Spark学习笔记:5、Spark On YARN模式
有些关于Spark on YARN部署的博客,实际上介绍的是Spark的 standalone运行模式。如果启动Spark的master和worker服务,这是Spark的 standalone运行模式,不是Spark on YARN运行模式,请不要混淆。
Spark在生产环境中,主要部署在Hadoop集群中,以Spark On YARN模式运行,依靠yarn来调度Spark,比默认的Spark运行模式性能要好的多。
所以需要先搭建Hadoop分布式环境,然后就可以开始部署Spark on YARN了。
如果你已经准备好Hadoop分布式环境,请直接跳转到5.5节;
如果你对Hadoop分布式环境搭建不熟悉,请参考下面5.1节到5.4节内容。
Hadoop分布式环境搭总思路:以192.168.1.180节点为基准构建Spark分布式环境,然后将软件包分发到各个节点。
我的192.168.1.180节点是个虚拟机,这样可以通过复制虚拟机快速搭建集群。
5.1 基本Linux环境搭建
(1)配置IP地址
(2)修改hosts文件
[root@master ~]# vi /etc/hosts
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.180 master
192.168.1.181 slave1
192.168.1.182 slave2
[root@master ~]# (3)关闭防火墙和禁用Selinux
停止防火墙
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
禁用Selinux
[root@master ~]# setenforce 0
[root@master ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config查看修改后的文件
[root@master ~]# cat /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
[root@master ~]#(4)安装openssh-clients
安装openssh-clients
[root@master ~]# yum install -y openssh-clients在/root目录下准备一个脚本文件sshUtil.sh,用于SSH免密登录配置(后面再执行),内容如下:
#!/bin/bash
ssh-keygen -q -t rsa -N "" -f /root/.ssh/id_rsa
ssh-copy-id -i localhost
ssh-copy-id -i master
ssh-copy-id -i slave1
ssh-copy-id -i slave2参数说明:
- -t指定算法
- -f 指定生成秘钥路径
- -N指定密码
(5)安装JDK8
下载解压
[root@master ~]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt配置环境变量
[root@master ~]# vi /etc/profile.d/custom.sh
[root@master ~]# cat /etc/profile.d/custom.sh
#!/bin/bash
#java path
export JAVA_HOME=/opt/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
[root@master ~]# source /etc/profile.d/custom.sh
[root@master ~]# java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
[root@master ~]# 5.2 Hadoop环境搭建
(1)Hadoop集群规划
| 序号 | OS | IP | 节点名 | NN | DN | RM | NM |
|---|---|---|---|---|---|---|---|
| 1 | CentOS7 | 192.168.1.180 | master | Y | Y | Y | Y |
| 2 | CentOS7 | 192.168.1.181 | slave1 | Y | Y | ||
| 3 | CentOS7 | 192.168.1.182 | slave2 | Y | Y |
(2)下载Hadoop软件包
[root@master ~]# wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz
[root@master ~]# tar -zxvf hadoop-2.7.4.tar.gz -C /opt(3)hadoop-env.sh
[root@master hadoop]# pwd
/opt/hadoop-2.7.4/etc/hadoop
[root@master hadoop]# sed -i 's#export JAVA_HOME=${JAVA_HOME}#export JAVA_HOME=/opt/jdk1.8.0_144#' hadoop-env.sh (4)core-site.xml
[root@master hadoop-2.7.4]# vi etc/hadoop/core-site.xml编辑内容如下
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/data/hadoop</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>65536</value>
</property>
</configuration>(5)hdfs-site.xml
[root@node1 hadoop]# vi hdfs-site.xmlhdfs-site.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
<property>
<name>dfs.namenode.secondary.https-address</name>
<value>slave2:50091</value>
</property>
</configuration>(6)slaves
[root@master hadoop]# echo 'master' > slaves
[root@master hadoop]# echo 'slave1' >> slaves
[root@master hadoop]# echo 'slave2' >> slaves
[root@master hadoop]# cat slaves
master
slave1
slave2
[root@master hadoop]#(7)mapred-site.xml
[root@master hadoop-2.7.4]# vi etc/hadoop/mapred-site.xml
[root@master hadoop-2.7.4]# cat etc/hadoop/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(8)yarn-site.xml
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>(9)配置环境变量
编辑/etc/profile.d/custom.sh,增加如下内容
#hadoop path
export HADOOP_HOME=/opt/hadoop-2.7.4
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}5.3 搭建集群
上面已经对Linux基础环境和Hadoop环境配置好,现在需要构建集群。这里通过最快捷的方式,复制虚拟机。
(1)复制虚拟机
首先关闭虚拟机master 192.168.1.180,先复制一个slave1节点,操作如下:
- 在VMWare软件中右键单击master,在弹出的快捷菜单中选中Mange–>clone;
- 然后弹出克隆向导,直接单击“Next”
- Clone from界面默认选项即可,再次单击“Next”
- Clone Type界面中选中Create a full clone
- Name输入框输入节点名称slave1,Location选中新虚拟机存放目录(默认值即可),单击“Next”
- 单击Finish按钮,开始复制,最后单击“Close”按钮即可
同样的操作,再复制一个slave2节点。
(2)修改IP和hostname
先修改新节点slave1的IP和hostname
直接通过sed命令修改IPADDR值即可。
sed -i 's/192.168.1.180/192.168.1.181' /etc/sysconfig/network-scripts/ifcfg-ens32然后重启网络
systemctl restart network修改主机名
hostnamectl set-hostname slave1同样操作修改slave2节点的IP和hostanem
可能存在的问题:
如果复制的虚拟机无法联网,可以尝试编辑/etc/sysconfig/network-scripts/ifcfg-ens32文件,删除UUID和HWADDR两行数据。然后重启网络。
(3)SSH免密操作
在master节点上执行sshUtil.sh脚本,按照提示输入yes和对应节点密码
[root@master ~]# sh sshUtil.sh
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is 22:5e:82:fa:7b:c3:26:de:30:76:73:bd:7c:a2:17:29.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@localhost's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'localhost'"
and check to make sure that only the key(s) you wanted were added.
The authenticity of host 'master (192.168.1.180)' can't be established.
ECDSA key fingerprint is 22:5e:82:fa:7b:c3:26:de:30:76:73:bd:7c:a2:17:29.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: WARNING: All keys were skipped because they already exist on the remote system.
The authenticity of host 'slave1 (192.168.1.181)' can't be established.
ECDSA key fingerprint is 22:5e:82:fa:7b:c3:26:de:30:76:73:bd:7c:a2:17:29.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave1's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'slave1'"
and check to make sure that only the key(s) you wanted were added.
The authenticity of host 'slave2 (192.168.1.182)' can't be established.
ECDSA key fingerprint is 22:5e:82:fa:7b:c3:26:de:30:76:73:bd:7c:a2:17:29.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@slave2's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'slave2'"
and check to make sure that only the key(s) you wanted were added.
[root@master ~]# 然后在其他两个节点上执行sshUtil.sh
[root@slave1 ~]# sh sshUtil.sh
[root@slave2 ~]# sh sshUtil.sh (4)环境变量生效
[root@master ~]# source /etc/profile.d/custom.sh[root@slave1 ~]# source /etc/profile.d/custom.sh[root@slave2 ~]# source /etc/profile.d/custom.sh5.4 启动Hadoop集群
(0)清空数据
因为前面在192.168.1.180节点上搭建了Hadoop伪分布式环境,进行了namenode格式化,这里先清除一下Hadoop数据。如果之前没有进行Hadoopnamenode格式化,则不要清除。
[root@master ~]# rm -rf /tmp/*(1)namenode格式化
[root@master ~]# hdfs namenode -format
17/09/01 04:13:51 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = master/192.168.1.180
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.4
STARTUP_MSG: classpath = /opt/hadoop-2.7.4/etc/hadoop:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-compress-1.4.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-cli-1.2.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jettison-1.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/curator-framework-2.7.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-digester-1.8.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/httpclient-4.2.5.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jersey-server-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/mockito-all-1.8.5.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-httpclient-3.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jersey-core-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/xmlenc-0.52.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jersey-json-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/curator-client-2.7.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/avro-1.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-net-3.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/log4j-1.2.17.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/gson-2.2.4.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/hamcrest-core-1.3.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-io-2.4.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-configuration-1.6.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/activation-1.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jets3t-0.9.0.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jetty-util-6.1.26.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-collections-3.2.2.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/zookeeper-3.4.6.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jsch-0.1.54.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-math3-3.1.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/servlet-api-2.5.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-logging-1.1.3.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jsr305-3.0.0.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/xz-1.0.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jetty-sslengine-6.1.26.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/guava-11.0.2.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/httpcore-4.2.5.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/hadoop-auth-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/junit-4.11.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/paranamer-2.3.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/netty-3.6.2.Final.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jsp-api-2.1.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/asm-3.2.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/stax-api-1.0-2.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-codec-1.4.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/hadoop-annotations-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/jetty-6.1.26.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/opt/hadoop-2.7.4/share/hadoop/common/lib/commons-lang-2.6.jar:/opt/hadoop-2.7.4/share/hadoop/common/hadoop-nfs-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/common/hadoop-common-2.7.4-tests.jar:/opt/hadoop-2.7.4/share/hadoop/common/hadoop-common-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/commons-io-2.4.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/guava-11.0.2.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/asm-3.2.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/hadoop-hdfs-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/hadoop-hdfs-2.7.4-tests.jar:/opt/hadoop-2.7.4/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/guice-3.0.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/commons-cli-1.2.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jettison-1.1.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jersey-server-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jersey-core-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jersey-json-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/log4j-1.2.17.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/commons-io-2.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/activation-1.1.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/javax.inject-1.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jersey-client-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/servlet-api-2.5.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/xz-1.0.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/guava-11.0.2.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/asm-3.2.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/aopalliance-1.0.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/commons-codec-1.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/jetty-6.1.26.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/lib/commons-lang-2.6.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-client-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-common-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-api-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-server-common-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/yarn/hadoop-yarn-registry-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/guice-3.0.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/javax.inject-1.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/xz-1.0.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/junit-4.11.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/asm-3.2.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.4-tests.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.4.jar:/opt/hadoop-2.7.4/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.4.jar:/opt/hadoop-2.7.4/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = https://[email protected]/repos/asf/hadoop.git -r cd915e1e8d9d0131462a0b7301586c175728a282; compiled by 'kshvachk' on 2017-08-01T00:29Z
STARTUP_MSG: java = 1.8.0_144
************************************************************/
17/09/01 04:13:51 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
17/09/01 04:13:51 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-f377c031-d448-4e66-b06e-8ecd2eb7e57b
17/09/01 04:13:52 INFO namenode.FSNamesystem: No KeyProvider found.
17/09/01 04:13:52 INFO namenode.FSNamesystem: fsLock is fair: true
17/09/01 04:13:52 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
17/09/01 04:13:52 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
17/09/01 04:13:52 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
17/09/01 04:13:52 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
17/09/01 04:13:52 INFO blockmanagement.BlockManager: The block deletion will start around 2017 Sep 01 04:13:52
17/09/01 04:13:52 INFO util.GSet: Computing capacity for map BlocksMap
17/09/01 04:13:52 INFO util.GSet: VM type = 64-bit
17/09/01 04:13:52 INFO util.GSet: 2.0% max memory 889 MB = 17.8 MB
17/09/01 04:13:52 INFO util.GSet: capacity = 2^21 = 2097152 entries
17/09/01 04:13:52 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
17/09/01 04:13:52 INFO blockmanagement.BlockManager: defaultReplication = 1
17/09/01 04:13:52 INFO blockmanagement.BlockManager: maxReplication = 512
17/09/01 04:13:52 INFO blockmanagement.BlockManager: minReplication = 1
17/09/01 04:13:52 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
17/09/01 04:13:52 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
17/09/01 04:13:52 INFO blockmanagement.BlockManager: encryptDataTransfer = false
17/09/01 04:13:52 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
17/09/01 04:13:52 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
17/09/01 04:13:52 INFO namenode.FSNamesystem: supergroup = supergroup
17/09/01 04:13:52 INFO namenode.FSNamesystem: isPermissionEnabled = true
17/09/01 04:13:52 INFO namenode.FSNamesystem: HA Enabled: false
17/09/01 04:13:52 INFO namenode.FSNamesystem: Append Enabled: true
17/09/01 04:13:52 INFO util.GSet: Computing capacity for map INodeMap
17/09/01 04:13:52 INFO util.GSet: VM type = 64-bit
17/09/01 04:13:52 INFO util.GSet: 1.0% max memory 889 MB = 8.9 MB
17/09/01 04:13:52 INFO util.GSet: capacity = 2^20 = 1048576 entries
17/09/01 04:13:52 INFO namenode.FSDirectory: ACLs enabled? false
17/09/01 04:13:52 INFO namenode.FSDirectory: XAttrs enabled? true
17/09/01 04:13:52 INFO namenode.FSDirectory: Maximum size of an xattr: 16384
17/09/01 04:13:52 INFO namenode.NameNode: Caching file names occuring more than 10 times
17/09/01 04:13:52 INFO util.GSet: Computing capacity for map cachedBlocks
17/09/01 04:13:52 INFO util.GSet: VM type = 64-bit
17/09/01 04:13:52 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB
17/09/01 04:13:52 INFO util.GSet: capacity = 2^18 = 262144 entries
17/09/01 04:13:52 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
17/09/01 04:13:52 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
17/09/01 04:13:52 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
17/09/01 04:13:52 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
17/09/01 04:13:52 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
17/09/01 04:13:52 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
17/09/01 04:13:52 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
17/09/01 04:13:52 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
17/09/01 04:13:52 INFO util.GSet: Computing capacity for map NameNodeRetryCache
17/09/01 04:13:52 INFO util.GSet: VM type = 64-bit
17/09/01 04:13:52 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
17/09/01 04:13:52 INFO util.GSet: capacity = 2^15 = 32768 entries
17/09/01 04:13:52 INFO namenode.FSImage: Allocated new BlockPoolId: BP-593225014-192.168.1.180-1504253632799
17/09/01 04:13:52 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
17/09/01 04:13:52 INFO namenode.FSImageFormatProtobuf: Saving image file /tmp/hadoop-root/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
17/09/01 04:13:53 INFO namenode.FSImageFormatProtobuf: Image file /tmp/hadoop-root/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
17/09/01 04:13:53 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
17/09/01 04:13:53 INFO util.ExitUtil: Exiting with status 0
17/09/01 04:13:53 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at master/192.168.1.180
************************************************************/
[root@master ~]#
(2)启动HDFS
[root@master ~]# start-dfs.sh
Starting namenodes on [master]
master: starting namenode, logging to /opt/hadoop-2.7.4/logs/hadoop-root-namenode-master.out
master: starting datanode, logging to /opt/hadoop-2.7.4/logs/hadoop-root-datanode-master.out
slave1: starting datanode, logging to /opt/hadoop-2.7.4/logs/hadoop-root-datanode-slave1.out
slave2: starting datanode, logging to /opt/hadoop-2.7.4/logs/hadoop-root-datanode-slave2.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.4/logs/hadoop-root-secondarynamenode-master.out
[root@master ~]#[root@master ~]# jps
21024 DataNode
21319 Jps
20890 NameNode
21195 SecondaryNameNode
[root@master ~]#[root@slave2 ~]# jps
7282 Jps
7203 DataNode
[root@slave2 ~]#[root@slave1 ~]# jps
9027 Jps
8948 DataNode
[root@slave1 ~]#(3)启动YARN
[root@slave1 ~]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.4/logs/yarn-root-resourcemanager-slave1.out
slave1: starting nodemanager, logging to /opt/hadoop-2.7.4/logs/yarn-root-nodemanager-slave1.out
master: starting nodemanager, logging to /opt/hadoop-2.7.4/logs/yarn-root-nodemanager-master.out
slave2: starting nodemanager, logging to /opt/hadoop-2.7.4/logs/yarn-root-nodemanager-slave2.out
[root@slave1 ~]#[root@slave1 ~]# jps
8948 DataNode
9079 ResourceManager
9482 Jps
9183 NodeManager
[root@slave1 ~]#[root@slave2 ~]# jps
7203 DataNode
7433 Jps
7325 NodeManager
[root@slave2 ~]#
[root@master ~]# jps
21024 DataNode
21481 Jps
20890 NameNode
21195 SecondaryNameNode
21371 NodeManager
[root@master ~]#
(4)访问WEB
namenode在master节点,resourcemanager在slave1节点,每个节点都有nodemanager
- namenode界面:http://192.168.1.180:50070/
- resourcemanager界面:http://192.168.1.181:8088/
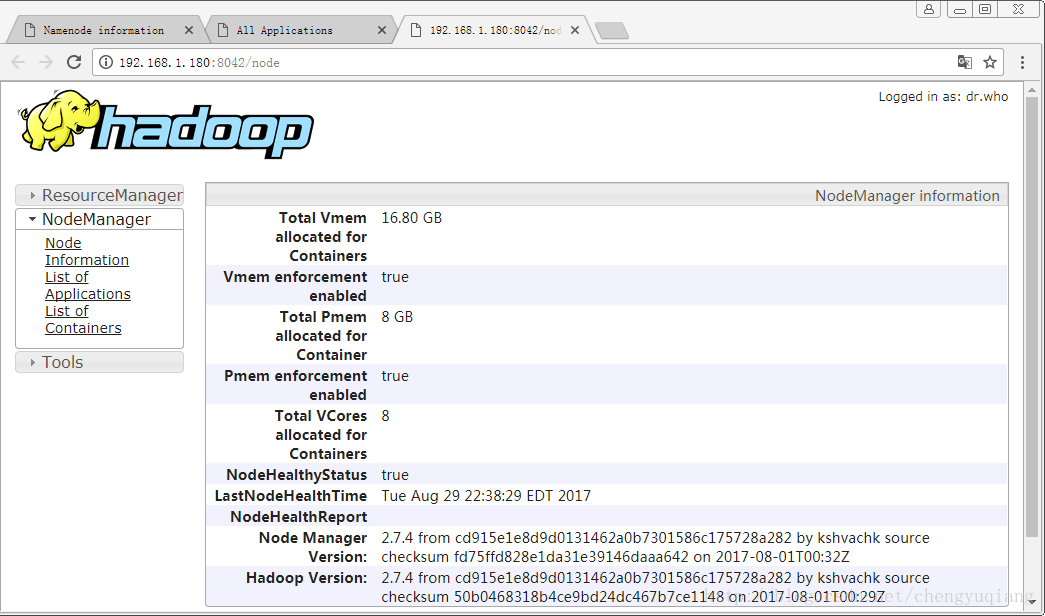
- nodemanager界面:http://192.168.1.180:8042
5.5 Spark下载
Spark on YARN运行模式,只需要在Hadoop分布式集群中任选一个节点安装配置Spark即可,不要集群安装。因为Spark应用程序提交到YARN后,YARN会负责集群资源的调度。
不失一般性,这里我们选择192.168.1.180节点安装Spark。
(1)下载Spark 2.2
Spark2.2下载具体步骤请参考:http://blog.csdn.net/chengyuqiang/article/details/77671748
选择国内镜像,通过wget命令wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz直接下载
[root@master ~]# wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
--2017-08-29 22:43:51-- http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.7.tgz
Resolving mirrors.tuna.tsinghua.edu.cn (mirrors.tuna.tsinghua.edu.cn)... 101.6.6.177, 2402:f000:1:416:101:6:6:177
Connecting to mirrors.tuna.tsinghua.edu.cn (mirrors.tuna.tsinghua.edu.cn)|101.6.6.177|:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 203728858 (194M) [application/octet-stream]
Saving to: ‘spark-2.2.0-bin-hadoop2.7.tgz’
100%[==================================================================================================================================>] 203,728,858 9.79MB/s in 23s
2017-08-29 22:44:15 (8.32 MB/s) - ‘spark-2.2.0-bin-hadoop2.7.tgz’ saved [203728858/203728858]
[root@master ~]#(2)然后解压缩,重命名
[root@master ~]# tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C /opt
[root@master ~]# mv /opt/spark-2.2.0-bin-hadoop2.7/ /opt/spark-2.2.05.6 Spark配置
(1)配置环境变量
编辑文件/etc/profile.d/custom.sh,增加如下内容
#spark path
export SPARK_HOME=/opt/spark-2.2.0
export PATH=${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH生效
[root@master ~]# source /etc/profile.d/custom.sh(2)spark-env.sh
执行下面命令,复制一份Spark的spark-env.sh模版,然后添加HADOOP_CONF_DIR一项。
配置到这里,Spark就可以跑在YARN上了,也没必要启动spark的master和slaves服务,因为是靠yarn进行任务调度,所以直接提交任务即可。
补充:有些关于Spark on YARN部署的博客,实际上介绍的是Spark的 standalone运行模式。如果启动Spark的master和worker服务,这是Spark的 standalone运行模式,不是Spark on YARN运行模式,请不要混淆。
5.7 spark-shell运行在YARN上
(1)运行在yarn-client上
执行命令spark-shell --master yarn-client,稍等片刻即可看到如下输出。
说明:从上面的spark-shell日志中看到spark-shell --master yarn-client命令从Spark2.0开始废弃了,可以换成spark-shell --master yarn --deploy-mode client。
(2)可能存在的问题
由于是在虚拟机上运行,虚拟内存可能超过了设定的数值。在执行命令spark-shell --master yarn-client时可能报错,异常信息如下。
[root@node1 ~]# spark-shell --master yarn-client
Warning: Master yarn-client is deprecated since 2.0. Please use master "yarn" with specified deploy mode instead.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/09/08 10:34:52 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/09/08 10:34:59 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
17/09/08 10:36:08 ERROR spark.SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master.
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:85)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:62)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:509)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2509)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:909)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:901)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:901)
at org.apache.spark.repl.Main$.createSparkSession(Main.scala:97)
at $line3.$read$$iw$$iw.<init>(<console>:15)
at $line3.$read$$iw.<init>(<console>:42)
at $line3.$read.<init>(<console>:44)
at $line3.$read$.<init>(<console>:48)
at $line3.$read$.<clinit>(<console>)
at $line3.$eval$.$print$lzycompute(<console>:7)
at $line3.$eval$.$print(<console>:6)
at $line3.$eval.$print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at scala.tools.nsc.interpreter.IMain$ReadEvalPrint.call(IMain.scala:786)
at scala.tools.nsc.interpreter.IMain$Request.loadAndRun(IMain.scala:1047)
at scala.tools.nsc.interpreter.IMain$WrappedRequest$$anonfun$loadAndRunReq$1.apply(IMain.scala:638)
at scala.tools.nsc.interpreter.IMain$WrappedRequest$$anonfun$loadAndRunReq$1.apply(IMain.scala:637)
at scala.reflect.internal.util.ScalaClassLoader$class.asContext(ScalaClassLoader.scala:31)
at scala.reflect.internal.util.AbstractFileClassLoader.asContext(AbstractFileClassLoader.scala:19)
at scala.tools.nsc.interpreter.IMain$WrappedRequest.loadAndRunReq(IMain.scala:637)
at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:569)
at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:565)
at scala.tools.nsc.interpreter.ILoop.interpretStartingWith(ILoop.scala:807)
at scala.tools.nsc.interpreter.ILoop.command(ILoop.scala:681)
at scala.tools.nsc.interpreter.ILoop.processLine(ILoop.scala:395)
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply$mcV$sp(SparkILoop.scala:38)
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply(SparkILoop.scala:37)
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply(SparkILoop.scala:37)
at scala.tools.nsc.interpreter.IMain.beQuietDuring(IMain.scala:214)
at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:37)
at org.apache.spark.repl.SparkILoop.loadFiles(SparkILoop.scala:98)
at scala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply$mcZ$sp(ILoop.scala:920)
at scala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply(ILoop.scala:909)
at scala.tools.nsc.interpreter.ILoop$$anonfun$process$1.apply(ILoop.scala:909)
at scala.reflect.internal.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:97)
at scala.tools.nsc.interpreter.ILoop.process(ILoop.scala:909)
at org.apache.spark.repl.Main$.doMain(Main.scala:70)
at org.apache.spark.repl.Main$.main(Main.scala:53)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:755)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:119)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
17/09/08 10:36:09 WARN cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors before the AM has registered!
17/09/08 10:36:09 WARN metrics.MetricsSystem: Stopping a MetricsSystem that is not running
org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master.
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:85)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:62)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:173)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:509)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2509)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:909)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$6.apply(SparkSession.scala:901)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:901)
at org.apache.spark.repl.Main$.createSparkSession(Main.scala:97)
... 47 elided
<console>:14: error: not found: value spark
import spark.implicits._
^
<console>:14: error: not found: value spark
import spark.sql
^
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_112)
Type in expressions to have them evaluated.
Type :help for more information.
scala>解决办法:
先停止YARN服务,然后修改yarn-site.xml,增加如下内容
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
</property>
将新的yarn-site.xml文件分发到其他Hadoop节点对应的目录下,最后在重新启动YARN。
再执行spark-shell --master yarn-client命令时,就不会报上面异常了。
(3)YARN WEB
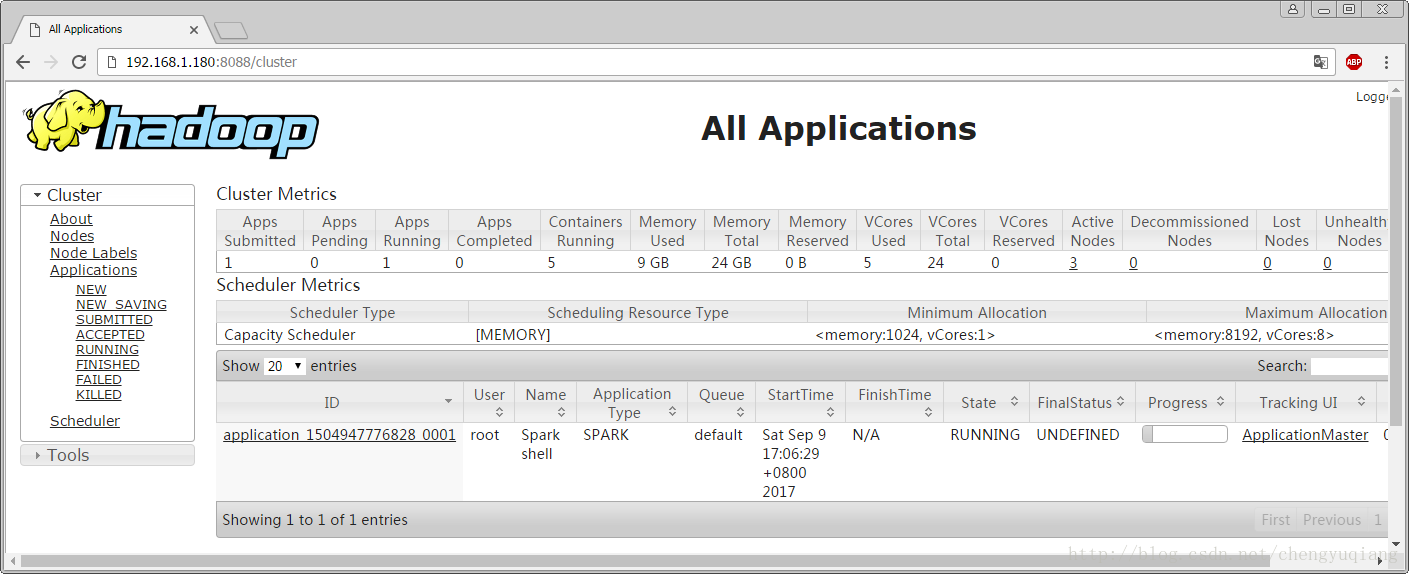
打开YARN WEB页面:192.168.1.180:8088
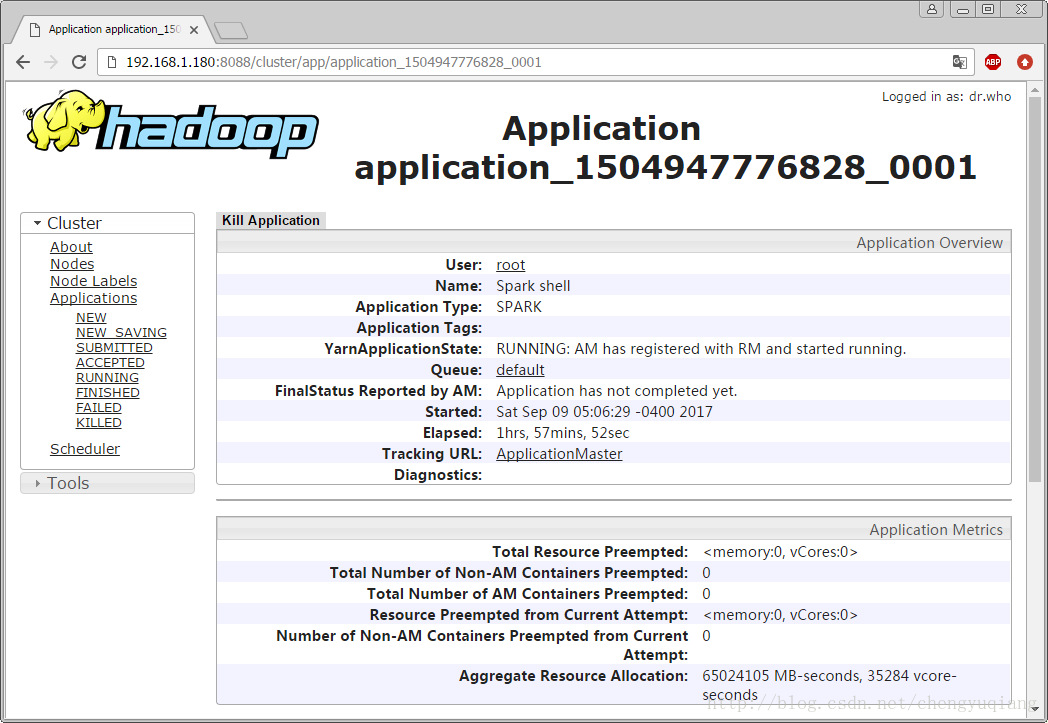
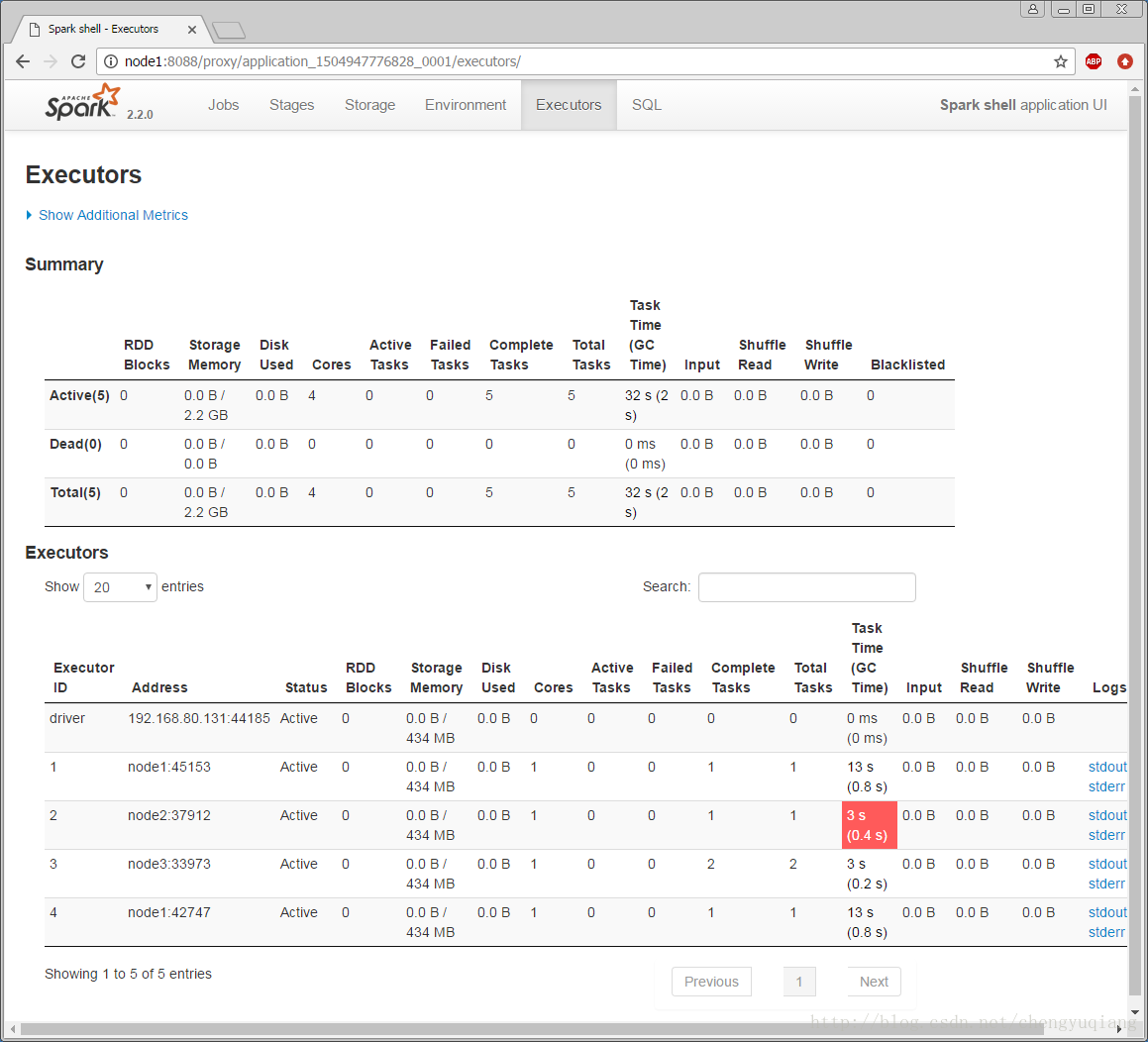
可以看到Spark shell应用程序正在运行,单击ID号链接,可以看到该应用程序的详细信息。
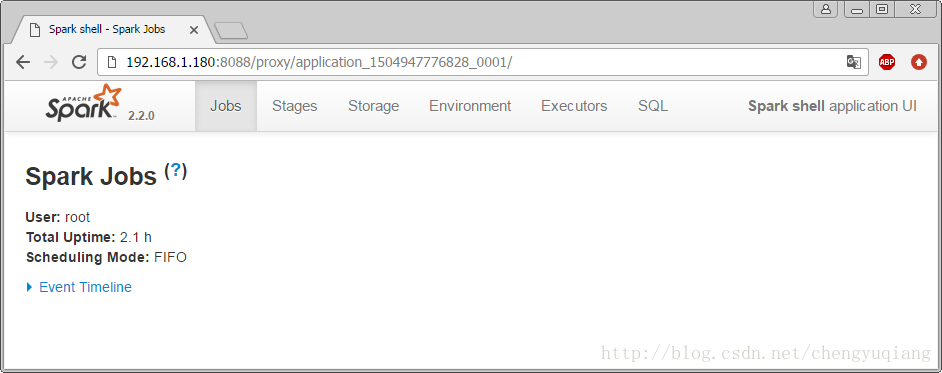
单击“ApplicationMaster”链接,
(4)运行程序
scala> val rdd=sc.parallelize(1 to 100,5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> rdd.count
res0: Long = 100
scala>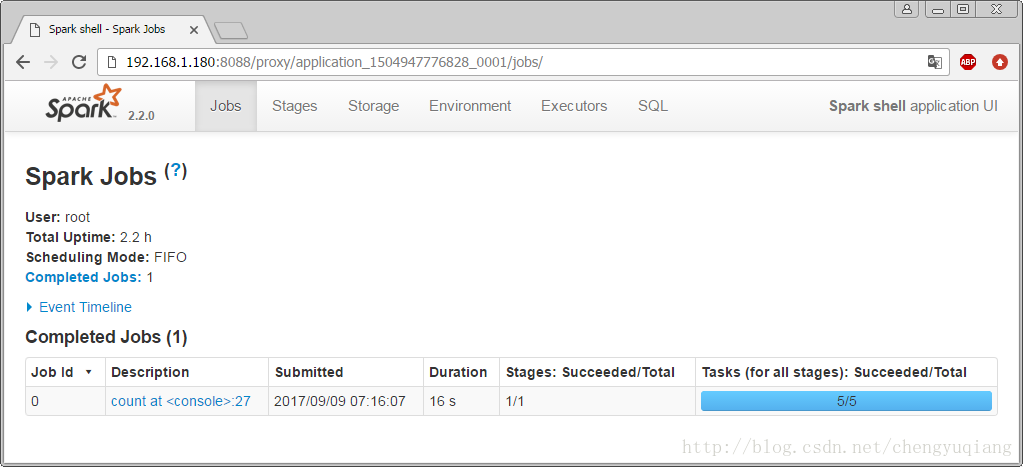
灰常灰常感谢原博主的辛苦工作,为防止删博,所以转载,只供学习使用,不做其他任何商业用途。
https://blog.csdn.net/chengyuqiang/article/details/77864246