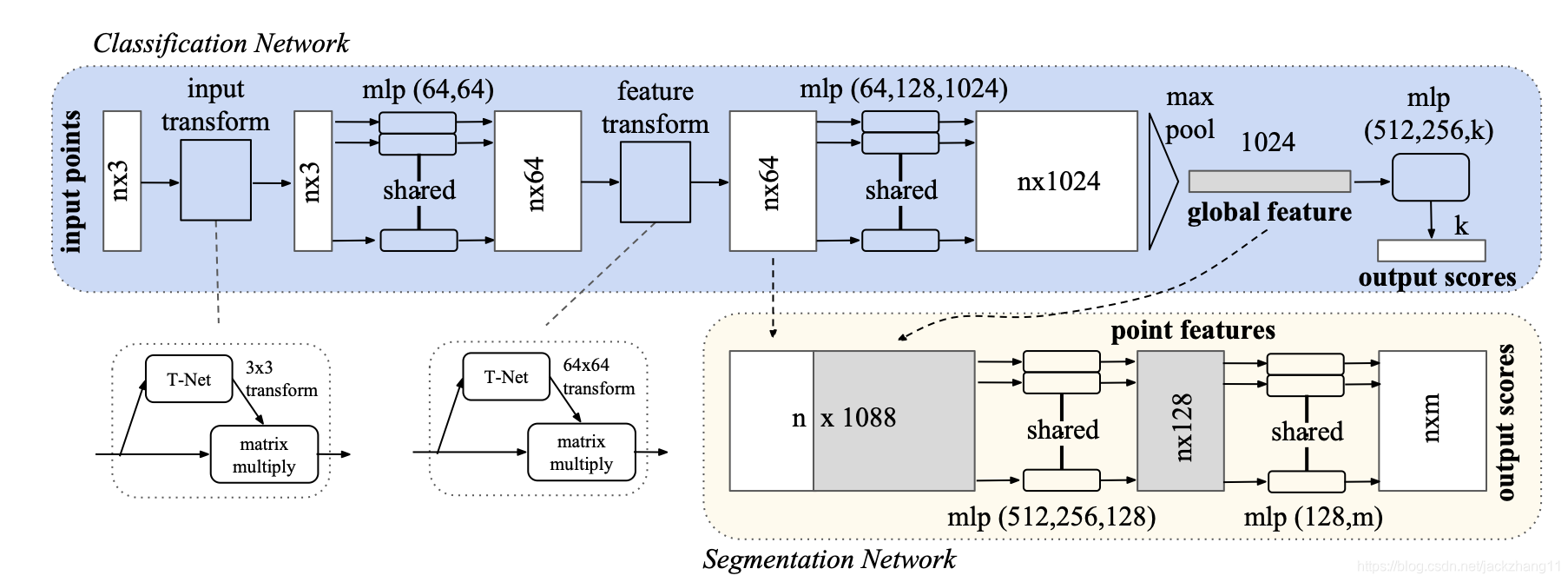
上图中上半部分的蓝色区域是分类模型。输入是batch张点云图,每个点云图包括n个点数据,每个点数据包括三个维度(x,y,z)坐标。因此输入的维度为[batch, n, 3]。随后我们需要得到每一个点的特征向量,为了方便1dConv(代码中是1dConv,图中是mlp,不过问题不大,都是在做特征提取),调换第二和第三个维度(先不考虑T-Net的affine变换),此时数据维度变为[batch, 3, n]。经过一系列网络的变换,得到维度是[batch, 1024, n]的特征向量。而max pooling就是求解这n个点在每个维度上最大的的feature,因此每个点云图此时对应一个1024维的特征向量,再经过若干层mlp,得到各自的k维类别向量。
值得注意的是,点云数据所表示的目标在空间上具有一定的不变性,如平移或旋转。因此在网络中有两个Transform,分别对应输入点云图变换,以及特征变换。都是通过一个T-Net的结构学习到一个仿射变换矩阵(前者 3 ∗ 3 3*3 3∗3,后者 64 ∗ 64 64*64 64∗64),以对点云数据或特征进行对齐来保证其不变性。
因此对称函数max pooling的选取,和T-Net的引入以保证不变性,这两点非常妙。而在语义分割的网络中,作者还将全局特征与局部特征进行融合,这种做法也能一定程度上利用点云之间存在的空间关系。

PointNet具有较好的鲁棒性,在数据缺失20%的情况下,分类的准确率仍然保持较好的水平,其原因是PointNet能够学习到一些关键的点。在没有数据缺失的正常情况下,精确度与之前的「体素化」和「图像投影」的方法相比,也是非常优秀的。在分割方面,PointNet的平均IoU也稍优于3dCNN,但其速度是他最大的优势。
但是PointNet还存在一些缺点,例如在提取特征的时候都是先提取每个点各自的feature,因此与传统CNN逐层提取局部特征的方式不太一样。而且在classroom数据集做分割时,由于点云图过大,将其分割为若干 1 ∗ 1 1*1 1∗1的block,倘若一个物体正好被拦腰切开,那势必会造成一些问题。
最后mark一篇个人感觉非常好的PointNet的博文:
https://www.cnblogs.com/Libo-Master/p/9759130.html