一步步使用Java网络爬虫技术实现豆瓣读书Top250数据的爬取,并插入数据库
目录
一步步使用Java网络爬虫技术实现豆瓣读书Top250数据的爬取,并插入数据库
第一步:创建项目,搭建项目结构
这里我们使用IDEA创建一个maven项目。
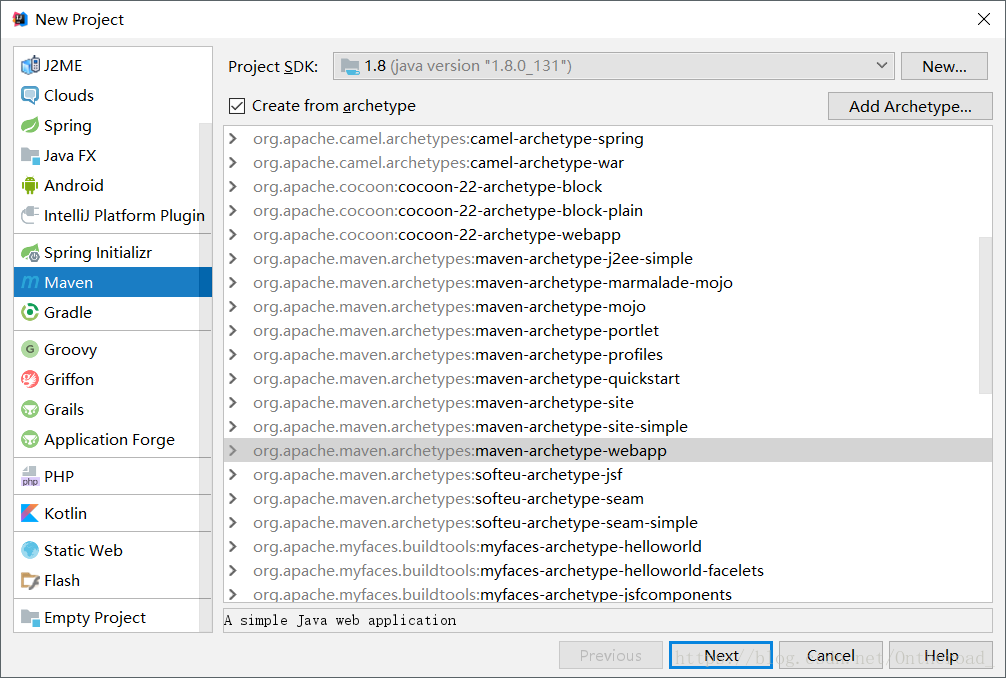
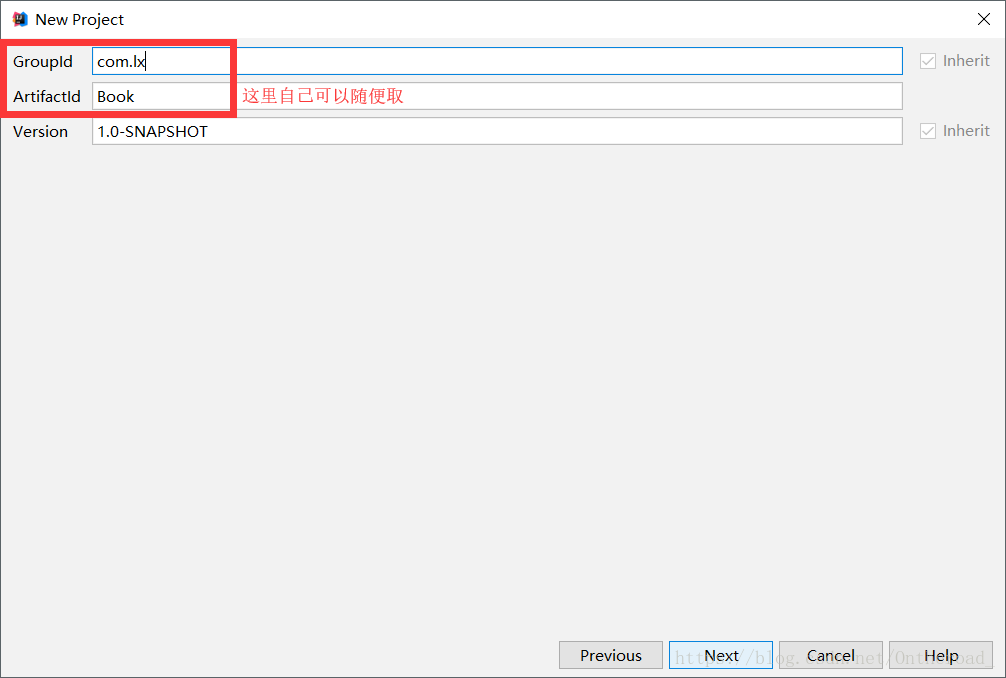
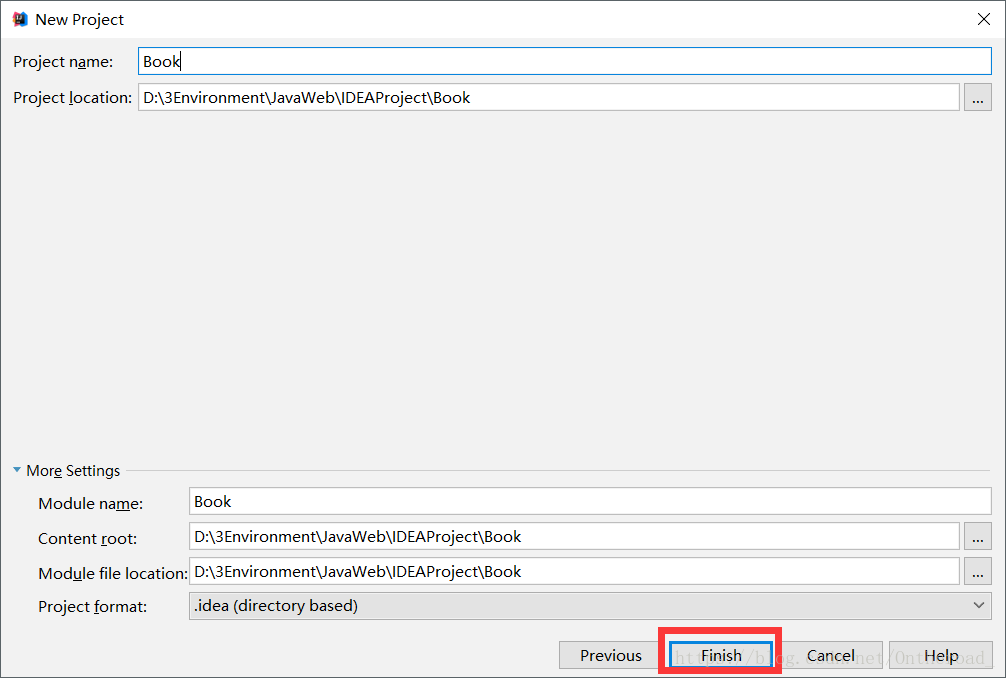
点击Finish后,等IDEA进度条完成。
打开File --> Project Structure --> Modules
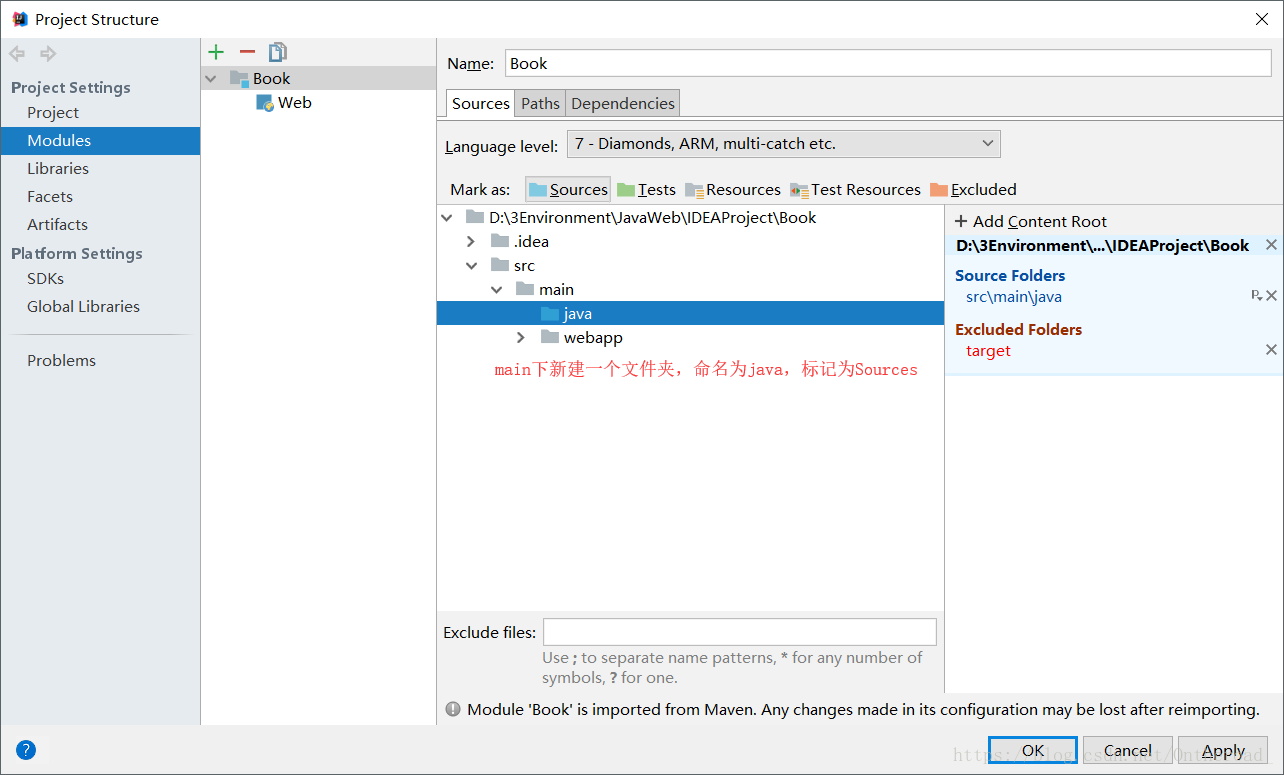
点击apply
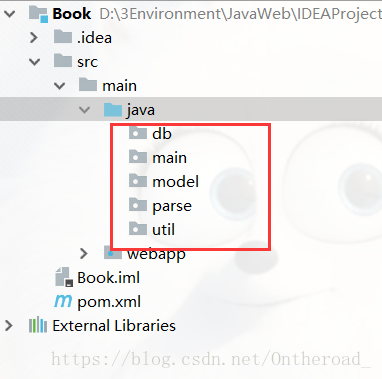
java目录下新建5个包:
pom.xml
引入需要的依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.3.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.8.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-dbcp/commons-dbcp -->
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.2.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-dbutils/commons-dbutils -->
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.5</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>6.0.6</version>
</dependency>
</dependencies>
第二步:编码工作
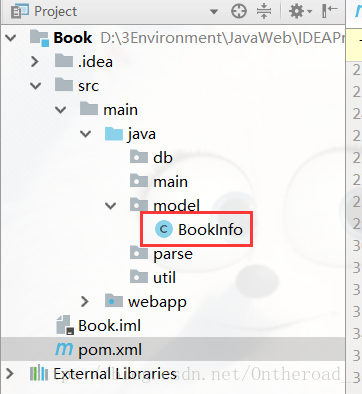
BookInfo
package model;
/**
* @author OnTheRoad_
* @Project: Book
* @Package:model
* @date 2018/9/29 15:44
* @description
**/
public class BookInfo {
private String name;
private String author;
private String publisher; //出版社
private String publishTime; //出版时间
private double rating; //豆瓣评分
public BookInfo() {
}
public BookInfo(String name, String author, String publisher, String publishTime, double rating) {
this.name = name;
this.author = author;
this.publisher = publisher;
this.publishTime = publishTime;
this.rating = rating;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPublisher() {
return publisher;
}
public void setPublisher(String publisher) {
this.publisher = publisher;
}
public String getPublishTime() {
return publishTime;
}
public void setPublishTime(String publishTime) {
this.publishTime = publishTime;
}
public double getRating() {
return rating;
}
public void setRating(double rating) {
this.rating = rating;
}
@Override
public String toString() {
return "BookInfo{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", publisher='" + publisher + '\'' +
", publishTime='" + publishTime + '\'' +
", rating=" + rating +
'}';
}
}
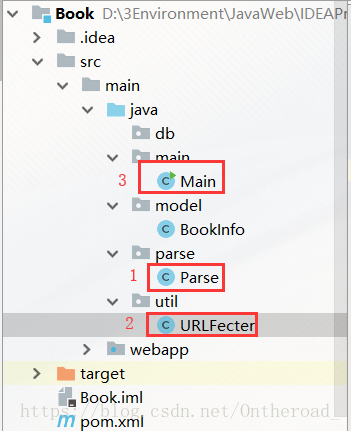
Parse
package parse;
import model.BookInfo;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
/**
* @author OnTheRoad_
* @Project: Book
* @Package:parse
* @date 2018/9/29 16:48
* @description 获取HTML中的图书信息
**/
public class Parse {
public static List<BookInfo> getData(String html) {
//获取的数据,存放在集合中
List<BookInfo> data = new ArrayList<>();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
//获取HTML标签中的内容
Elements elements = doc.select("div[class=indent]").select("table");
for (Element ele : elements){
String name = ele.select("div[class=pl2]").text();
String pubinfo = ele.select("p").text();
//pubinfo:[美] 卡勒德·胡赛尼 / 李继宏 / 上海人民出版社 / 2006-5 / 29.00元
// 作者 / 翻译 / 出版社 /出版时间/价格
// 没有翻译人员的格式:钱锺书 / 人民文学出版社 / 1991-2 / 19.00
String[] infos = pubinfo.split("/");
String ratingStr = ele.select("div[class=star clearfix]").select("span[class=rating_nums]").text();
Double rating = Double.valueOf(ratingStr);
//创建一个对象,这里可以看出,使用Model的优势,直接进行封装
BookInfo book = new BookInfo();
book.setName(name);
book.setAuthor(infos[0]);
book.setPublisher(infos[infos.length-3]);
book.setPublishTime(infos[infos.length-2]);
book.setRating(rating);
//将每一个对象的值,保存到list集合中
data.add(book);
}
//返回数据
return data;
}
}
URLFecter
package util;
import model.BookInfo;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.util.EntityUtils;
import parse.Parse;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* @author OnTheRoad_
* @Project: Book
* @Package:util
* @date 2018/9/29 16:45
* @description
**/
public class URLFecter {
public static List<BookInfo> URLParser(HttpClient client, HttpGet httpGet) throws IOException {
//用来接收解析的数据
List<BookInfo> bookInfos = new ArrayList<>();
//获取网站响应的HTML
HttpResponse response = client.execute(httpGet);
//获取响应状态码
int statusCode = response.getStatusLine().getStatusCode();
//如果状态码为200,则获取HTML实例内容或者json文件
if (statusCode == 200){
String entity = EntityUtils.toString(response.getEntity(),"utf-8");
bookInfos = Parse.getData(entity);
EntityUtils.consume(response.getEntity());
} else {
//否则,消耗掉实体
EntityUtils.consume(response.getEntity());
}
return bookInfos;
}
}
Main
package main;
import model.BookInfo;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import util.URLFecter;
import java.io.IOException;
import java.util.List;
/**
* @author OnTheRoad_
* @Project: Book
* @Package:main
* @date 2018/9/29 16:38
* @description
**/
public class Main {
public static void main(String[] args) throws IOException {
//初始化一个HTTPClient
HttpClient client = new DefaultHttpClient();
//我们要爬取的一个地址,利用循环可以爬取一个URL队列
HttpGet httpGet = new HttpGet("https://book.douban.com/top250?icn=index-book250-all");
//设置header 避免403forbidden
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//抓取数据
List<BookInfo> books = URLFecter.URLParser(client,httpGet);
for (BookInfo book : books){
System.out.println(book.toString());
}
}
}
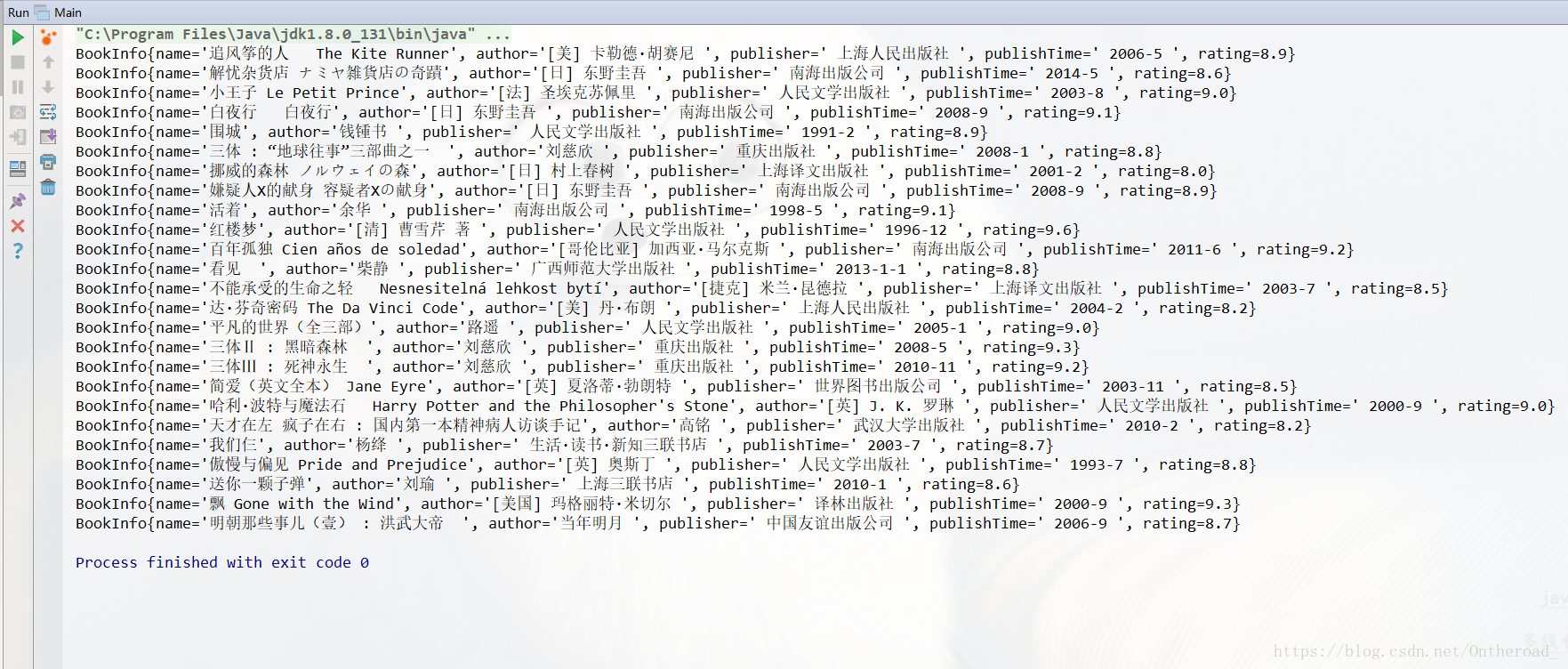
运行main函数结果:
第三步:插入数据库操作
数据库建表Book
/*
Navicat MySQL Data Transfer
Source Server : studyMySQL
Source Server Version : 50718
Source Host : localhost:3306
Source Database : lib
Target Server Type : MYSQL
Target Server Version : 50718
File Encoding : 65001
Date: 2018-09-29 17:45:41
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for `book`
-- ----------------------------
DROP TABLE IF EXISTS `book`;
CREATE TABLE `book` (
`id` int(5) NOT NULL AUTO_INCREMENT,
`name` varchar(200) DEFAULT NULL,
`author` varchar(100) DEFAULT NULL,
`publisher` varchar(100) DEFAULT NULL,
`publish_time` varchar(50) DEFAULT NULL,
`rating` float(4,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of book
-- ----------------------------
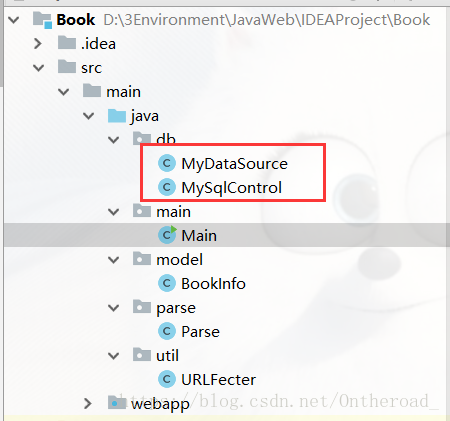
MyDataSource
package db;
import org.apache.commons.dbcp.BasicDataSource;
import javax.sql.DataSource;
/**
* @author OnTheRoad_
* @Project: Book
* @Package:db
* @date 2018/9/29 11:50
* @description
**/
public class MyDataSource {
public static DataSource getDataSource(String connectURL){
BasicDataSource ds = new BasicDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUsername("root");
ds.setPassword("123456");
ds.setUrl(connectURL);
return ds;
}
}
MySqlControl
package db;
import model.BookInfo;
import org.apache.commons.dbutils.QueryRunner;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.List;
/**
* @author OnTheRoad_
* @Project: Book
* @Package:db
* @date 2018/9/29 11:50
* @description
**/
public class MySqlControl {
static DataSource ds = MyDataSource.getDataSource("jdbc:mysql://127.0.0.1:3306/lib?serverTimezone=UTC");
static QueryRunner qr = new QueryRunner(ds);
//第一类方法
public static void executeUpdate(String sql){
try {
qr.update(sql);
} catch (SQLException e) {
e.printStackTrace();
}
}
//度二类方法
public static void executeInsert(List<BookInfo> bookInfos) throws SQLException {
/**
* 定义一个Object数组,列行
* 3表示列数,根据自己的数据定义这里面的数字
* params[i][0]等是堆数组赋值,这里用到集合的get方法
*/
Object[][] params = new Object[bookInfos.size()][5];
for (int i = 0; i < params.length; i++){
params[i][0] = bookInfos.get(i).getName();
params[i][1] = bookInfos.get(i).getAuthor();
params[i][2] = bookInfos.get(i).getPublisher();
params[i][3] = bookInfos.get(i).getPublishTime();
params[i][4] = bookInfos.get(i).getRating();
}
qr.batch("insert into book(id,name,author,publisher,publish_time,rating) values(null,?,?,?,?,?)",params);
System.out.println("执行数据库完毕:"+"成功插入数据:"+bookInfos.size()+"条");
}
}
修改Main.java
package main;
import db.MySqlControl;
import model.BookInfo;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import util.URLFecter;
import java.io.IOException;
import java.sql.SQLException;
import java.util.List;
/**
* @author OnTheRoad_
* @Project: Book
* @Package:main
* @date 2018/9/29 16:38
* @description
**/
public class Main {
public static void main(String[] args) throws IOException, SQLException {
//初始化一个HTTPClient
HttpClient client = new DefaultHttpClient();
//我们要爬取的一个地址,利用循环可以爬取一个URL队列
HttpGet httpGet = new HttpGet("https://book.douban.com/top250?icn=index-book250-all");
//设置header 避免403forbidden
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//抓取数据
List<BookInfo> books = URLFecter.URLParser(client,httpGet);
for (BookInfo book : books){
System.out.println(book.toString());
}
MySqlControl.executeInsert(books);
}
}
运行main
控制台:
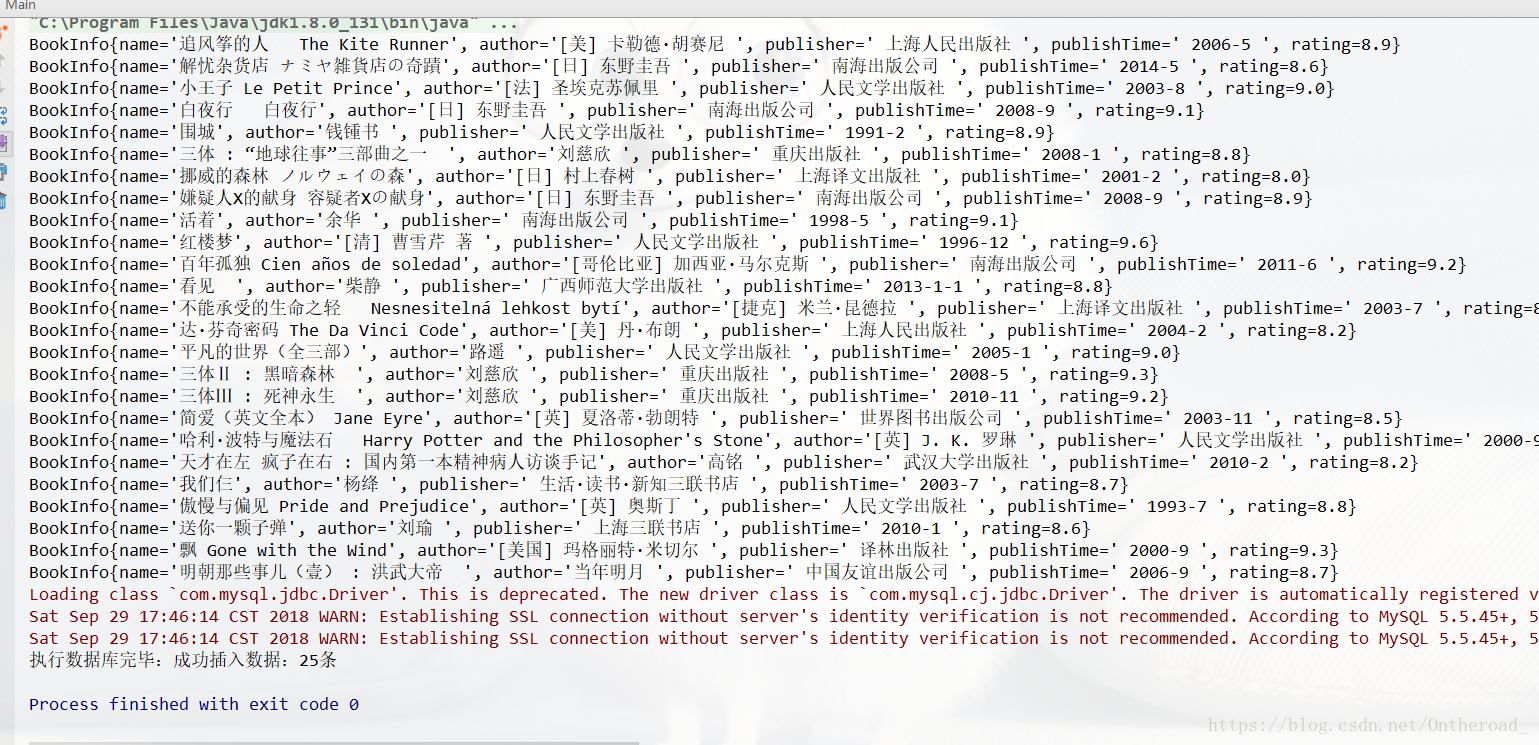
查看数据库
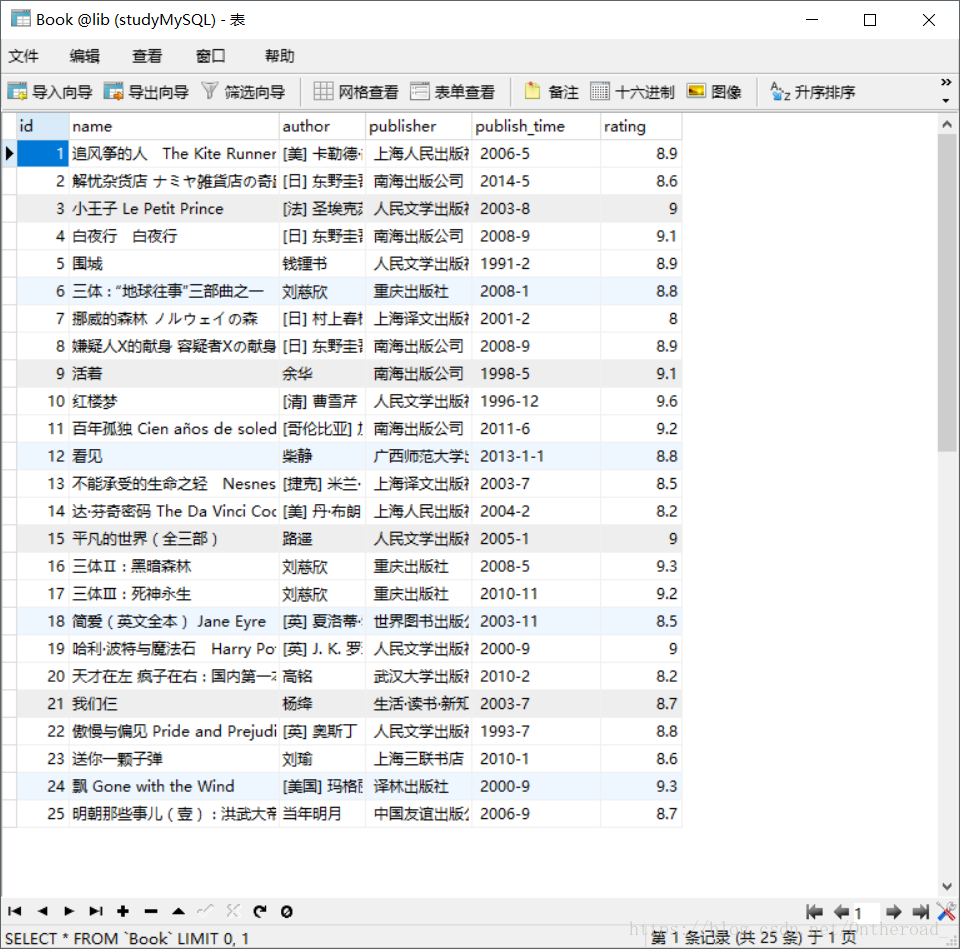
第四步:扩展
将豆瓣读书Top250全插入数据库
分析:
豆瓣Top250
第一页url:https://book.douban.com/top250?icn=index-book250-all
第二页url:https://book.douban.com/top250?start=25
第三页url:https://book.douban.com/top250?start=50
...
第十页url:https://book.douban.com/top250?start=225修改Main.java
package main;
import db.MySqlControl;
import model.BookInfo;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import util.URLFecter;
import java.io.IOException;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
/**
* @author OnTheRoad_
* @Project: Book
* @Package:main
* @date 2018/9/29 16:38
* @description
**/
public class Main {
public static void main(String[] args) throws IOException, SQLException {
//初始化一个HTTPClient
HttpClient client = new DefaultHttpClient();
//集合保存数据
List<BookInfo> books = new ArrayList<>();
//我们要爬取的一个地址,利用循环可以爬取一个URL队列
for (int i = 1; i < 10; i++){
HttpGet httpGet = new HttpGet("https://book.douban.com/top250?start="+i*25);
//设置header 避免403forbidden
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
//抓取数据,加入到集合中
books.addAll(URLFecter.URLParser(client,httpGet));
}
// for (BookInfo book : books){
// System.out.println(book.toString());
// }
MySqlControl.executeInsert(books);
}
}
运行main
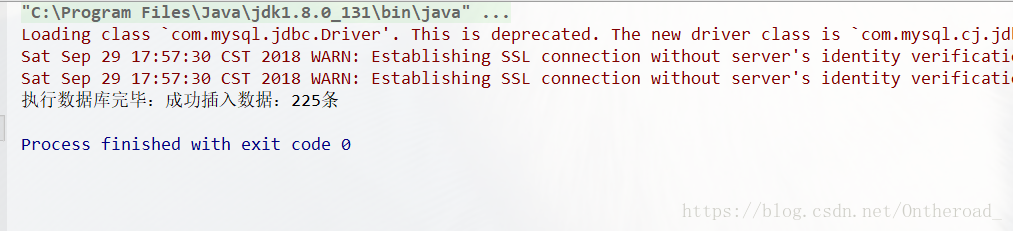
完成
文章参考:https://blog.csdn.net/qy20115549/article/details/52203722