自己定义模型
测试:
correct = 0
total = 0
for data in test_loader:
img,label = data
outputs = net(Variable(img))
_,predict = torch.max(outputs.data,1)
total += label.size(0)
correct += (predict == label).sum()
print(str(predict)+','+str(label))
print(100*correct/total)
输出:

预测错误还是挺大的,居然全是1
完整代码:
```python
import torch.nn.functional as F
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import transforms
from torch.utils.data.dataset import Dataset
from torch.utils.data.dataloader import DataLoader
from PIL import Image
import torch.optim as optim
import os
# ***************************初始化一些函数********************************
# torch.cuda.set_device(gpu_id)#使用GPU
learning_rate = 0.0001 # 学习率的设置
# *************************************数据集的设置****************************************************************************
root = os.getcwd() + '\\data\\' # 数据集的地址
# 定义读取文件的格式
def default_loader(path):
return Image.open(path).convert('RGB')
class MyDataset(Dataset):
# 创建自己的类: MyDataset,这个类是继承的torch.utils.data.Dataset
# ********************************** #使用__init__()初始化一些需要传入的参数及数据集的调用**********************
def __init__(self, txt, transform=None, target_transform=None,test = False,loader=default_loader):
super(MyDataset, self).__init__()
# 对继承自父类的属性进行初始化
imgs = []
fh = open(txt, 'r')
# 按照传入的路径和txt文本参数,以只读的方式打开这个文本
for line in fh: # 迭代该列表#按行循环txt文本中的内
line = line.strip('\n')
line = line.rstrip('\n')
# 删除 本行string 字符串末尾的指定字符,这个方法的详细介绍自己查询python
words = line.split()
# 用split将该行分割成列表 split的默认参数是空格,所以不传递任何参数时分割空格
imgs.append((words[0], int(words[1])))
# 把txt里的内容读入imgs列表保存,具体是words几要看txt内容而定
# 很显然,根据我刚才截图所示txt的内容,words[0]是图片信息,words[1]是lable
self.test = test
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
# *************************** #使用__getitem__()对数据进行预处理并返回想要的信息**********************
def __getitem__(self, index): # 这个方法是必须要有的,用于按照索引读取每个元素的具体内容
fn, label = self.imgs[index]
if self.test is False:
# fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[1]的信息
img_path = os.path.join("C:\\Users\\pic\\train", fn)
else:
img_path = os.path.join("C:\\Users\\pic\\test", fn)
img = Image.open(img_path).convert('RGB')
# 按照路径读取图片
if self.transform is not None:
img = self.transform(img)
# 数据标签转换为Tensor
return img, label
# return回哪些内容,那么我们在训练时循环读取每个batch时,就能获得哪些内容
# ********************************** #使用__len__()初始化一些需要传入的参数及数据集的调用**********************
def __len__(self):
# 这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分
return len(self.imgs)
class Net(nn.Module): # 定义网络,继承torch.nn.Module
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 卷积层
self.pool = nn.MaxPool2d(2, 2) # 池化层
self.conv2 = nn.Conv2d(6, 16, 5) # 卷积层
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接层
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 2) # 2个输出
def forward(self, x): # 前向传播
x = self.pool(F.relu(self.conv1(x))) # F就是torch.nn.functional
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5) # .view( )是一个tensor的方法,使得tensor改变size但是元素的总数是不变的。
# 从卷基层到全连接层的维度转换
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
IMG_MEAN = [0.485, 0.456, 0.406]
IMG_STD = [0.229, 0.224, 0.225]
net = Net() # 初始化一个卷积神经网络leNet-
train_data = MyDataset(txt=root + 'num.txt', transform=transforms.Compose([
transforms.RandomHorizontalFlip(), # 水平翻转
transforms.Resize((32, 32)),
# 将图片缩放到指定大小(h,w)或者保持长宽比并缩放最短的边到int大小
transforms.CenterCrop(32),
transforms.ToTensor()])
)
test_data = MyDataset(txt=root+'test.txt', transform=transforms.Compose([
transforms.Resize((32, 32)),
# 将图片缩放到指定大小(h,w)或者保持长宽比并缩放最短的边到int大小
transforms.CenterCrop(32),
transforms.ToTensor()]),test=True)
train_loader = DataLoader(dataset=train_data, batch_size=227, shuffle=True,drop_last=True)
# batch_size:从样本中取多少张,每一次epoch都会输入batch_size张
print('num_of_trainData:', len(train_data))
test_loader = DataLoader(dataset=test_data, batch_size=19, shuffle=False)
def trainandsave():
# 神经网络结构
print('h')
net = Net()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 学习率为0.001
criterion = nn.CrossEntropyLoss() # 损失函数也可以自己定义,我们这里用的交叉熵损失函数
# 训练部分
for epoch in range(10): # 训练的数据量为10个epoch,每个epoch为一个循环
# 每个epoch要训练所有的图片,每训练完成200张便打印一下训练的效果(loss值)
running_loss = 0.0 # 定义一个变量方便我们对loss进行输出
for i, data in enumerate(train_loader, 0): # 这里我们遇到了第一步中出现的trailoader,代码传入数据
# enumerate是python的内置函数,既获得索引也获得数据
# get the inputs
inputs, labels = data # data是从enumerate返回的data,包含数据和标签信息,分别赋值给inputs和labels
# wrap them in Variable
inputs, labels = Variable(inputs), Variable(labels) # # 转换数据格式用Variable
optimizer.zero_grad() # 梯度置零,因为反向传播过程中梯度会累加上一次循环的梯度
# forward + backward + optimize
outputs = net(inputs) # 把数据输进CNN网络net
loss = criterion(outputs, labels) # 计算损失值
loss.backward() # loss反向传播
optimizer.step() # 反向传播后参数更新
running_loss += loss.item() # loss累加
if i % 9 == 1:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 10)) # 平均损失值
running_loss = 0.0 # 这一个结束后,就把running_loss归零,
print('Finished Training')
# 保存神经网络
torch.save(net, 'net.pkl')
# 保存整个神经网络的结构和模型参数
torch.save(net.state_dict(), 'net_params.pkl')
尝试运行vgg16:
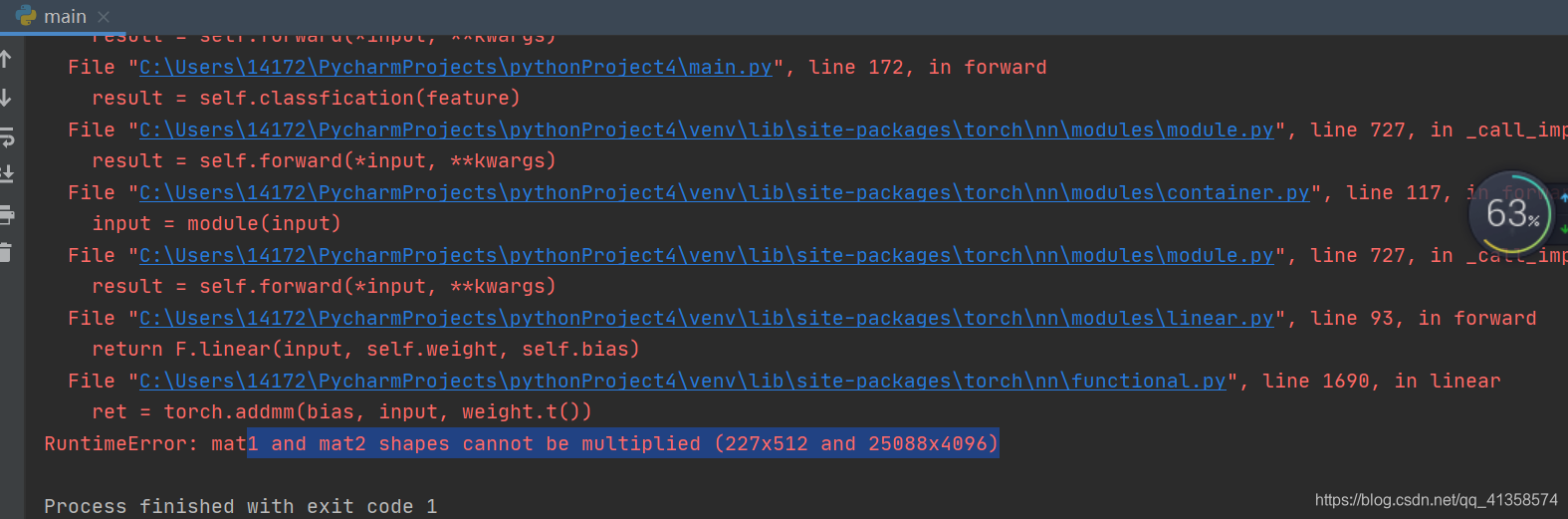
找了很久,预测是参数的问题,输入图片是224*224,一开始改的resize但还是报错,于是改
transforms.CenterCrop((224, 224))
然后data[0]要改成item()
然后运行成功了(好慢。。)
class VGG16(nn.Module):
def __init__(self, nums=2):
super(VGG16, self).__init__()
self.nums = nums
vgg = []
# 第一个卷积部分
# 112, 112, 64
vgg.append(nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.MaxPool2d(kernel_size=2, stride=2))
# 第二个卷积部分
# 56, 56, 128
vgg.append(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.MaxPool2d(kernel_size=2, stride=2))
# 第三个卷积部分
# 28, 28, 256
vgg.append(nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.MaxPool2d(kernel_size=2, stride=2))
# 第四个卷积部分
# 14, 14, 512
vgg.append(nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.MaxPool2d(kernel_size=2, stride=2))
# 第五个卷积部分
# 7, 7, 512
vgg.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1))
vgg.append(nn.ReLU())
vgg.append(nn.MaxPool2d(kernel_size=2, stride=2))
# 将每一个模块按照他们的顺序送入到nn.Sequential中,输入要么事orderdict,要么事一系列的模型,遇到上述的list,必须用*号进行转化
self.main = nn.Sequential(*vgg)
# 全连接层
classfication = []
# in_features四维张量变成二维[batch_size,channels,width,height]变成[batch_size,channels*width*height]
classfication.append(nn.Linear(in_features=512 * 7 * 7, out_features=4096)) # 输出4096个神经元,参数变成512*7*7*4096+bias(4096)个
classfication.append(nn.ReLU())
classfication.append(nn.Dropout(p=0.5))
classfication.append(nn.Linear(in_features=4096, out_features=4096))
classfication.append(nn.ReLU())
classfication.append(nn.Dropout(p=0.5))
classfication.append(nn.Linear(in_features=4096, out_features=self.nums))
self.classfication = nn.Sequential(*classfication)
def forward(self, x):
feature = self.main(x) # 输入张量x
feature = feature.view(x.size(0), -1) # reshape x变成[batch_size,channels*width*height]
#feature = feature.view(-1,116224)
result = self.classfication(feature)
return result
net = Net() # 初始化一个卷积神经网络leNet-
train_data = MyDataset(txt=root + 'num.txt', transform=transforms.Compose([
transforms.RandomHorizontalFlip(), # 水平翻转
transforms.Resize((224, 224)),
# 将图片缩放到指定大小(h,w)或者保持长宽比并缩放最短的边到int大小
transforms.CenterCrop((224, 224)),
transforms.ToTensor()])
)
test_data = MyDataset(txt=root+'test.txt', transform=transforms.Compose([
transforms.Resize((32, 32)),
# 将图片缩放到指定大小(h,w)或者保持长宽比并缩放最短的边到int大小
transforms.CenterCrop(32),
transforms.ToTensor()]),test=True)
train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True,drop_last=True)
# batch_size:从样本中取多少张,每一次epoch都会输入batch_size张
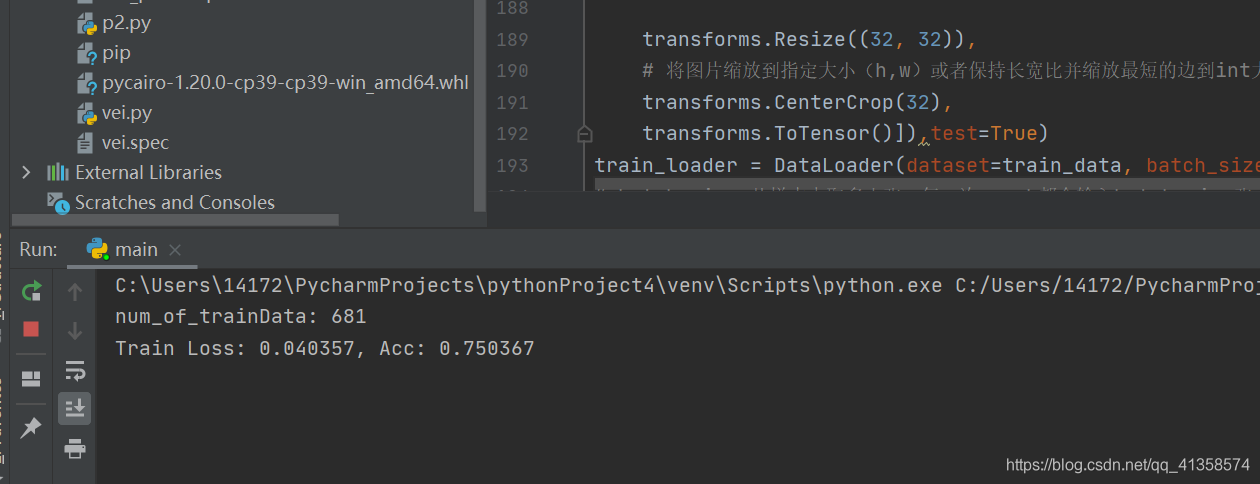
print('num_of_trainData:', len(train_data))
test_loader = DataLoader(dataset=test_data, batch_size=19, shuffle=False)
if __name__ == '__main__':
# trainandsave()
vgg = VGG16()
#vgg = VGG16(2)
optimizer = optim.SGD(vgg.parameters(), lr=0.001, momentum=0.9) # 学习率为0.001
criterion = nn.CrossEntropyLoss() # 损失函数也可以自己定义,我们这里用的交叉熵损失函数
# 训练部分
for epoch in range(10): # 训练的数据量为10个epoch,每个epoch为一个循环
# 每个epoch要训练所有的图片,每训练完成200张便打印一下训练的效果(loss值)
running_loss = 0.0 # 定义一个变量方便我们对loss进行输出
train_loss = 0.
train_acc = 0.
for i, data in enumerate(train_loader, 0): # 这里我们遇到了第一步中出现的trailoader,代码传入数据
# enumerate是python的内置函数,既获得索引也获得数据
# get the inputs
inputs, labels = data # data是从enumerate返回的data,包含数据和标签信息,分别赋值给inputs和labels
# wrap them in Variable
inputs, labels = Variable(inputs), Variable(labels) # # 转换数据格式用Variable
optimizer.zero_grad() # 梯度置零,因为反向传播过程中梯度会累加上一次循环的梯度
# forward + backward + optimize
outputs = vgg(inputs) # 把数据输进CNN网络net
loss = criterion(outputs, labels) # 计算损失值
train_loss += loss.item()
pred = torch.max(outputs, 1)[1]
train_correct = (pred == labels).sum()
train_acc += train_correct.item()
loss.backward() # loss反向传播
optimizer.step() # 反向传播后参数更新
running_loss += loss.item() # loss累加
print('Train Loss: {:.6f}, Acc: {:.6f}'.format(train_loss / (len(
train_data)), train_acc / (len(train_data))))
print('Finished Training')
# 保存神经网络
torch.save(net, 'net.pkl')
# 保存整个神经网络的结构和模型参数
torch.save(net.state_dict(), 'net_params.pkl')
尝试将损失函数修改:
optimizer = optim.Adam(vgg.parameters(), lr=1e-6) # 学习率为0.001

结果仍然不理想。怀疑是数据集有过大误差。
载入已有模型进行参数优化
两个主要的迁移学习场景:
Finetuning the convnet: 我们使用预训练网络初始化网络,而不是随机初始化,就像在imagenet 1000数据集上训练的网络一样。其余训练看起来像往常一样。(此微调过程对应引用中所说的初始化)
ConvNet as fixed feature extractor: 在这里,我们将冻结除最终完全连接层之外的所有网络的权重。最后一个全连接层被替换为具有随机权重的新层,并且仅训练该层。(此步对应引
用中的固定特征提取器
用加载预训练模型并重置最终的全连接层的方法进行训练。
每一个epoch都进行训练和测试。我写的是resnet18(先自己网上下载pkl文件,在pycharm里面下载太慢)
目前的全部代码:
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
import torchvision.models as models
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir =os.getcwd() + '\\data\\'
image_datasets = {
x: datasets.ImageFolder(os.path.join(data_dir, x),data_transforms[x]) for x in ['train', 'val']}
dataloaders = {
x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,shuffle=True) for x in ['train', 'val']}
dataset_sizes = {
x: len(image_datasets[x]) for x in ['train', 'val']}
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
model.train() # Set model to training mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
# zero the parameter gradients
optimizer.zero_grad()
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_,preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
# backward + optimize only if in training phase
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
# load best model weights
model.load_state_dict(best_model_wts)
return model
class_names = image_datasets['train'].classes
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['val']):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images // 2, 2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names[preds[j]]))
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
model_ft = models.resnet18(pretrained=False)
pthfile = r'C:\Users\14172\PycharmProjects\pythonProject4\resnet18-5c106cde.pth'
model_ft.load_state_dict(torch.load(pthfile))
#model_ft = models.vgg16(pretrained=True)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, 2)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,num_epochs=25)
# 保存神经网络
torch.save(model_ft, 'modefresnet.pkl')
# 保存整个神经网络的结构和模型参数
torch.save(model_ft.state_dict(), 'modelresnet_params.pkl')
visualize_model(model_ft)
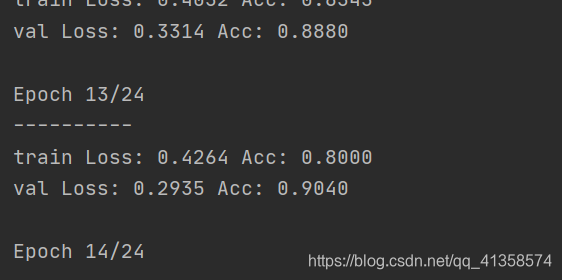
两者差距还是比较大,后期再进行调整。先记录。