目录
Anchor Free的Object Detection的多个方法被提出来,我最近也是集中地看了几篇Anchor Free的文章,文章来源是奇点汽车美研中心首席科学家兼总裁黄浴先生的的一篇总结。这篇文章中罗列Anchor Free的一些方法,但比较粗略,在这里我详细地总结一下。
在之前需要anchor方法中,Object Detection被当做是Classification的问题,将每个anchor分类,并对anchor的形状和位置做一些调整。Anchor Free的方法是将Object Detection的问题看做为keypoint estimation的问题。
Anchor Free 想要解决的问题
1、需要大量的anchor,anchor在整张图上非常密集的分布,从而需要判断大量的框是否与真值的IoU。
2、而且positive的框远远小于negative的框的数量,这种不平衡使得网络比较难训练,减慢了学习速度
3、anchor的设计需要很多超参数,针对不同的数据要设置不同的超参数,非常麻烦
4、anchor设计的不合理,很影响学习的效果,FCOS提到随着有关anchor超参数的变化,RetinaNet的AP浮动4%
早期探索
DenseBox
DenseBox: Unifying Landmark Localization with End to End Object Detection
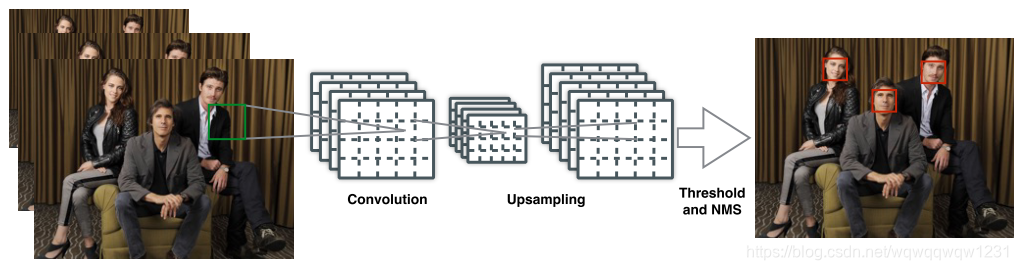
上图为DenseBox的整体思路,DenseBox使用上采样的feature map预测boxes。下图为DenseBox网络的具体细节。
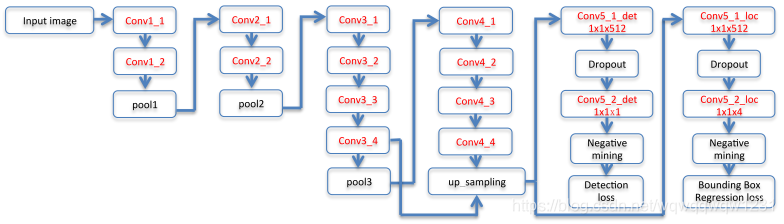
可以看出,在第5列的up_sampling之后的feature map分成两支:一支是做Classification,预测feature map中的每个网格单元是否属于Object;另一支做Regression,针对那些预测属于object的网格单元回归对应object的box的参数,其中box的参数表述为四条边相距输出像素的距离。
在ground truth的设定方面,位于物体中心一定距离内的像素点的真值设置为1,然后设置一部分灰色区域(在计算loss时不考虑),其他设置为背景。Loss在Classification和Regression均用的是L2 Loss。
其他小细节例如Hard Negative Mining等与Anchor based的方法是一样的。
本文还提到了使用Landmark Localization辅助进行Object Detection,具体结构如下图:
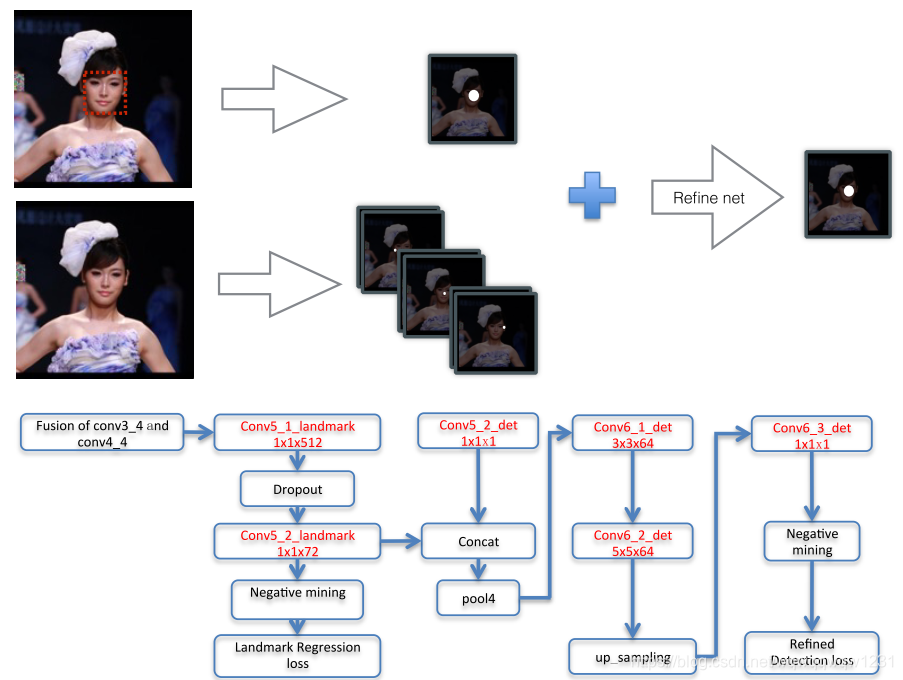
Landmark Localization是提取脸部的特征点,图中Conv5_2_landmark可以看到输出是72个通道,也就是说一个脸提取72个特征点。上图中的输入Fusion of conv3_4 and conv4_4应该就是主网络中upsampling的输出,Landmark Localization只针对Classification起作用。其中的操作可以看到是将lLandmark的输出和原来Classification的输出进行合并,然后再进行一次特征提取,然后输出Classification的结果。这块东西可能是因为我读文章的量还有限,无法理解其具体是怎么想的,或者是一种常规操作,这点还有待补充。
像Hourglass
YOLOv1
You Only Look Once: Unified, Real-Time Object Detection

Yolov1也是Anchor Free的典型之一。Yolov1通过卷积核下采样,得到7*7的feature map,每一个feature map负责预测几个box。其与DenseBox不同的几点在于:
- Yolov1最终7x7的feature map的每个网格单元预测多个box,而每个box除了有长宽信息,还有xy位置信息,xy的位置是限定在单元格内的,也就是常说的每个单元格负责预测中心点位于这个单元格的box。
- Yolov1在预测每个类别的socre和有关box的参数xywh的过程中,使用了2个全连接层,这一点增加了这个模型的不可解释性。这样子的操作,是将7x7个网格单元的信息耦合起来,组成4906的特征向量,然后再恢复成7x7个单元格的预测,这种预测方式使得7x7个单元格互相之间是耦合的,每个单元格的Classification和Regression也是耦合的,感觉无从解释。与Yolov1相比,DenseBox使用独立的两个预测头,分别解决Classification和Regression的问题,整个网络变的非常易于理解。通过对后续研究的了解,基本也是使用DenseBox的这种方式。
- Yolov1没有做上采样,但这个不是大问题。
Yolov2和v3为了提升精度,还是使用Anchor,作者发现通过预测偏移量而不是坐标值能够简化问题,让神经网络学习起来更容易。
Corner
该类方法使用Box的左上和右下两个顶点来表示Box,也就是说这类方法将Object Detection转为了顶点预测的问题,从而转入了Keypoint Estimation的问题中。
CornerNet
CornerNet: Detecting Objects as Paired Keypoints
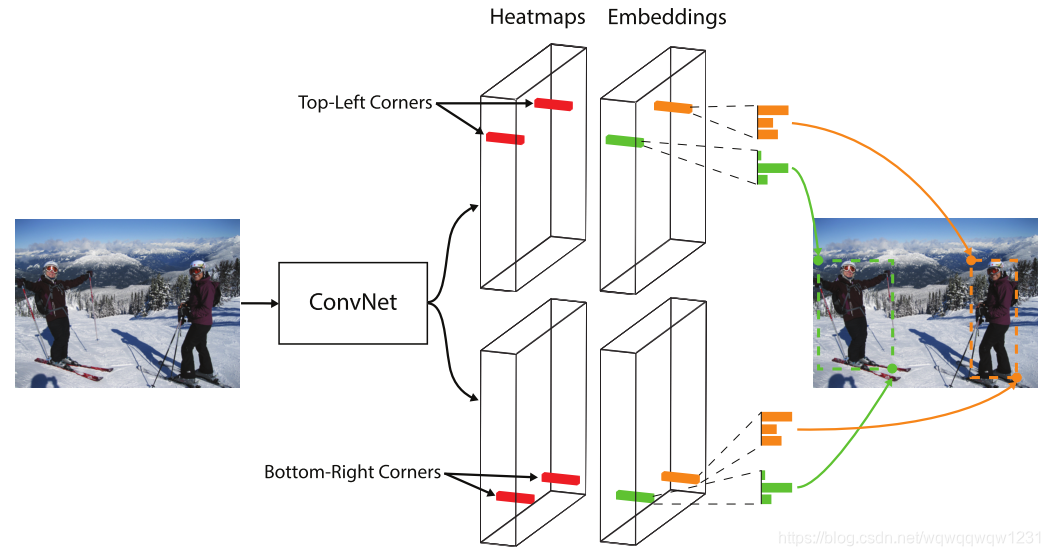
CornerNet通过寻找每个框的左上点和右下点,然后进行匹配来完成Object Detection任务的。从上图可以看出,通过CovnNet的特征提取得到feature map,预测头分为两支,一支是寻找图片中的所有左上点,一支是寻找图片中的右下点,这种任务是典型的关键点预测的问题。所以其中的ConvNet自然而然想到的是在该问题上有着突出表现的Hourglass网络,CornetNet的具体网络结构如下图

每个顶点的预测头包括4个模块,具体如下图,预测头一开始采用的残差网络的方式,其中插入Corner Pooling模块。
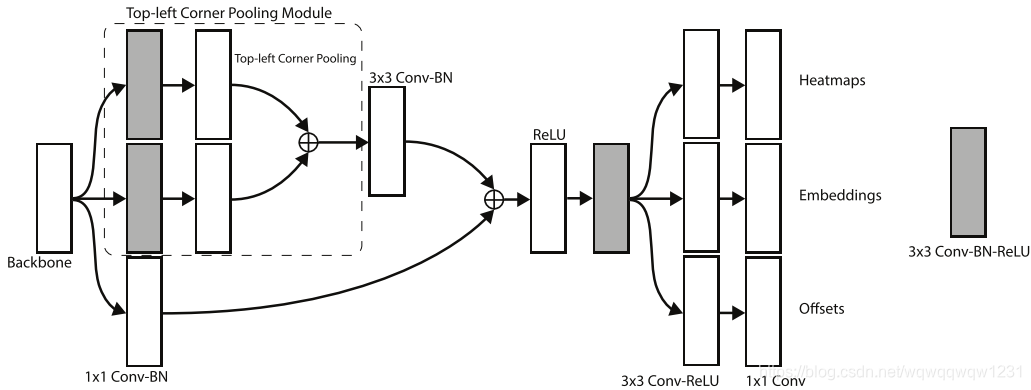
- Corner Pooling:Corner Pooling是本文提出为了顶点预测的一种Pooling模式,示意图如下图,对于左上顶点,Pooling的范围为竖直向下和水平向右,相当于pooling与该顶点有关的两条边上的所有信息。

- Heatmap:就是预测每个网格是顶点的socre
- Embeddings:给每个顶点一个标签,同一个box的两个顶点标签相距相近,不同box的标签相距较远,本文中使用标签只有1维,也就是一个标量,关于这个Loss具体构建如下。pull是让同一个box的两个顶点的标签相互靠近,push是希望不同box两个顶点的标签距离尽可能远,文中△设置为1,意味着希望不同box的的顶点标签相距超过1。

- Offset:Offset是指,如果backbone网络输出的feature map的网格数量是少于原始图片pixel的,原始图片的顶点位置不太可能再网格的中心,这里预测Offset进行微调,如果网格数量与pixel一致,可以认为这是在亚像素级的精细化的预测。
另外需要注意的一点是,在训练过程中,Corner真值给的方式是真实的Corner的位置值为1,真实位置附近的值是以真实位置为中心的一个高斯分布。这样意思是说,不强求Corner预测的非常准,在一定范围内也可以接受。
CornerNet-Lite
CornerNet-Lite: Efficient Keypoint Based Object Detection
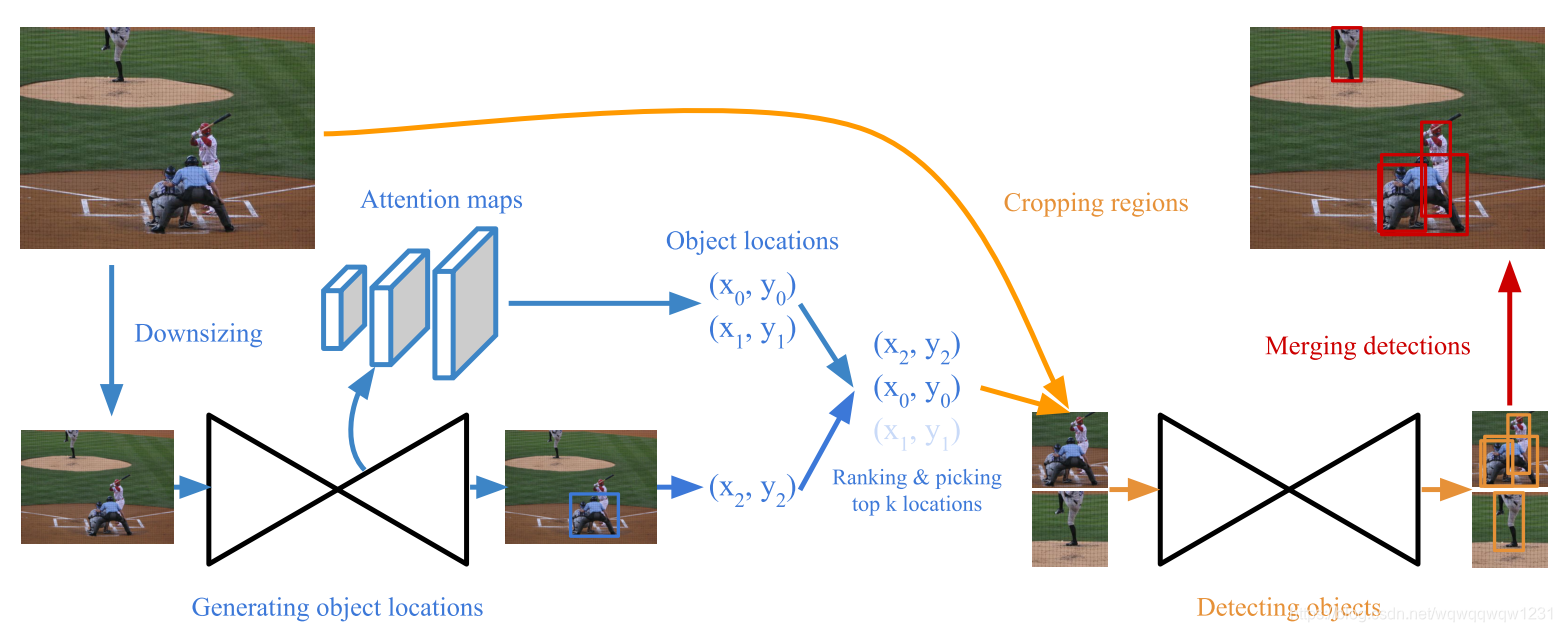
本文提出来两个网络,上图为CornerNet-Saccade,该网络先粗略的找一个RoI,然后再在RoI中预测box,但文章中称该网络是single-stage,这一点我比较疑惑?如果读者对single-stage和two-stage有见解的话,请在评论中留下您宝贵的意见!!!
该网络过程首先将图片缩小,然后用主干网络3个不同scale的feature map预测框可能在的位置,用center表示,但有了center怎么生成RoI,文章中没有讲!!!然后生成了RoI之后,在原图中crop,然后针对大小不同的object进行放大,为的是把小的object进行放大,然后在RoI中使用CornerNet进行预测box。但这个放大的方法反正我是没有看懂!!!放大方法如下图:

第一段是说,根据大中小3类不同的object进行不同程度的放大。第二段是说,根据放大后的Bounding box的长边来判断是什么类型的object。我不太明白,这个3类不同object到底是怎么定义的?所以到底是根据什么放大的???我觉得只有看了代码才能明白到底是怎么操作的。
本文提出的另外一个网络CornerNet-Squeeze就是把主干网络中的网络模块换一换,换成SqueezeNet的样子。
总体来说,这篇文章我是没咋看懂233333333,可能还是比较菜。
center
下面几篇Center的文章发出来的时间差不多,这样子排列只是为了能把方法讲的更清楚一些
Center and Scale Prediction
High-level Semantic Feature Detection: A New Perspective for Pedestrian Detection
Wei
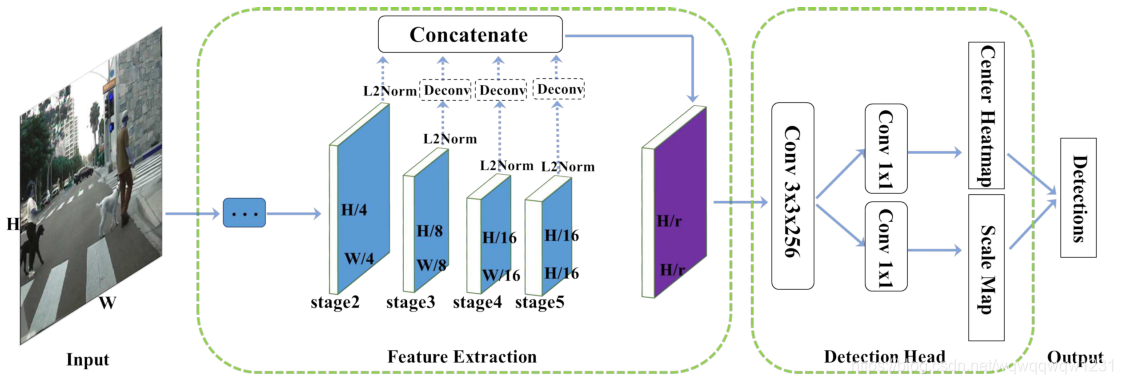
该方法的网络结构非常清晰,而且很常见,就是backbone网络再加上预测头,预测头的子网络的结构也非常清晰。一部分预测中心点的位置,一部分预测框的高度。这里只预测框的高度是因为,这篇文章只针对行人做预测,固定了框的长宽比为0.41,所以只用预测框的高度即可。本文整体非常易懂,有一个地方不太明白如下:
Since the feature maps from each stage have different scales, we use L2-normalization to rescale their norms to 10, which is similar to [21].
[21]还没有来得及去看,如果有明白的大佬,可以留言交流一下
CenterNet
Objects as Points
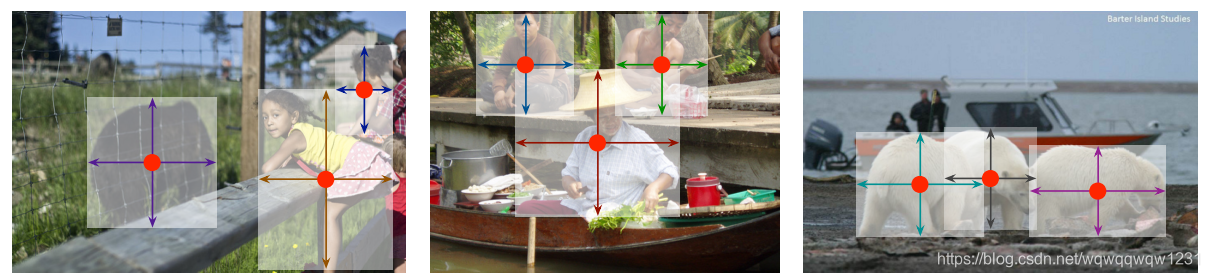
文章也很简单容易理解,文章中根本没有画网络结构,也没有具体说预测头到底是什么,但根据其他文献,分成多支,每支完成不同的任务,类似于上面一篇文章。任务分为:(1)预测是否是中心点,(2)预测中心点的偏移(预测该偏移预测的原因与CornerNet相同)和(3)预测box的边长。
本文的一大亮点就是用一个网络,完成了多个任务,有一种模块化开发的思想在内。完成的任务包括Object Detection,3D Object Detection,Pose Estimation。
文中一块提到了Center Collision,意思是不同Object的center因为高斯分布的扩张或者因为降采样的缘故,可能出现重叠,但作者统计发现这类情况出现率非常低,可以忽略。
FSAF
Feature Selective Anchor-Free Module for Single-Shot Object Detection
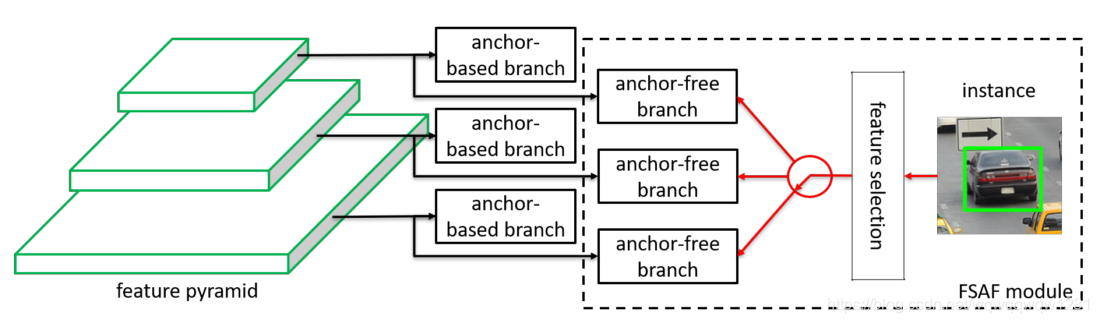
FSAF是一种结合了anchor based和anchor free的方法,其中anchor based的方法是RetinaNet,修改的部分是在RetinaNet用每一层feature map进行预测之前分支,将feature map输入到anchor free的预测头中,然后用anchor free的方法进行预测。anchor free的预测头与上一篇文章很像,任务分为:(1)Classification预测中心点和(2)Regression预测四边到中心点的距离。不预测中心点的偏移。具体网络见下图

FASF提出的思想是,anchor based的方法是通过IoU来判断target用哪个anchor预测,一般而言与target IoU相近的anchor是与target尺度大小相近的anchor,而不同大小的anchor相匹配的是不同层的feature map,所以追到底就是target用哪个feature map进行预测是与target的大小有关。也就是大的target一般用上层feature map预测,小的target一般用下层的feature map预测。是否能根据target的内容使用不同的feature map进行预测呢?FASF提出,对于一个target,用全部的feature map进行预测,然后计算每一层预测值与target的loss并取最小值,loss最小的那一层预测出来的说明用这一层的feature map最能代表这个target,然后在更新权重的时候,这个target的loss只更新这一层,于是在线的权重更新如下图所示:

文中还提到:一个target虽然有多层预测,但相当于只用一层预测的loss进行权重跟新,这种更新方式相当于在不断降低所有层对这个target预测的loss的下界。而在inference的过程中,使用全部的层进行预测,而预测最好的那一层得到的置信度会比较高,所以这样子更新也是有一定道理的。
FCOS
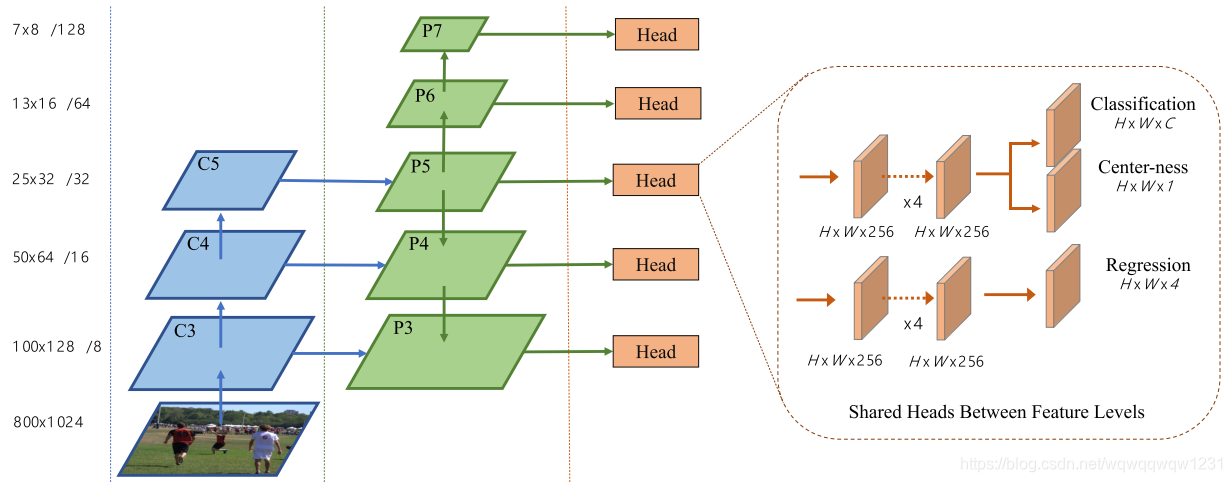
如果读者已经看完上面的介绍,可以发现,这个网络也非常清爽,很容易理解,预测头仍然是分类头和回归头。不同的是分类头最后分为两支,一支预测是否是box的中心点,另一支预测在本文中叫center-ness的一个量,这个量是用来判断这个点是否是一个center。作者发现,其中很多错误的框来自于离实际中心点很远的点预测的,所以加入了center-ness来作为一个衡量指标,当center-ness大于一定阈值时,才认为这个点是中心点,相信这个点产生的框。
本网络使用的预测头是共享权值的。
由于框可以由5层feature map来预测,所以作者使用target的大小把target分配到了不同的层。可以看到,P3-P7的stride是从8-128变化,而每一层feature map预测的边距离中心点最大长度为64,128,256,512,∞。其边长的变化也是2倍,保证了每一层feature map预测的边到中心点的距离基本在同一个范围内,是能实现预测头共享权值的一个条件。为了适应不同的层回归的值的范围不同,在回归边到中心点距离的过程最后加入了exp(x),将任意值转为[0,∞),因为这个距离总是正值。为了使得每一层的回归在同一个范围,每一层加入了一个参与训练的因子s,将最后一步变成了exp(sx)。
FoveaBox

本文章的网络基本与FCOS相同,上图画的是只是3层,但其实也是用了P3-P7的feature map。也是每层feature map出来是两个分支,一个做分类,一个回归框距离中心点的距离。但这些分类头不共享权值,在回归框距离中心点的距离时,做了一定的变换,具体见文章,也是为了将不同feature map预测的距离scale同一大小范围内。
既然用多个feature map预测,就会涉及到怎么将不同大小的target分配到不同的层做预测,这一块,我认为本文讲的十分费解,原文如下,我看不懂的地方用红色标出:

虽然看不懂这一句P3到P7是如何得到322到5122的,但可以推导一下:
| Pyramid level | Basic area |
|---|---|
| P3 | S 3 = 4 3 ⋅ 16 = 2 10 = 3 2 2 S_3 = 4^3 \cdot 16 = 2^{10} = 32^2 S3=43⋅16=210=322 |
| P4 | S 3 = 4 4 ⋅ 16 = 2 12 = 6 4 2 S_3 = 4^4 \cdot 16 = 2^{12} = 64^2 S3=44⋅16=212=642 |
| P5 | S 3 = 4 5 ⋅ 16 = 2 14 = 12 8 2 S_3 = 4^5 \cdot 16 = 2^{14} = 128^2 S3=45⋅16=214=1282 |
| P6 | S 3 = 4 6 ⋅ 16 = 2 16 = 25 6 2 S_3 = 4^6 \cdot 16 = 2^{16} = 256^2 S3=46⋅16=216=2562 |
| P7 | S 3 = 4 7 ⋅ 16 = 2 18 = 51 2 2 S_3 = 4^7 \cdot 16 = 2^{18} = 512^2 S3=47⋅16=218=5122 |
这个数值是与FCOS的划分一样的啊!!!不同点在于每一层的scale的具体范围是通过这些数值与 η \eta η共同控制的。
GA-RPN
Region Proposal by Guided Anchoring
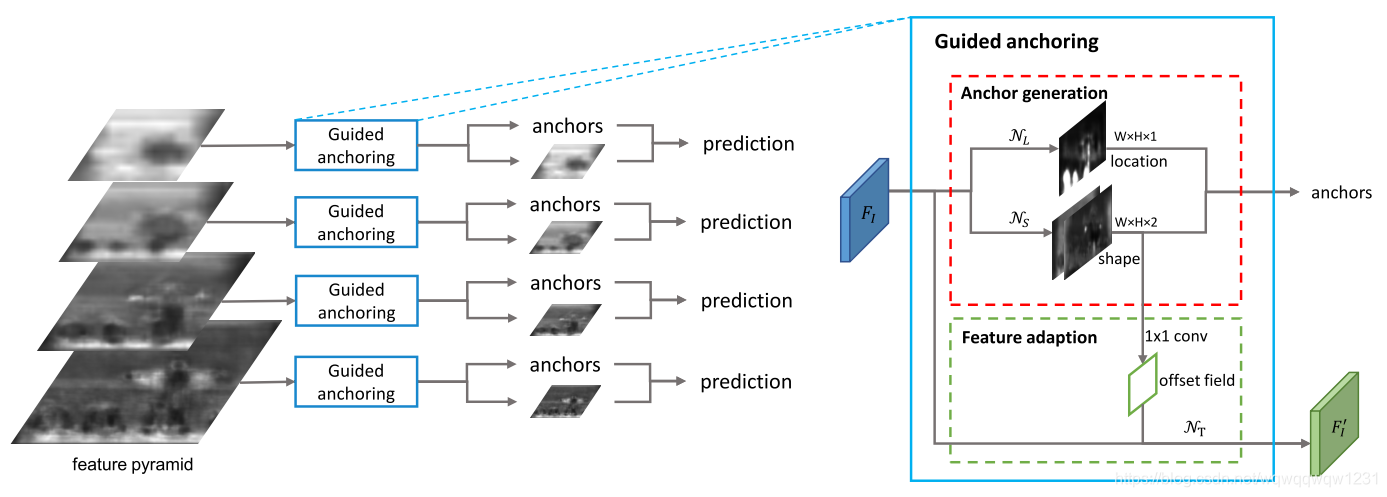
虽说本文章名字为Region Proposal,但其实也可以看作为预测box,因为生成的anchor其实也就是预测box的一步,只不过是认为比较粗略。如果单单看这一部分,那其实这个网络与以上的CenterNet区别不大,仍然是在多个feature map上加入分类头和回归头,分别预测box的中心点和回归box的长宽,长宽也是用指数的变换减轻了问题难度。
另外需要关注的一点是,在生成anchor的同时,文章使用deformable convolutional layer对feature map做变换,得到用于接下来进行优化box的feature map。具体的想法见下图:

Corner和Center相结合
ExtremeNet
Bottom-up Object Detection by Grouping Extreme and Center Points
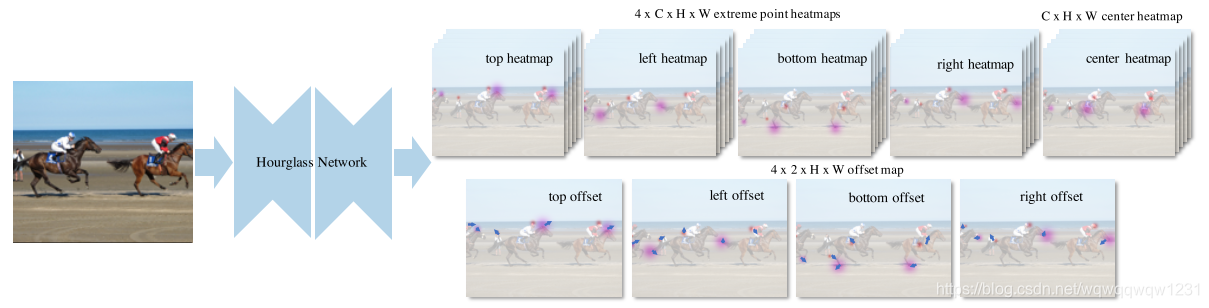
ExtremeNet认为CornerNet有缺陷在于Corner是不在Object内部的,所以ExtremeNet检测的是一个Object的最上、最下、最左和最右4个点。因为要将这些检测到的点变成Object,需要配对,所以还需要预测中心点以便配对,提出了Center Grouping的方法来使用中心点对四个边点进行配对。论文没有详细讲述网络结构,但我猜想应该和DenseBox类似,用多个分类头进行和回归头进行操作。与CornerNet另外一个不同的地方在于,extreme point heatmap的输出是一个类输出4个,而CornetNet的一个heatmap中是包含所有类的。而文章中也没有做这方面的Ablation studies。另外本文为了提高准确率,还加了一些后处理,Ghost box suppression和Edge aggregation Extreme。
CenterNet: Keypoint Triplets for Object Detection

作者发现CornetNet虽然对边界比较敏感,能检测出corner,但由于缺乏对物体的识别能力,在corner点配对上还有很大的欠缺。所以作者提出如下观点

我认为上述观点解释的不太清楚,我以我的方式理解一下:首先看这个网络预测了两部分,一部分是Corner,一部分是Center。Corner这部分与CornerNet是一样的,center这部分与corner类似,在训练的过程中也是取真实object的中心区域的像素作为center的target,同时生成offset。也就是说预测center这部分网络,其实就是在预测真实box的center。而在inference的过程中,先预测corner和center,用corner生成box,然后取top-k的box和center,对于每个box生成一个center region,检测center region中是否存在于box相同类的center,若存在,则保留这个box。从推断过程中来看,center是作为判断box是否为真的一个手段。所以上图黄字应该理解为,当预测box和真实的box的IoU很大时,那么真实box的center在预测box的center region中且类别一样的概率很大。这种理解既符合常识,也符合网络的训练和推理过程。
上述已经基本说清楚了网络的结构和推理的过程。本文还有以下几个创新点:
- 不同大小的真值的box所产生的center region的比例不同:这来自于作者发现,小的中心区域对于小目标会产生低的recall,大的中心区域对于大目标会产生低的precision。所以作者在center region产生时做了一定的区分。
- 作者提出了center pooling和Cascade corner pooling,这是在预测center和corner中使用,为了更好的感知center和corner。具体内容详见文章。
对比
这些模型有很大的内在关联,我将其整理成了一个图如下,其中只画了一些大的差别。还有一些小的差别,例如后处理,例如box长和宽的表示方法及变换,这些比较细的方面还得看论文进行比较。
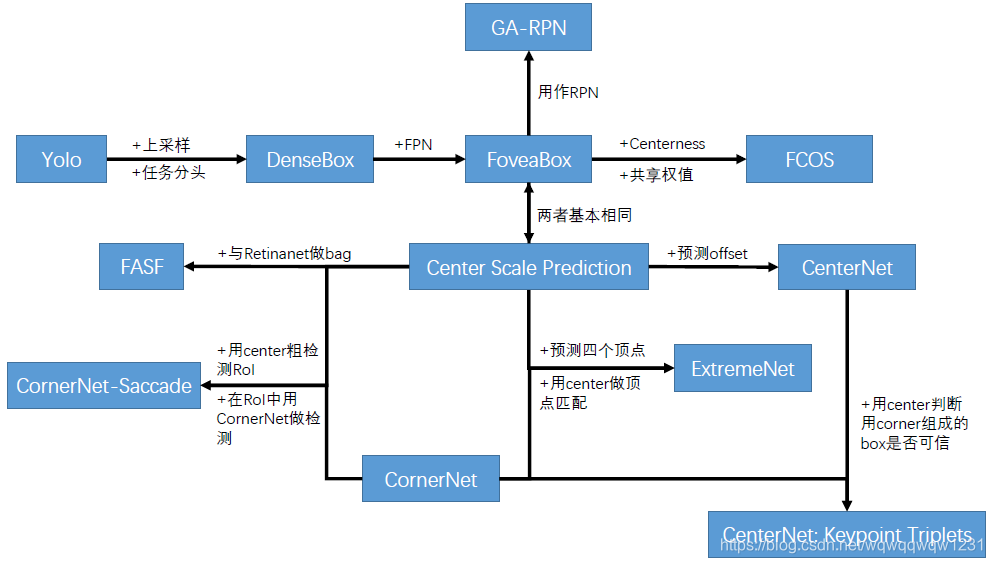
就单从主干网络和分支头这一点来看,基本所有网络的都很相似,这种搭配方式、主干网络的选择、分支头的选择已经成为了一种标准的设计思路。
结果如下图:只摘取了最好的结果
| Method | AP | AP50 | AP50 |
|---|---|---|---|
| FoveaBox | 42.1 | 61.9 | 45.2 |
| FCOS | 42.1 | 62.1 | 45.2 |
| CenterNet | 45.1 | 63.9 | 49.3 |
| CornerNet | 42.1 | 57.8 | 45.3 |
| ExtremeNet | 43.7 | 60.5 | 47.0 |
| FSAF | 44.6 | 65.2 | 48.6 |
| CenterNet:Keypoint Triplets for Object Detection | 47.0 | 64.5 | 50.7 |
| CornerNet-Saccade | 43.2 | – | – |