在Flink的流式计算作业中,经常会遇到一些状态数不断累积,导致状态量越来越大的情形。例如,作业中定义了超长的时间窗口。对于这些情况,如果处理不好,经常导致堆内存出现 OOM,或者堆外内存(RocksDB)用量持续增长导致超出容器的配额上限,造成作业的频繁崩溃,业务不能稳定正常运行。
从 Flink 1.6 版本开始,社区引入了 State TTL 特性,该特性可以允许对作业中定义的 Keyed 状态进行超时自动清理(通常情况下,Flink 中大多数状态都是 Keyed 状态,只有少数地方会用到 Operator 状态,因此本文的“状态”均指的是 Keyed 状态),并且提供了多个设置参数,可以灵活地设定时间戳更新的时机、过期状态的可见性等,以应对不同的需求场景。
本质上来讲,State TTL 功能给每个 Flink 的 Keyed 状态增加了一个“时间戳”,而 Flink 在状态创建、写入或读取(可选)时更新这个时间戳,并且判断状态是否过期。如果状态过期,还会根据可见性参数,来决定是否返回已过期但还未清理的状态等等。状态的清理并不是即时的,而是使用了一种 Lazy 的算法来实现,从而减少状态清理对性能的影响。
1、State TTL 功能的用法
为了熟悉一个功能特性,最直观的方式是了解它的用法。在 Flink 的官方文档 中,用法示例如下:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
可以看到,要使用 State TTL 功能,首先要定义一个 StateTtlConfig 对象。这个 StateTtlConfig 对象可以通过构造器模式(Builder Pattern)来创建,典型地用法是传入一个 Time 对象作为 TTL 时间,然后设置更新类型(Update Type)和状态可见性(State Visibility),这两个功能的含义将在下面的文章中详细描述。当 StateTtlConfig 对象构造完成后,即可在后续声明的状态描述符(State Descriptor)中启用 State TTL 功能了。
从上述的代码也可以看到,State TTL 功能所指定的过期时间并不是全局生效的,而是和某个具体的状态所绑定。换而言之,如果希望对所有状态都生效,那么就需要对所有用到的状态定义都传入 StateTtlConfig 对象。
State TTL 使用的更多案例,可以参见官方的 https://github.com/apache/flink/tree/master/flink-end-to-end-tests/flink-stream-state-ttl-test/src/main/java/org/apache/flink/streaming/tests,它提供了很多测试用例可以参考。
2、StateTtlConfig 的参数说明
(1)TTL:表示状态的过期时间,是一个 org.apache.flink.api.common.time.Time 对象。一旦设置了 TTL,那么如果上次访问的时间戳 + TTL 超过了当前时间,则表明状态过期了(这是一个简化的说法,严谨的定义请参考 org.apache.flink.runtime.state.ttl.TtlUtils 类中关于 expired 的实现) 。
(2)UpdateType:表示状态时间戳的更新的时机,是一个 Enum 对象。如果设置为 Disabled,则表明不更新时间戳;如果设置为 OnCreateAndWrite,则表明当状态创建或每次写入时都会更新时间戳;如果设置为 OnReadAndWrite,则除了在状态创建和写入时更新时间戳外,读取也会更新状态的时间戳。
(3)StateVisibility:表示对已过期但还未被清理掉的状态如何处理,也是 Enum 对象。如果设置为 ReturnExpiredIfNotCleanedUp,那么即使这个状态的时间戳表明它已经过期了,但是只要还未被真正清理掉,就会被返回给调用方;如果设置为 NeverReturnExpired,那么一旦这个状态过期了,那么永远不会被返回给调用方,只会返回空状态,避免了过期状态带来的干扰。
(4)TimeCharacteristic 以及 TtlTimeCharacteristic:表示 State TTL 功能所适用的时间模式,仍然是 Enum 对象。前者已经被标记为 Deprecated(废弃),推荐新代码采用新的 TtlTimeCharacteristic 参数。截止到 Flink 1.8,只支持 ProcessingTime 一种时间模式,对 EventTime 模式的 State TTL 支持还在开发中。
(5)CleanupStrategies:表示过期对象的清理策略,目前来说有三种 Enum 值。当设置为 FULL_STATE_SCAN_SNAPSHOT 时,对应的是 EmptyCleanupStrategy 类,表示对过期状态不做主动清理,当执行完整快照(Snapshot / Checkpoint)时,会生成一个较小的状态文件,但本地状态并不会减小。唯有当作业重启并从上一个快照点恢复后,本地状态才会实际减小,因此可能仍然不能解决内存压力的问题。为了应对这个问题,Flink 还提供了增量清理的枚举值,分别是针对 Heap StateBackend 的 INCREMENTAL_CLEANUP(对应 IncrementalCleanupStrategy 类),以及对 RocksDB StateBackend 有效的 ROCKSDB_COMPACTION_FILTER(对应 RocksdbCompactFilterCleanupStrategy 类). 对于增量清理功能,Flink 可以被配置为每读取若干条记录就执行一次清理操作,而且可以指定每次要清理多少条失效记录;对于 RocksDB 的状态清理,则是通过 JNI 来调用 C++ 语言编写的 FlinkCompactionFilter 来实现,底层是通过 RocksDB 提供的后台 Compaction 操作来实现对失效状态过滤的。
流式作业的特点是7*24小时运行,数据不重复消费,不丢失,保证只计算一次,数据实时产出不延迟,但是当状态很大,内存容量限制,或者实例运行奔溃,或需要扩展并发度等情况下,如何保证状态正确的管理,在任务重新执行的时候能正确执行,状态管理就显得尤为重要,所以,接下来分析一下checkpoint
3、checkpoint
checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。Flink的checkpoint机制原理来自“Chandy-Lamport algorithm”算法。 (分布式快照算)
3.1、flink中checkpoint执行流程
每个需要checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator,CheckpointCoordinator全权负责本应用的快照制作。
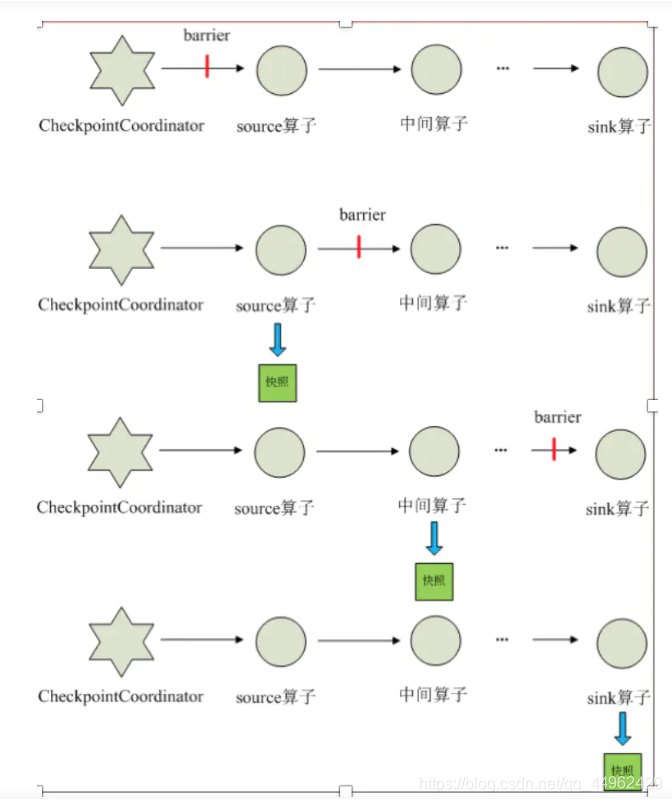
1、CheckpointCoordinator周期性的向该流应用的所有source算子发送barrier。
2、当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告 自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
3、下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
4、每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
5、当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败 ;
3.2、多并行度、多Operator情况下,CheckPoint过程
(1)JobManager向Source Task发送CheckPointTrigger,Source Task会在数据流中安插CheckPoint barrier;
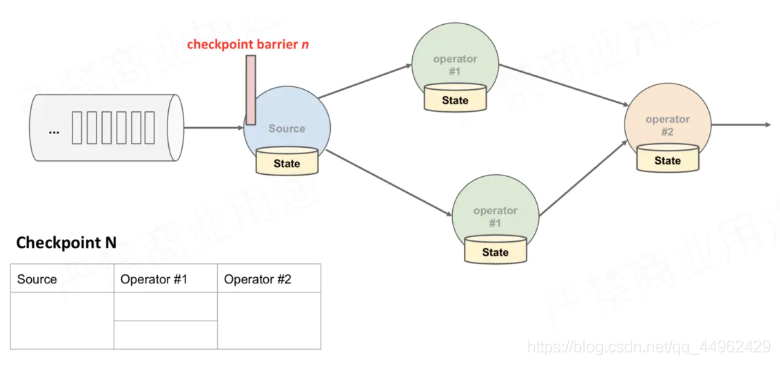 (2)Source Task自身做快照,并保存到状态后端;
(2)Source Task自身做快照,并保存到状态后端;
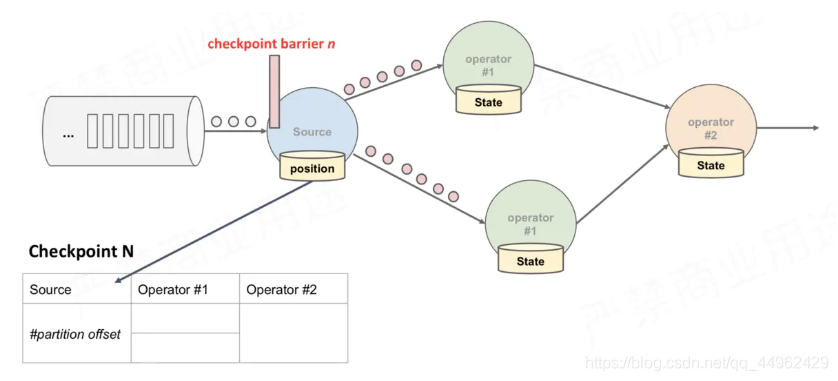
(3)Source Task将barrier跟数据流一块往下游发送;
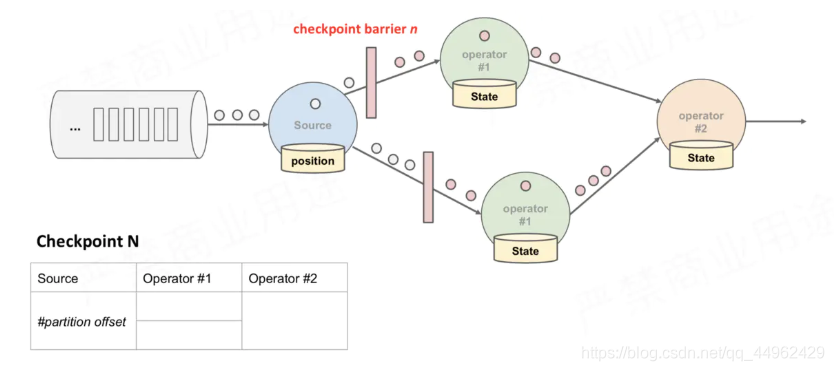
(4)当下游的Operator实例接收到CheckPoint barrier后,对自身做快照
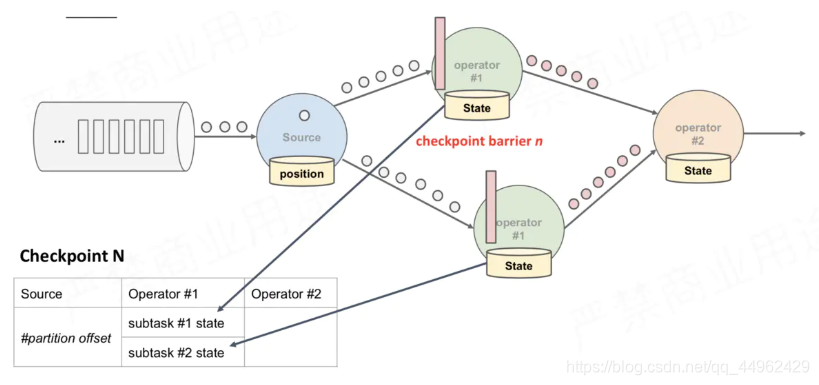
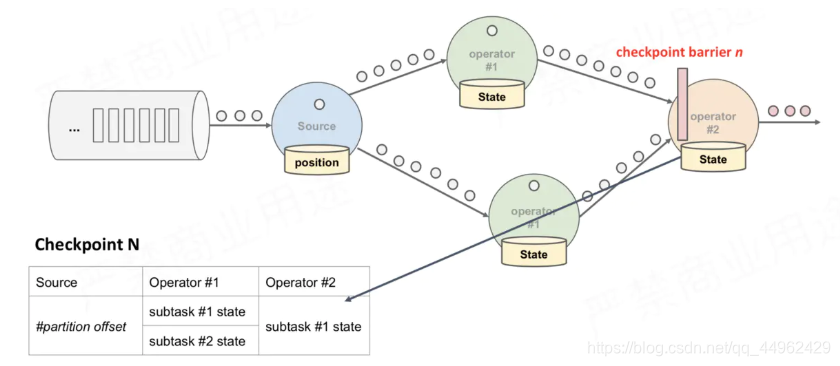
上述图中,有4个带状态的Operator实例,相应的状态后端就可以想象成填4个格子。整个CheckPoint 的过程可以当做Operator实例填自己格子的过程,Operator实例将自身的状态写到状态后端中相应的格子,当所有的格子填满可以简单的认为一次完整的CheckPoint做完了
上面只是快照的过程,整个CheckPoint执行过程如下
1、JobManager端的 CheckPointCoordinator向 所有SourceTask发送CheckPointTrigger,Source Task会在数据流中安插CheckPoint barrier
2、当task收到所有的barrier后,向自己的下游继续传递barrier,然后自身执行快照,并将自己的状态异步写入到持久化存储中。增量CheckPoint只是把最新的一部分更新写入到 外部存储;为了下游尽快做CheckPoint,所以会先发送barrier到下游,自身再同步进行快照
3、当task完成备份后,会将备份数据的地址(state handle)通知给JobManager的CheckPointCoordinator;
如果CheckPoint的持续时长超过 了CheckPoint设定的超时时间,CheckPointCoordinator 还没有收集完所有的 State Handle,CheckPointCoordinator就会认为本次CheckPoint失败,会把这次CheckPoint产生的所有 状态数据全部删除。
4、 最后 CheckPoint Coordinator 会把整个 StateHandle 封装成 completed CheckPoint Meta,写入到hdfs。
3.3、barrier对齐
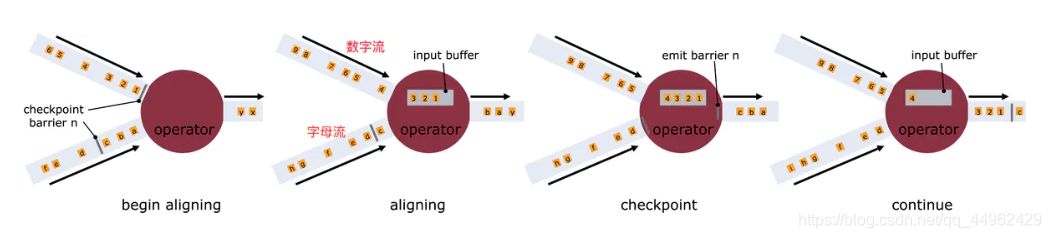
什么是barrier对齐?
(1)一旦Operator从输入流接收到CheckPoint barrier n,它就不能处理来自该流的任何数据记录,直到它从其他所有输入接收到barrier n为止。否则,它会混合属于快照n的记录和属于快照n + 1的记录;
(2)接收到barrier n的流暂时被搁置。从这些流接收的记录不会被处理,而是放入输入缓冲区。
(3)上图中第2个图,虽然数字流对应的barrier已经到达了,但是barrier之后的1、2、3这些数据只能放到buffer中,等待字母流的barrier到达;
(4)一旦最后所有输入流都接收到barrier n,Operator就会把缓冲区中pending 的输出数据发出去,然后把CheckPoint barrier n接着往下游发送
这里还会对自身进行快照,之后,Operator将继续处理来自所有输入流的记录,在处理来自流的记录之前先处理来自输入缓冲区的记录。
什么是barrier不对齐?
上述图2中,当还有其他输入流的barrier还没有到达时,会把已到达的barrier之后的数据1、2、3搁置在缓冲区,等待其他流的barrier到达后才能处理,barrier不对齐就是指当还有其他流的barrier还没到达时,为了不影响性能,也不用理会,直接处理barrier之后的数据。等到所有流的barrier的都到达后,就可以对该Operator做CheckPoint了。
为什么要进行barrier对齐?不对齐到底行不行?
Exactly Once时必须barrier对齐,如果barrier不对齐就变成了At Least Once;
barrier对齐其实也就是上游多个流配合使得数据对齐的过程,言外之意:如果Operator实例只有一个输入流,就根本不存在barrier对齐,自己跟自己默认永远都是对齐的。
以下是博主在开发中遇到过的疑问
(1)kafka只有一个partition,精确一次,至少一次就没有区别?
答:如果只有一个partition,对应flink任务的Source Task并行度只能是1,确实没有区别,不会有至少一次的存在了,肯定是精确一次。因为只有barrier不对齐才会有可能重复处理,这里并行度都已经为1,默认就是对齐的,只有当上游有多个并行度的时候,多个并行度发到下游的barrier才需要对齐,单并行度不会出现barrier不对齐,所以必然精确一次。其实还是要理解barrier对齐就是Exactly Once不会重复消费,barrier不对齐就是 At Least Once可能重复消费,这里只有单个并行度根本不会存在barrier不对齐,所以不会存在至少一次语义;
(2)为了下游尽快做CheckPoint,所以会先发送barrier到下游,自身再同步进行快照;这一步,如果向下发送barrier后,自己同步快照慢怎么办?下游已经同步好了,自己还没?
答: 可能会出现下游比上游快照还早的情况,但是这不影响快照结果,只是下游快照的更及时了,我只要保障下游把barrier之前的数据都处理了,并且不处理barrier之后的数据,然后做快照,那么下游也同样支持精确一次。这个问题你不要从全局思考,你单独思考上游和下游的实例,你会发现上下游的状态都是准确的,既没有丢,也没有重复计算。这里需要注意一点,如果有一个Operator 的CheckPoint失败了或者因为CheckPoint超时也会导致失败,那么JobManager会认为整个CheckPoint失败。失败的CheckPoint是不能用来恢复任务的,必须所有的算子的CheckPoint都成功,那么这次CheckPoint才能认为是成功的,才能用来恢复任务;
(3)我程序中Flink的CheckPoint语义设置了 Exactly Once,但是我的mysql中看到数据重复了?程序中设置了1分钟1次CheckPoint,但是5秒向mysql写一次数据,并commit;
答:Flink要求end to end的精确一次都必须实现TwoPhaseCommitSinkFunction。如果你的chk-100成功了,过了30秒,由于5秒commit一次,所以实际上已经写入了6批数据进入mysql,但是突然程序挂了,从chk100处恢复,这样的话,之前提交的6批数据就会重复写入,所以出现了重复消费。Flink的精确一次有两种情况,一个是Flink内部的精确一次,一个是端对端的精确一次,这个博客所描述的都是关于Flink内部去的精确一次,我后期再发一个博客详细介绍一下Flink端对端的精确一次如何实现。