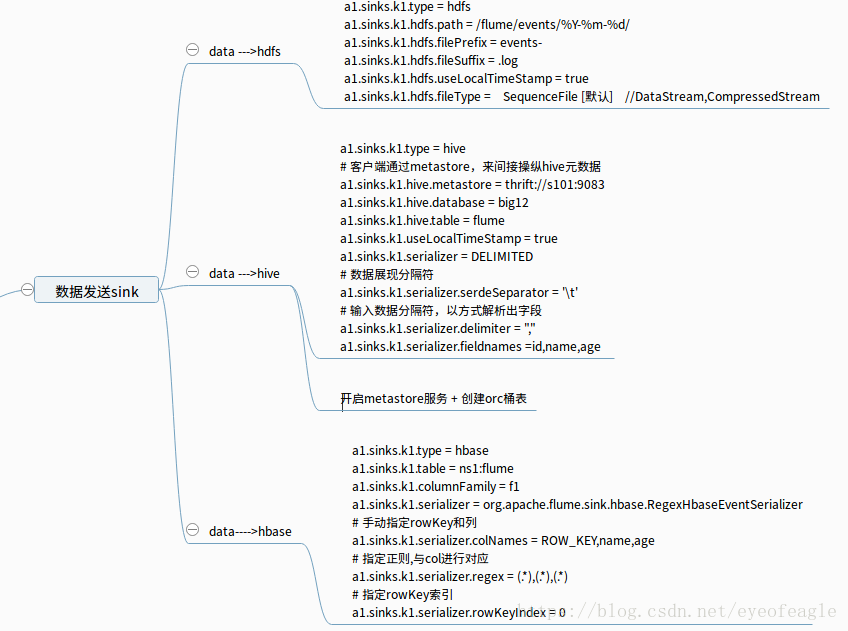
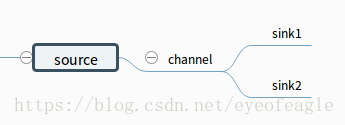
- 多路复用: 一个 source ----->多个 (channel----sink)
- 故障切换: 一个(source ---channel) ---->一个sink组(多个sink )
- 常用sink配置: hdfs,hive,hbase
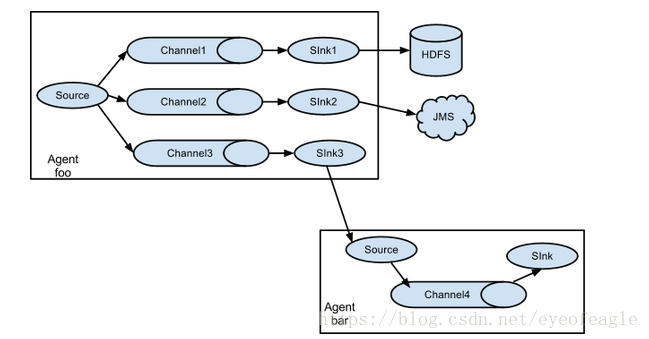
多路复用: ( Multiplexing the flow )
官方解释为:一个source的数据,可以有两种发送方式<复制、复用>,发送给多个channel (This fan out can be replicating or multiplexing. In case of replicating flow, each event is sent to all three channels. For the multiplexing case, an event is delivered to a subset of available channels when an event’s attribute matches a preconfigured value
使用案例1:(单机模拟--多路复用-replicating: source= syslogtcp, channel=memory, sink=logger, hdfs )

配置如下( mutiplex.conf )
#agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# source1--(重复性)复制
a1.sources.r1.type = syslogtcp
a1.sources.r1.port = 8888
a1.sources.r1.host = master1
a1.sources.r1.selector.type = replicating
a1.sources.r1.channels = c1 c2
# source2--(选择性)复用
#a1.sources.r1.type = http
#a1.sources.r1.bind = 0.0.0.0
#a1.sources.r1.port = 8888
#a1.sources.r1.selector.type= multiplexing
#a1.sources.r1.selector.header= heads
#a1.sources.r1.selector.mapping.hdfshead= c1
#a1.sources.r1.selector.mapping.loghead= c2
#a1.sources.r1.selector.default= c1
# sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.path = /flume/test-mutiplex-dfs
a1.sinks.k1.hdfs.filePrefix = events-test2
a1.sinks.k2.type=logger
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
#相互关联 source--channel, sink--channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2窗口1---启动flume: flume-ng agent -f ./mutiplex.conf -n a1
窗口2---使用nc连接8888端口,输入数据: 1234
( 窗口1---查看: 接收的数据如下)


使用案例1:(单机模拟--多路复用-multiplexing: source= syslogtcp, channel=memory, sink=logger, hdfs )
配置文件: 注释上面的mutiplex.conf 的 ‘source1’, 解开'source2'
窗口1---启动flume: flume-ng agent -f muti-mutiplex.conf -n a1
窗口2---发送数据:
curl -X POST -d '[{"headers" :{"heads" : "loghead"},"body" :"111"}]' http://master1:8888
curl -X POST -d '[{"headers" :{"heads" : "hdfshead"},"body" :"222"}]' http://master1:8888
(窗口1---查看接收的数据 如下)

(窗口3:---在hive中,查看hdfs数据如下)

故障切换
sink组管理多个sink, sink processor 可以为组里面的sink成员提供 <均衡负载, 容错> ( Sink groups allow users to group multiple sinks into one entity. Sink processors can be used to provide load balancing capabilities over all sinks inside the group or to achieve fail over from one sink to another in case of temporal failure)
sink processor 默认为default, 只支持单个sink, 不提供 均衡负载和容错的功能 ( Default sink processor accepts only a single sink)
准备: 3台机器(生产者, 消费者1,消费者2), 创建flume 配置文件
配置文件1:生产者 ( 把source的数据转移到 消费者1, 消费者2 )
# agent
a1.sources = r1
a1.sinks= k1 k2
a1.channels = c1
# source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# sink
a1.sinkgroups= g1
a1.sinkgroups.g1.sinks=k1 k2
#sink组:容错配置
a1.sinkgroups.g1.processor.type=failover
#sink组:负载均衡配置
#a1.sinkgroups.g1.processor.type = load_balance
#a1.sinkgroups.g1.processor.backoff = true
#a1.sinkgroups.g1.processor.selector = round_robin [默认]
#a1.sinkgroups.g1.processor.selector = random
a1.sinkgroups.g1.processor.priority.k1=5
a1.sinkgroups.g1.processor.priority.k2=10
a1.sinks.k1.type= avro
a1.sinks.k1.channel= c1
a1.sinks.k1.hostname= slave1
a1.sinks.k1.port= 50000
a1.sinks.k2.type= avro
a1.sinks.k2.channel= c1
a1.sinks.k2.hostname= slave2
a1.sinks.k2.port= 50000
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 100
a1.channels.c1.transactionCapacity = 100
# bind: source-channel, sink-channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置文件2:消费者1 ( 启动avro 服务, 接收source数据 )--->消费者2 配置与此相同
# agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 50000
# sink
a1.sinks.k1.type = logger
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind: source-channel, sink-channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
测试:验证failover ---->先启动 两个消费者, 再启动生产者
窗口1:(生产者) nc localhost 8888 【输入数据 123 aaa bbb】
窗口2:(slave2) 查看接收的数据

关闭slave2的flume服务,继续在窗口1输入数据 【xxxxxx xxx2222】
窗口3:(slave1) 可以查看到接收的数据

再次开启slave2的flume服务,继续在窗口1输入数据 【mmmm+++++】
窗口2:(slave2) 可以看到数据又被转移到slave2, slave1不再接收数据