一、概述
接之前两篇ShuffleWrite文章,这里讲解Spark Shuffle Write的第三种实现SortShuffleWriter,在ShuffleWrite阶段,如果不满足UnsafeShuffleWriter、BypassMergeSortShuffleWriter两种条件,最后代码执行SortShuffleWriter,这里来看看他的具体实现:
二、具体实现
这里直接看Write()函数,代码如下:
/** Write a bunch of records to this task's output */override def write(records: Iterator[Product2[K, V]]): Unit = {// 根据是否在map端进行数据合并初始化ExternalSorter//ExternalSorter初始化对应参数的含义// aggregator:在RDD shuffle时,map/reduce-side使用的aggregator// partitioner:对shuffle的输出,使用哪种partitioner对数据做分区,比如hashPartitioner或者rangePartitioner// ordering:根据哪个key做排序// serializer:使用哪种序列化,如果没有显示指定,默认使用spark.serializer参数值sorter = if (dep.mapSideCombine) {require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")new ExternalSorter[K, V, C](context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)} else {// 如果没有map-side聚合,那么创建sorter对象时候,aggregator和ordering将不传入对应的值new ExternalSorter[K, V, V](context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)}//通过insertAll方法先写数据到buffersorter.insertAll(records)// 构造最终的输出文件实例,其中文件名为(reduceId为0):// "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId;val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)//在输出文件名后加上uuid用于标识文件正在写入,结束后重命名val tmp = Utils.tempFileWith(output)try {val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)//将排序后的record写入输出文件val partitionLengths = sorter.writePartitionedFile(blockId, tmp)//生成index文件,也就是每个reduce通过该index文件得知它哪些是属于它的数据shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)//构造MapStatus返回结果,里面含有ShuffleWriter输出结果的位置信息mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)} finally {if (tmp.exists() && !tmp.delete()) {logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")}}}
其中ExternalSorter是SortShuffleWriter一个排序类,这个类用于对一些(K, V)类型的key-value对进行排序,如果需要就进行merge,生的结果是一些(K, C)类型的key-combiner对。combiner就是对同样key的value进行合并的结果。它首先使用一个Partitioner来把key分到不同的partition,然后,如果有必要的话,就把每个partition内部的key按照一个特定的Comparator来进行排序。它可以输出只一个分区了的文件,其中不同的partition位于这个文件的不同区域(在字节层面上每个分区是连续的),这样就适用于shuffle时对数据的抓取。
2.这里接着看上面代码第14行的 sorter.insertAll(records)函数,里面其实干了很多事情,代码如下:
def insertAll(records: Iterator[Product2[K, V]]): Unit = { //这里获取Map是否聚合标识 val shouldCombine = aggregator.isDefined //根据是否进行Map端聚合,来决定使用map还是buffer, // 如果需要通过key做map-side聚合,则使用PartitionedAppendOnlyMap; // 如果不需要,则使用PartitionedPairBuffer if (shouldCombine) { // 使用AppendOnlyMap优先在内存中进行combine // 获取aggregator的mergeValue函数,用于merge新的值到聚合记录 val mergeValue = aggregator.get.mergeValue // 获取aggregator的createCombiner函数,用于创建聚合的初始值 val createCombiner = aggregator.get.createCombiner var kv: Product2[K, V] = null val update = (hadValue: Boolean, oldValue: C) => { //创建update函数,如果有值进行mergeValue,如果没有则createCombiner if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2) } while (records.hasNext) { addElementsRead() kv = records.next() ////通过key计算partition ID,通过partition ID对数据进行排序 //这里的partitionID其实就是Reduce个数 // 对key计算分区,然后开始进行merge map.changeValue((getPartition(kv._1), kv._1), update) // 如果需要溢写内存数据到磁盘 maybeSpillCollection(usingMap = true) } } else { // Stick values into our buffer while (records.hasNext) { addElementsRead() val kv = records.next() //通过key计算partition ID,通过partition ID对数据进行排序 //这里的partitionID其实就是Reduce个数 buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C]) // 当buffer达到内存限制时(buffer默认大小32k,由spark.shuffle.file.buffer参数决定),会将buffer中的数据spill到文件中 maybeSpillCollection(usingMap = false) } } }
3.下面继续跟踪maybeSpillCollection()函数,如何对内存数据溢写的,代码如下:
private def maybeSpillCollection(usingMap: Boolean): Unit = { var estimatedSize = 0L // 如果是map ,也就是Map端需要聚合的情况 if (usingMap) { //这里预估一个值,根据预估值判断是否需要溢写, // 如果需要,溢写完成后重新初始化一个map estimatedSize = map.estimateSize() if (maybeSpill(map, estimatedSize)) { map = new PartitionedAppendOnlyMap[K, C] } // 这里执行的map不需要聚合的情况 } else { //这里预估一个值,根据预估值判断是否需要溢写, // 如果需要,溢写完成后重新初始化一个buffer estimatedSize = buffer.estimateSize() if (maybeSpill(buffer, estimatedSize)) { buffer = new PartitionedPairBuffer[K, C] } } if (estimatedSize > _peakMemoryUsedBytes) { _peakMemoryUsedBytes = estimatedSize } }
4.上面涉及到溢写判断函数maybeSpill,我们看下他是如何进行判断的,代码如下:
// maybeSpill函数判断大体分了三步// 1.为当前线程尝试获取amountToRequest大小的内存(amountToRequest = 2 * currentMemory - myMemoryThreshold)。// 2.如果获得的内存依然不足(myMemoryThreshold <= currentMemory),则调用spill,执行溢出操作。内存不足可能是申请到的内存为0或者已经申请得到的内存大小超过了myMemoryThreshold。// 3.溢出后续处理,如elementsRead归零,已溢出内存字节数(memoryBytesSpilled)增加线程当前内存大小(currentMemory),释放当前线程占用的内存。 protected def maybeSpill(collection: C, currentMemory: Long): Boolean = { var shouldSpill = false //其中内存阈值myMemoryThreshold 由参数spark.shuffle.spill.initialMemoryThreshold控制,默认是5M if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) { // Claim up to double our current memory from the shuffle memory pool val amountToRequest = 2 * currentMemory - myMemoryThreshold //底层调用TaskMemoryManager的acquireExecutionMemory方法分配内存 val granted = acquireMemory(amountToRequest) // 更新现在内存阀值 myMemoryThreshold += granted //再次判断当前内存是否大于阀值,如果还是大于阀值则spill shouldSpill = currentMemory >= myMemoryThreshold } shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold // Actually spill if (shouldSpill) { _spillCount += 1 logSpillage(currentMemory) //进行spill,这了溢写肯定先写到缓冲区,后写到磁盘, //有个比较重要的参数spark.shuffle.file.buffer 默认32k, 优化时常进行调整 spill(collection) _elementsRead = 0 _memoryBytesSpilled += currentMemory releaseMemory() } shouldSpill }
里面还有更深层次的代码,这里就不再跟踪了,只要是了解了整个大体思路即可,有兴趣的自己去跟踪看下即可。
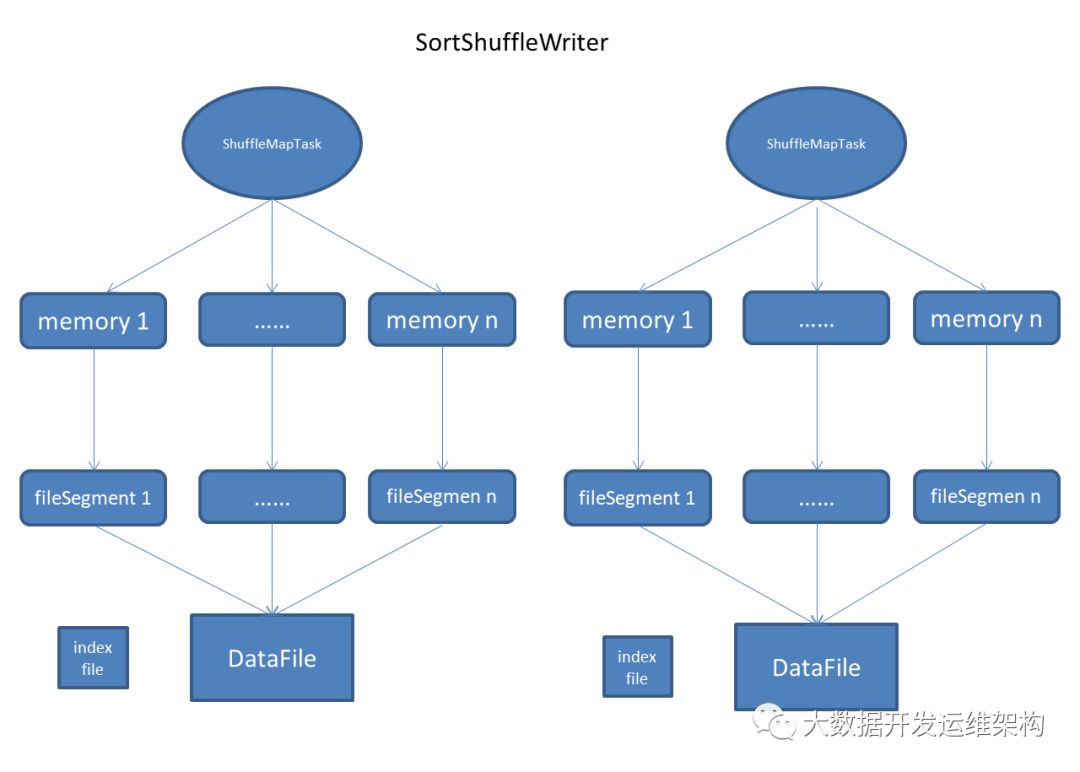
为方便大家理解,下面给大家画了下SorteShuffleWriter执行的流程图,BypassMergeSortShuffleWriter和UnsafeShuffleWriter的处理流程与这个流程基本一致,只是具体的实现稍有差异,水平有限,仅供参考: