ResNet18-Pokemon分类项目:
1.ResNet18简介
深度学习发展到现在已经取得了非常引人注目的成果,那么在处于世界认知前沿的大佬们开始担忧未来人工智能对人类的反噬,这种担忧是具有一定前瞻性的,但是解放劳动力是科技发展的不断追求。
从一开始的LeNet5非常简单的网络模型到现在GoogLeNet(也叫谷歌LeNet,由谷歌的人工智能团队开发,为了向LeNet5致敬,取名GoogLeNet)达到了22层,人们一直在探索加深网路层数是不是可以提高model的performance,事实并不是这样的,实际上大多数网络模型发现在网络层数超过22层的时候,其整体的运算效率和performance会下降很多,也就是退化现象(Degradation),也就证明了并不是一味的加深网络层数提高网络复杂度就可以相应提高网络的performance。
后来微软亚洲研究院的何恺明等人提出了ResNet模型,其想法可以说是非常简单,就是引入残差模块,说的简单一点就是在输入和输出之间加了一条shortcut,也就是我的网络模型既可以走conv层我也可以通过shortcut直接到输出层:示意图
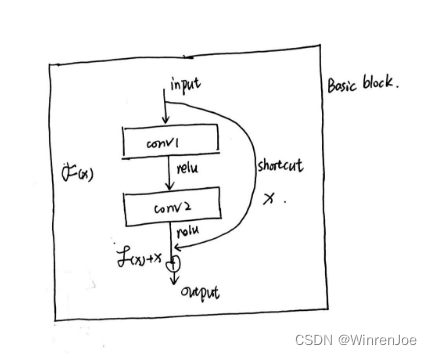
那么每一个basic-block包含2个conv层和一个short-cut,那么在搭建ResNet18的时候每个residence-block会包含2个basic-block,按照ResNet18的网络结构说明可得上述说法。如图:
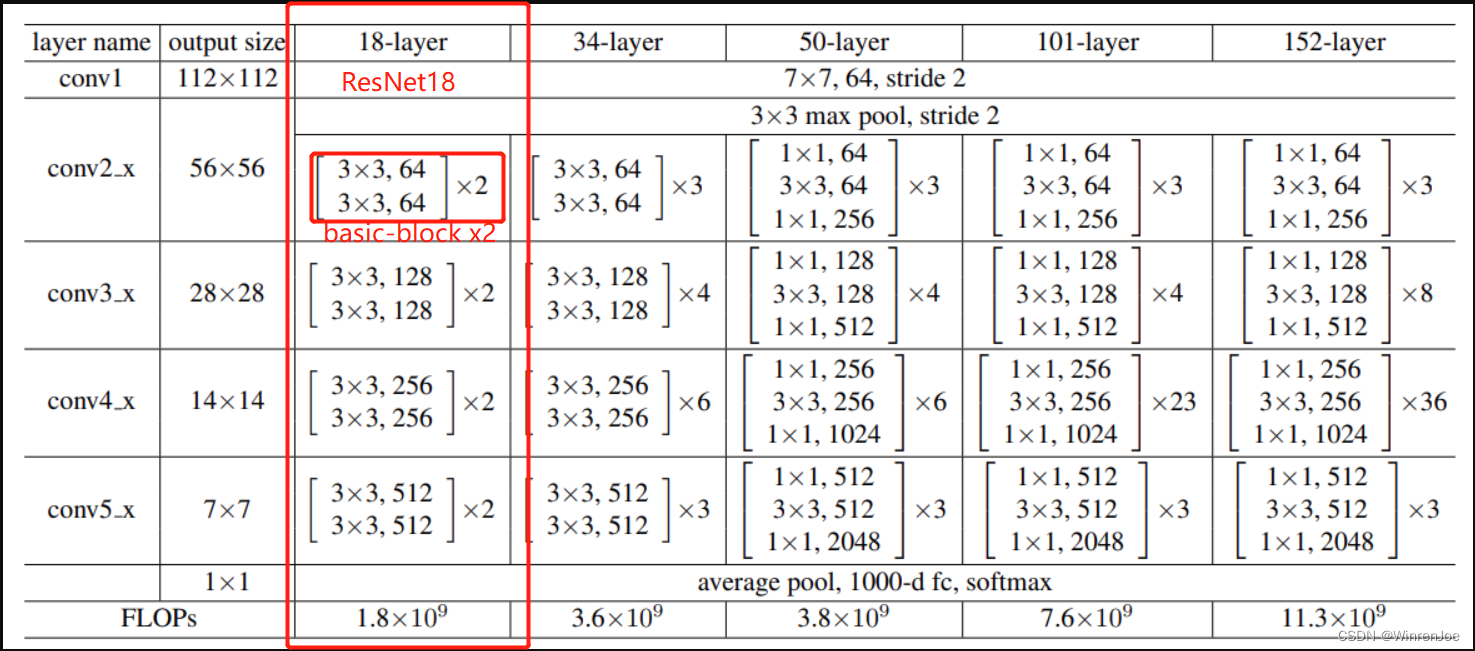
从这个说明表中可以得到ResNet18一共是需要4个Residence Block每一个Block包含两个basic-block,而每一个basic-block包含两个conv层(这里就不算activation、batch Normalization、maxpool或者avgpool等)也就是说Residence的conv层一共有: 2 × 2 × 4 = 16 2\times2\times4=16 2×2×4=16层,再加上一开始的输入层的conv1(用来size-adjusting),最后包含一个fully-connection(fc层)一共: 16 + 1 + 1 = 18 16+1+1=18 16+1+1=18层:如下图:
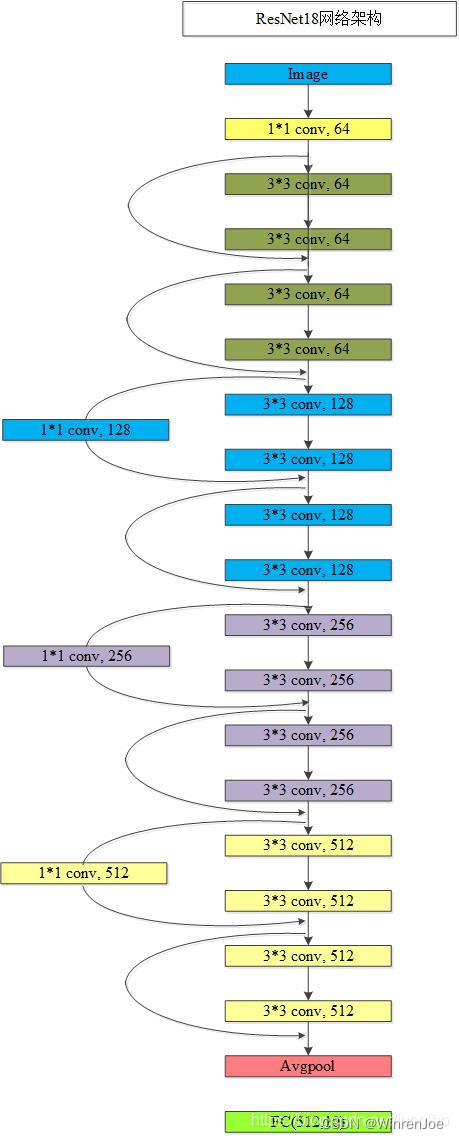
接下来到了拨乱返正的时候了,现在流传的很多关于ResNet18做Pokemon分类用来深度学习入门的示例,但是事实上他们搭建的网络根本就不是ResNet18,因为他们搭建网络层数只有10层,其错误在于:他们没有注意到每一个Residence Block需要包含两个相同的basic-block, 在他们的代码中很好的写出来了basic-block:两个conv,一个shortcut,但在搭建网络的时候直接把basic-bock当成了Residence Block,搭建了一个只有4个basic-block组成的mini-resnet,而这个mini-resnet根本就不会是18层,而是10层(譬如:这几个:
https://blog.csdn.net/weixin_51182518/article/details/113547994
https://blog.csdn.net/weixin_41391619/article/details/105068590
https://www.freesion.com/article/39581512405/等
)当然还有都是一抄百抄,结果发现抄错了!哈哈。
下面拨乱返正版开始!
2.自定义Pokemon数据集
Pytorch自定义数据集需要继承自pytorch的Dataset,下面的自定义数据集模式适合于:标准两级目录:即文件名为label,文件内容为对应该label下的data:且python的project和data在同一个root目录下
import torch
import os, glob
import random, csv
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
# 自定义数据集
class Pokemon(Dataset):
def __init__(self, root, resize, mode): # root is the data_path, resize is the input imgsize of your nueral-net
super(Pokemon,self).__init__()
self.root = root # 路径
self.resize = resize # 数据尺寸
self.name2label = {
} # "squencial":0 加载本目录下的文件,文件名以各自的label命名,谁先加载进来谁标记为0
for name in sorted(os.listdir((os.path.join(root)))): # 将root根目录下的所有文件名遍历一下
if not os.path.isdir(os.path.join(root, name)): # lsitdir 可能返回的顺序不固定 因此加sorted可以让顺序固定下来
continue
self.name2label[name] = len(self.name2label.keys())
# print(self.name2label)
self.images, self.labels = self.load_csv('images.csv')
# img crop
if mode=='train': # 60%
self.images = self.images[:int(0.6*len(self.images))]
self.labels = self.labels[:int(0.6*len(self.labels))]
elif mode == 'val': # 20%
self.images = self.images[int(0.6 * len(self.images)):int(0.8 * len(self.images))]
self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
else: # test_set 80%-100%
self.images = self.images[int(0.8 * len(self.images)):]
self.labels = self.labels[int(0.8 * len(self.labels)):]
# image, label
def load_csv(self, filename):
if not os.path.exists(os.path.join(self.root, filename)): # 如果根目录下不存在该CSV文件 就遍历创建
# 如果存在直接读取
images = []
for name in self.name2label.keys(): # 将所有的图片加载到images中去,图片所对应的类别用路径进行区分
images += glob.glob(os.path.join(self.root, name, '*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
# images += glob.glob(os.path.join(self.root, name, '*.tiff'))
# 1167 pokemon\\bulbasaur\\00000000.png
print(len(images), images)
random.shuffle(images)
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images:
name = img.split(os.sep)[-2] #pokemon[-3]\\bulbasaur [-2]\\00000000.png [-1]
label = self.name2label[name]
writer.writerow([img, label])
print('written into csv file:', filename)
# read from csv file
images, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
img, label = row # 因为CSV文件保存的时候是将路径喝标签同时写入一行,路径与标签之间用逗号隔开,所以
label = int(label) # img, label = row, 得到的是img赋值为路径,label赋值为标签
images.append(img)
labels.append(label)
assert len(images) == len(labels)
return images, labels
def __len__(self):
#return len(self.samples)
return len(self.images)
def denormalize(self, x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
#x_hat = (x-mean)/std 标准化 放缩到均值为0 标准差为1 mu=0 sigma = 1
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
x = x_hat * std + mean
return x
def __getitem__(self, idx): # 获得当前项
# idx~[0~len(images)]
# return self.samples[idx]
# self.images 保存了所有图片的路径信息, self.labels 保存了所有图片的label信息
img, label = self.images[idx], self.labels[idx]
tf = transforms.Compose([
lambda x:Image.open(x).convert('RGB'), # string path => image data 将图像路径转为实际图像
transforms.Resize((int(self.resize*1.25), int(self.resize*1.25))),
transforms.RandomRotation(15), # 如果rotate的角度过大的话可能导致网络不收敛
transforms.CenterCrop(self.resize), # 中心裁剪 让旋转之后的图片不至于用黑色填充
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img = tf(img)
label = torch.tensor(label)
return img, label
def main():
import visdom
import time
viz = visdom.Visdom()
db = Pokemon('pokemon', 224, 'train')
x, y = next(iter(db))
print('sample:', x.shape, y.shape, 'dsada', y)
viz.image(db.denormalize(x), win='sample_x', opts = dict(title='sample_x'))
loader = DataLoader(db, batch_size=32, shuffle=True)
# n = 0
for x, y in loader:
# n += 1
viz.images(db.denormalize(x), nrow=8, win='batch', opts=dict(title='batch'))
viz.text(str(y.numpy()), win='label', opts=dict(title='batch-y')) # y.numpy(), tensor to numpy
# if n > 1:
# break
time.sleep(10)
if __name__=='__main__':
main()
3.搭建ResNet18
搭建ResNet18需要先搞清楚ResNet18到底是什么样的一个网络结构,参考目录1,一共4个Residence Block每一个包含两个basic-block。
这里定义了basic-block
import torch
import torch.nn as nn
import torch.nn.functional as F
#定义残差块ResBlock
class ResBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResBlock, self).__init__()
#这里定义了残差块内连续的2个卷积层
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
#shortcut,这里为了跟2个卷积层的结果结构一致,要做处理
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
def forward(self, x):
out = self.left(x)
#将2个卷积层的输出跟处理过的x相加,实现ResNet的基本结构
out = out + self.shortcut(x)
out = F.relu(out)
return out
接着我们搭建自己的ResNet18:
class ResNet18(nn.Module):
def __init__(self, ResBlock, num_classes):
super(ResNet18, self).__init__()
self.inchannel = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.layer1 = self.make_layer(ResBlock, 64, 2, stride=1)
self.layer2 = self.make_layer(ResBlock, 128, 2, stride=2)
self.layer3 = self.make_layer(ResBlock, 256, 2, stride=2)
self.layer4 = self.make_layer(ResBlock, 512, 2, stride=2)
self.fc = nn.Linear(512, num_classes)
# 这个函数主要是用来,重复同一个残差块
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
# 在这里,整个ResNet18的结构就很清晰了
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
训练模型用来识别Pokemon:

import torch
from torch import optim, nn
import visdom
import torchvision
from torch.utils.data import DataLoader
from manualOwnDataSet import Pokemon # 导入自定义的数据集加载
from ResNet18_basicBlock import ResNet18 , ResBlock
batchsz = 32 # batchsize
lr = 1e-3 # learning rate
epochs = 10 # training epochs
device = torch.device('cuda') # GPU
torch.manual_seed(1234) # random seeds
train_db = Pokemon('pokemon', 224, 'train') # 实例化Pokemon数据类 train
val_db = Pokemon('pokemon', 224, 'val') # 实例化Pokemon 数据集 val
test_db = Pokemon('pokemon', 224, 'test') # 实例化Pokemon 数据集 test
train_loader = DataLoader(train_db, batch_size=batchsz, shuffle='True', # Pytorch DataLoader加载训练数据
num_workers=4)
val_loader = DataLoader(val_db, batch_size=batchsz, num_workers=4) # Pytorch DataLoader加载验证数据
test_loader = DataLoader(val_db, batch_size=batchsz, num_workers=4) # Pytorch DataLoader加载测试数据
def evaluate(model, loader):
correct = 0
total = len(loader.dataset)
for x, y in loader:
x, y = x.to(device), y.to(device)
with torch.no_grad():
logits = model(x)
pred = logits.argmax(dim=1) # 概率最大值所在的位置
correct += torch.eq(pred, y).sum().float().item()
return correct / total
def main():
model = ResNet18(ResBlock, 5).to(device) # 创建网络模型
optimizer = optim.Adam(model.parameters(), lr=lr) # 创建一个优化器 如果没有特殊要求一般都是用Adam
criteon = nn.CrossEntropyLoss() # loss
best_acc, best_epoch = 0, 0
for epoch in range(epochs): # training logicals
for step, (x, y) in enumerate(train_loader):
# x:[b,3,224,224],y:[b]
x, y = x.to(device), y.to(device) # 数据加载到GPU cuda
logits = model(x) # 模型的输出
loss = criteon(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 2 ==0:
val_acc = evaluate(model, val_loader)
if val_acc > best_acc:
best_epoch = epoch
best_acc = val_acc
torch.save(model.state_dict(), 'best.mdl') # 保存模型 文件后缀无所谓
print('best_acc:', best_acc, 'best_epoch:', best_epoch)
model.load_state_dict(torch.load('best.mdl'))
print('loaded from ckpt!')
test_acc = evaluate(model, test_loader)
print('test_acc:',test_acc)
if __name__=='__main__':
main()
4. 训练结果
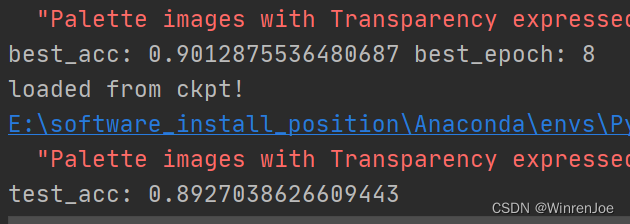
准确率达到90%,测试准确率也为89.3%,基本可以!
5.参考
https://debuggercafe.com/implementing-resnet18-in-pytorch-from-scratch/