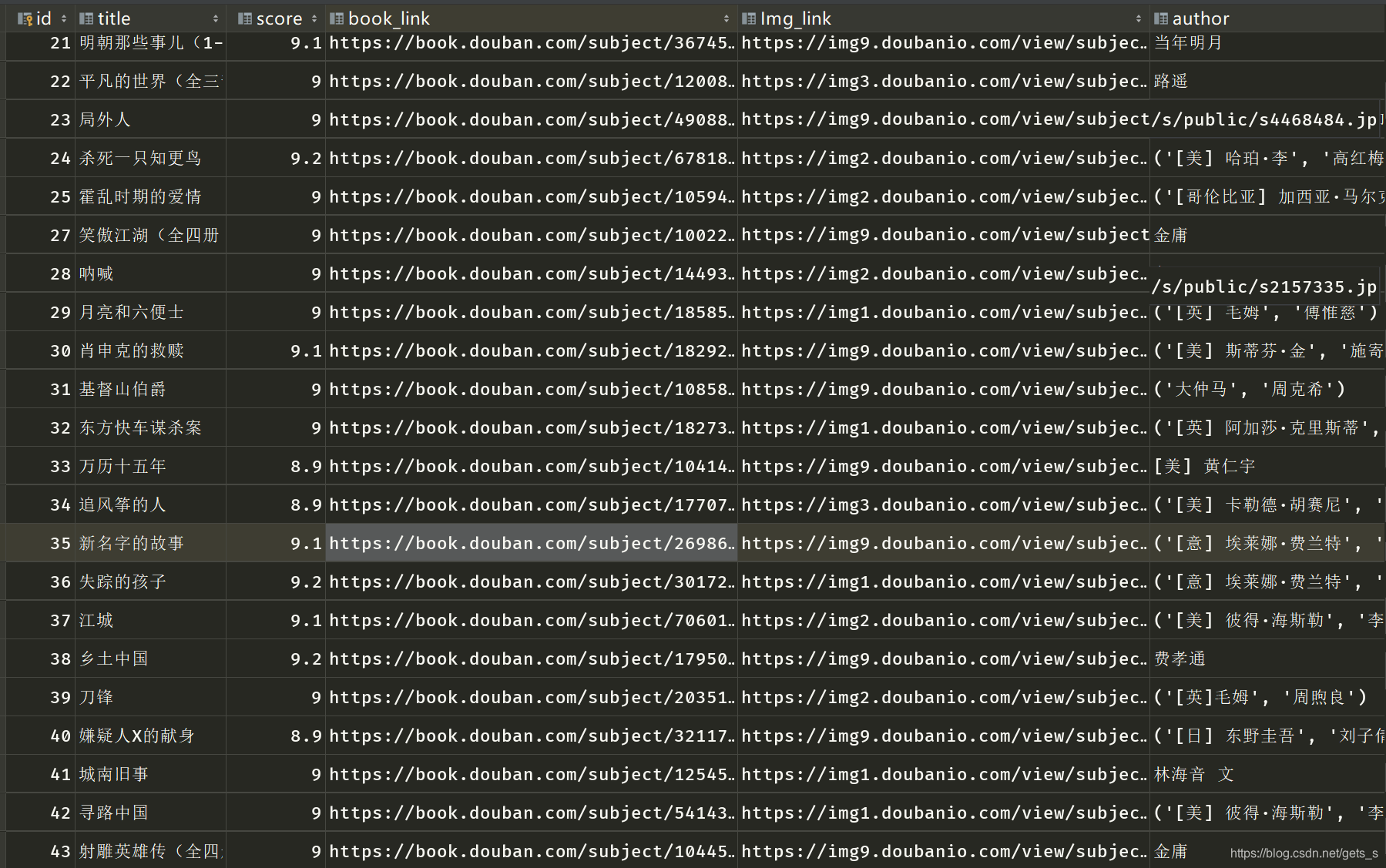
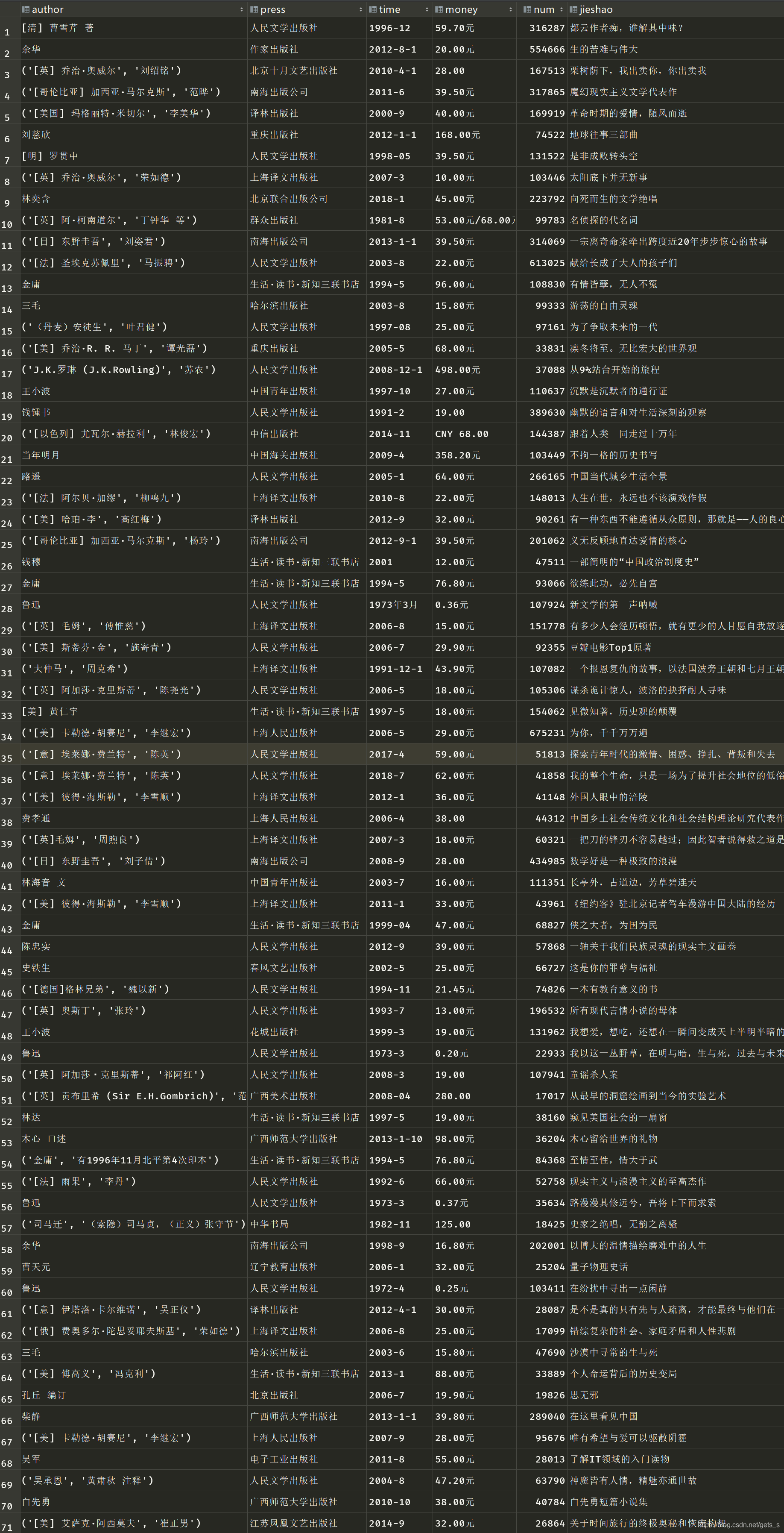
爬取豆瓣读书Top250,导入sqlist数据库(或excel表格)中
获取源代码请访问https://github.com/zhang020801/douban_bookTop250
一、程序源代码
import re #正则表达式
from bs4 import BeautifulSoup #提取数据
import urllib.request,urllib.error #申请访问网页,返回网页源代码
import xlwt #保存数据到excel表格
import sqlite3 #保存数据到sqlist数据库中
def main():
#声明爬取的网页
baseurl = "https://book.douban.com/top250?start="
#获取数据
datalist = getData(baseurl)
#print(datalist)
#保存数据
#savepath = "豆瓣读书Top250.xls"
dbpath = "book.db"
#saveData(datalist,savepath)
saveData2(datalist,dbpath)
#正则表达式
findlink = re.compile(r'<a href="(.*?)" οnclick=".*?" title=".*?">') #图书链接
findtitle = re.compile(r'<a href=".*?" οnclick=".*?" title="(.*?)">') #图书名
findimglink = re.compile(r'<img src="(.*?)" width="90"/>') #封面链接
findauthor = re.compile(r'<p class="pl">(.*?) / (.*?) / .*? / .*?/.*?</p>') #作者/译者
findpress = re.compile(r'<p class="pl">.*? / .*? / (.*?) / .*?/.*?</p>') #出版社
findtime = re.compile(r'<p class="pl">.*? / .*? / .*? / (.*?) / .*?</p>') #出版时间
findmoney = re.compile(r'<p class="pl">.*? / .*? / .*? / .*? / (.*?)</p>') #图书售价
findscore = re.compile(r'<span class="rating_nums">(.*?)</span>') #评分
findpeople = re.compile(r'<span class="pl">.*?(.*?)人评价.*?</span>',re.S) #评价人数
findjieshao = re.compile(r'<span class="inq">(.*?)</span>') #介绍
def getData(baseurl):
datalist = []
for i in range(0,10):
url = baseurl + str(i*25)
html = askURL(url)
#print(html)
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('table',width="100%"):
item = str(item) #转换成str格式
#print(item)
data = []
title = re.findall(findtitle, item)[0]
#print(title)
data.append(title)
score = re.findall(findscore,item)[0]
#print(score)
data.append(score)
link = re.findall(findlink,item)[0]
#print(link)
data.append(link)
imglink = re.findall(findimglink,item)[0]
#print(imglink)
data.append(imglink)
author = re.findall(findauthor,item)
if len(author)==0:
author = re.findall(r'<p class="pl">(.*?) / .*? / .*?</p>',item)
author = author[0]
#print(author)
data.append(author)
press = re.findall(findpress,item)
if len(press)==0:
press = re.findall(r'<p class="pl">.*? / (.*?) / .*? / .*?</p>',item)
if len(press)==0:
press = " "
else:press = press[0]
#print(press)
data.append(press)
time = re.findall(findtime,item)
if len(time)==0:
time = re.findall(r'<p class="pl">.*? / .*? / (.*?) / .*?</p>',item)
if len(time)==0:
time = " "
else:time = time[0]
#print(time)
data.append(time)
money = re.findall(findmoney,item)
if len(money)==0:
money = re.findall(r'<p class="pl">.*? / .*? / .*?/ (.*?)</p>',item)
if len(money)==0:
money = " "
else:money = money[0]
#print(money)
data.append(money)
people = re.findall(findpeople,item)
#people = people[0].replace(" ","")
people = people[0].replace("(\n ","")
#print(people)
data.append(people)
jieshao = re.findall(findjieshao,item)
if len(jieshao)==0:
jieshao = " "
jieshao = jieshao[0]
#print(jieshao)
data.append(jieshao)
datalist.append(data)
return datalist
def askURL(url):
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 80.0.3987.163Safari / 537.36"
}
request = urllib.request.Request(url,headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
def saveData(datalist,savepath):
print("开始保存...")
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = book.add_sheet('豆瓣读书Top250',cell_overwrite_ok=True)
col = ("图书名","评分","图书链接","封面图片链接","作者/译者","出版社","出版时间","售价","评价人数","简要介绍")
for i in range(0,10):
sheet.write(0,i,col[i])
for i in range(0,250):
print("第%d条"%(i+1))
data = datalist[i]
for j in range(0,10):
sheet.write(i+1,j,data[j])
book.save(savepath)
print("保存完成")
def saveData2(datalist,dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
# for index in range(len(data)):
# if index==1 or index==8:
# continue
# else:data[index] = '"' + data[index] + '"'
sql = '''
insert into book250(
title,score,book_link,Img_link,author,press,time,money,num,jieshao)
values ("%s","%s","%s","%s","%s","%s","%s","%s","%s","%s")'''%(data[0],data[1],data[2],data[3],data[4],data[5],data[6],data[7],data[8],data[9])
print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
def init_db(dbpath):
sql = '''
create table book250
(
id integer primary key autoincrement,
title varchar ,
score numeric ,
book_link text,
Img_link text,
author text,
press text,
time text,
money text,
num numeric ,
jieshao text
)
'''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
if __name__ =="__main__":
main()
二、程序运行结果
1)将数据导入到excel表格中
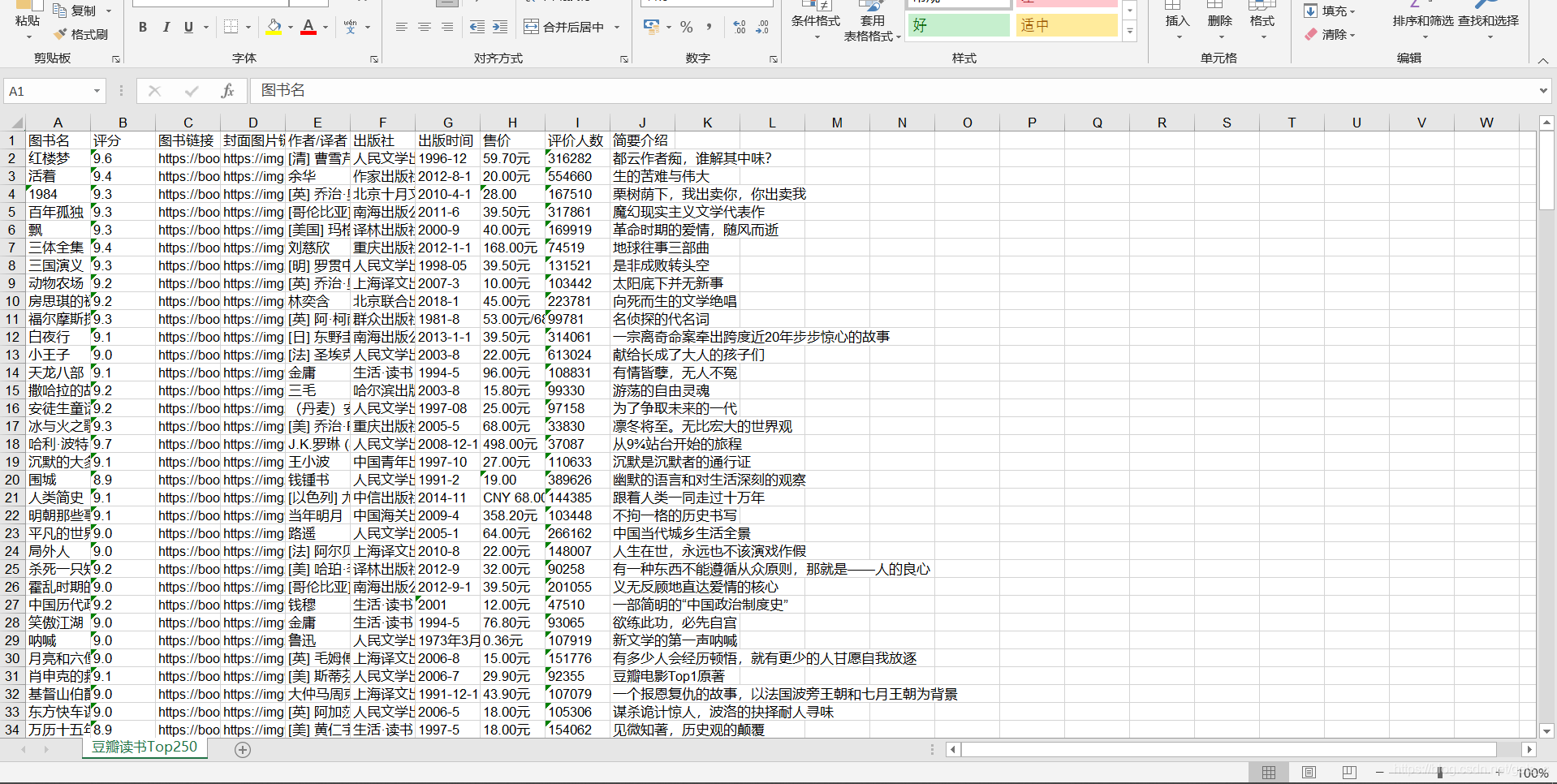
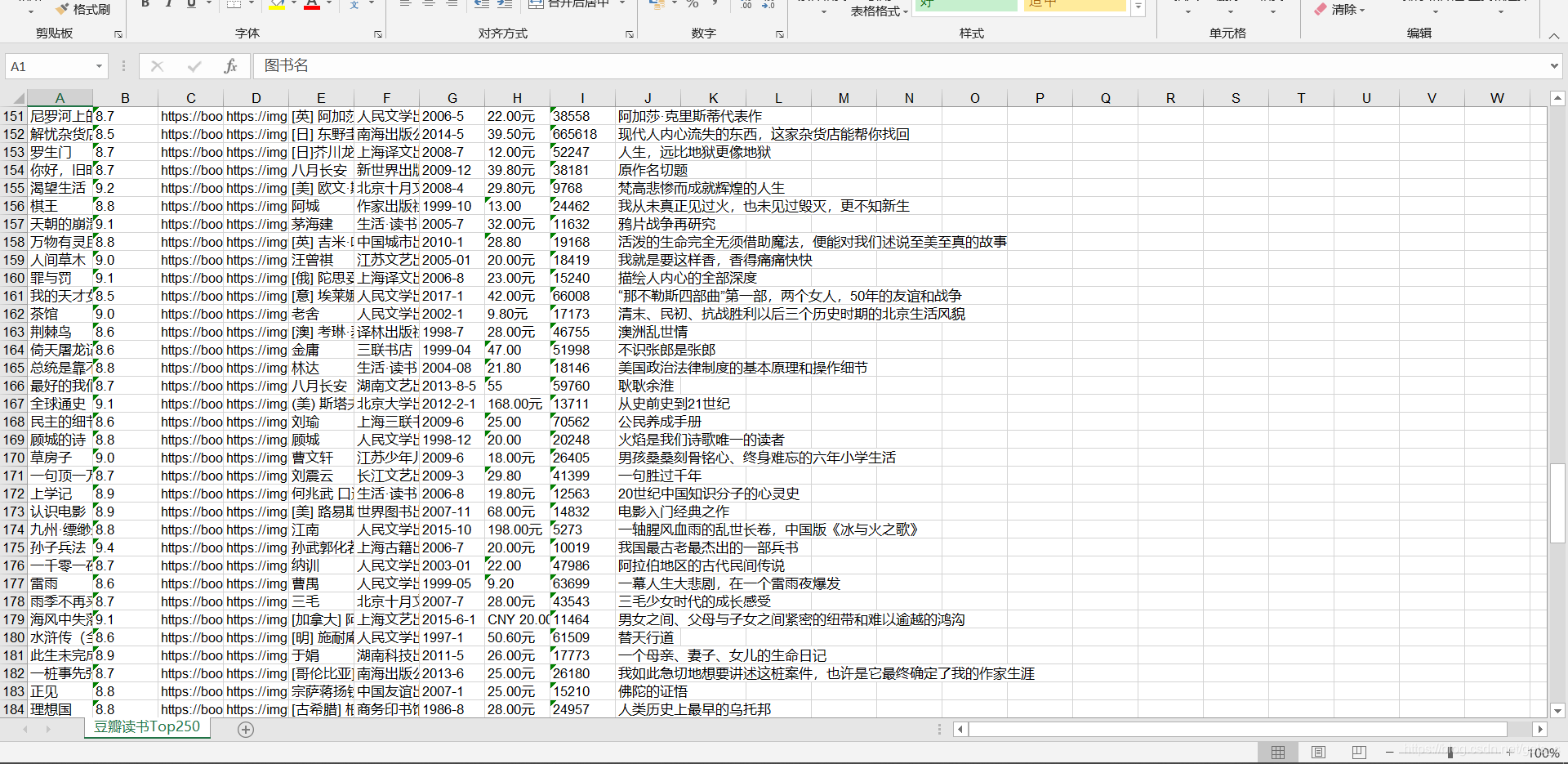
2)将数据导入到sqlist数据库中