Statistical Learning
机器学习的三个条件
- 示例——给定观测数据,得出相应的学习算法
- EX1
根据数字的大小进行排序,在有限的观测数据下可以得出整体label的分布是两头为负(-),中间为正(+)。
因为111在67和138两个正标签数之间,因此一定为正;
同理23在6和46两个负标签数之间,因此也一定为负;
但是55处在正负标签数据之间,因此其标签值并不确定。

- EX2
同样给出数字和正负标签的学习数据,如果依然按照顺序进行规律的查找可能会很难求解,转换视角,将数字全部转换成二进制就可以发现新的规律。
p.s. 恕我无能,对着图看了好久,将原视频此处听了好几次也没看出到底是什么规律,如果有看懂这一块的同学还请帮忙解释一下~

- 满足学习的三个条件
- 足够多的数据
以EX1为例,因为有限的训练数据,所以对于测试集的数字会出现不能很好预测的情况
- 吻合测试集的训练准则
我们需要得到一个具有一致性的训练方法来对数据进行分类划分,也即对于训练数据集中的数据具有普适性
- 训练规则要尽可能简单
训练规则的普适性(一致性)和训练规则的复杂程度往往需要一个权衡(trade-off):
如果想要尽可能地使训练数据贴合规则,则规则会较为复杂;
如果可以接受训练中的“错误”(与训练集不一致的情况),那么算法会趋于简单
机器学习的概念模型
- 基本概念
| Name | Notation |
|---|---|
| instance(实例) | x(x∈X) |
| instance space/domain(实例空间/域) | X |
| label/class(标签/类) | 0/1、-/+、… |
| concept(概念/事实) | c:X→{0,1} 每一个x都有相应的c(x)作为label |
| hypothesis(假设) | h:X→{0,1} |
| target distribution(目标分布) | D |
| hypothesis space(假设空间) | H |
- 训练模型
- 通过合适的学习算法A学习得到一个预测规则H
将带有标签的训练数据输入到学习算法(A)中,学习算法输出一个假设准则(Hypothesis),将数据输入到Hypothesis中,就会得到相应的输出标签作为预测值。
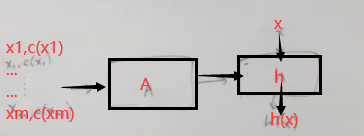
- 概念类C
为了训练的合理性,在给定的数据中,从实例到标签值的映射——c(concept)应该是已知或者部分已知的;既然c本质上是一个函数,那么我们应该是已知c所属于哪一个特定的函数类——在建模中我们称其为概念类,用C表示。
综上,得到实例与实例空间、概念与概念类以及假设与假设空间的从属关系:
xi∈X,c∈C,h∈H
- 训练数据
在现实世界中,人们习得某种经验的知识来源可以是世界的方方面面;因此在机器学习的模型建设中,我们常常假设训练数据是随机产生的,且假设这些数据都独立地、同一地来自于某一特定的分布。
- 评价准则
我们想要评价某个学习出来的Hypothesis是否合理,就需要指定我们学习的目标,从而设计出相应的评价准则。
- Err(h):某一假设h对应的误差函数
训练集和测试集都应来自同一目标分布D,那么误差函数可以定义为:从分布D中随机取出某一测试实例x,该实例的预测值和标签值不匹配的概率值。
Err(h) = Pr[h(x)≠c(x)]
- PAC Learning:Probably Approximately Correct
①既然给定了误差函数,我们的训练目标就是尽可能地减小训练误差的函数值,则应使得Err(h)≤ε;
通过设定不同的ε值,对算法的准确度就有不同的要求,算法方法和所用数据集的大小就会进行相应调整,以训练得到更好的h。
②但是因为训练数据是基于概率随机产生的,那么基于一个很小的坏概率会生成对训练不利的训练集,此时得到的hypothesis的表现就会很差,不能满足Err(h)≤ε中设定的条件;为了给算法和训练集一定的容错率,我们让“训练误差较小”这一目标基于概率存在。
③对于给定的ε,δ,应满足——P[Err(h)≤ε]≥1-δ
p.s. δ是容错值;ε是对训练结果的精度要求,其值越大,则算法精度要求更高,需要更大的数据集以供训练。
对于机器学习的PAC-Learning来说,有以下表达:
C is PAC-learnable by H if
- 存在一个算法A,对于
- 任意的概念c∈C,任意的分布D,任意的ε>0,δ>0
- 并基于分布D随机产生m个独立同分布的数据
- 学习得到某一个假设h∈H
s.t.
Pr[ErrD≤ε]≥1-δ
①当ε越来越小,算法要求的精度越高,也即学习算法应该需要更大的数据集来训练模型,故我们可以允许样本数目m是关于ε的多项式
一个实际的算法和PAC-learning
- 问题描述

| Notation | meaning |
|---|---|
| x(x∈X) | 数轴上的点 |
| X | 实数集 |
| label/class | +和- |
| c | f:{当点大于c0时标签值为正,否则为负} |
| C | 阈值函数集 |
- 任务描述
我们需要根据随机产生的数据点,对阈值进行估计,通常是在正标签点和负标签点之间的范围中找出某个点作为假设的阈值点;
因此在这个问题中,假设空间和概念空间是等同的。
| Notation | meaning |
|---|---|
| h(h∈H) | f:{当点大于b时标签值为正,否则为负} |
| H | 阈值函数集 |

在这里,选择一种最为简单的算法:即把标签值为正的点中最左边的点所在的位置定为阈值点
- PAC学习的推导
①首先要明确这个问题的误差函数,如下图所示:在真实阈值c和假设阈值b之间的区域就是不满足c(x)=h(x)的范围。
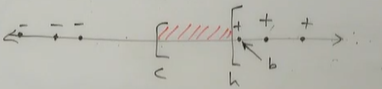
②所谓PAC标准,就是在给定误差精度的条件下可以得到训练样本m的约束条件,假定:
给定ε>0,有Err(h)>ε
③进行概率推导

也就是说,如果我们训练的数据样本数目m满足了最后推导出来的多项式条件,那么算法的精度就满足一开始规定的PAC标准。