在一个提交的一个Application中,如果遇见Shuffle算子的时候,那么就会发生任务的调度,当我们初始化SparkContext的时候,就会为我们创建两个对象,一个是DAGScheduler,一个是TaskScheduler
DAGScheduler中的实现
在DAGScheduler中的doOnReceive()方法中
,通过case 进行匹配事件类型 ,当匹配到JobSubmitted(job提交事件)的时候,会调用一个方法 dagScheduer.handlerJobSubmitted,这个方法里面又调用了submitStage(finalStage),finalStage的形成的是newResultsStage(finalRDD,func,partitions,jobId,callSite),这个finalRDD指的就是G这个RDD,根据finalRDD和传进来相关参数构建finalStage,在将finalStage丢进submitStage这个方法里面,submitStage方法是一个递归的方法,里面调用了getMissParentStages(stage),这个stage其实还是那个finalStage,getMissParentStages这个方法是一个非常关键的方法,在这个方法中首先定义了两个集合:
val missing = new HashSet[Stage] 用于存入被切分好的Stage
val visited = new HashSet[RDD[_]] 存放没被访问过的RDD的临时变量
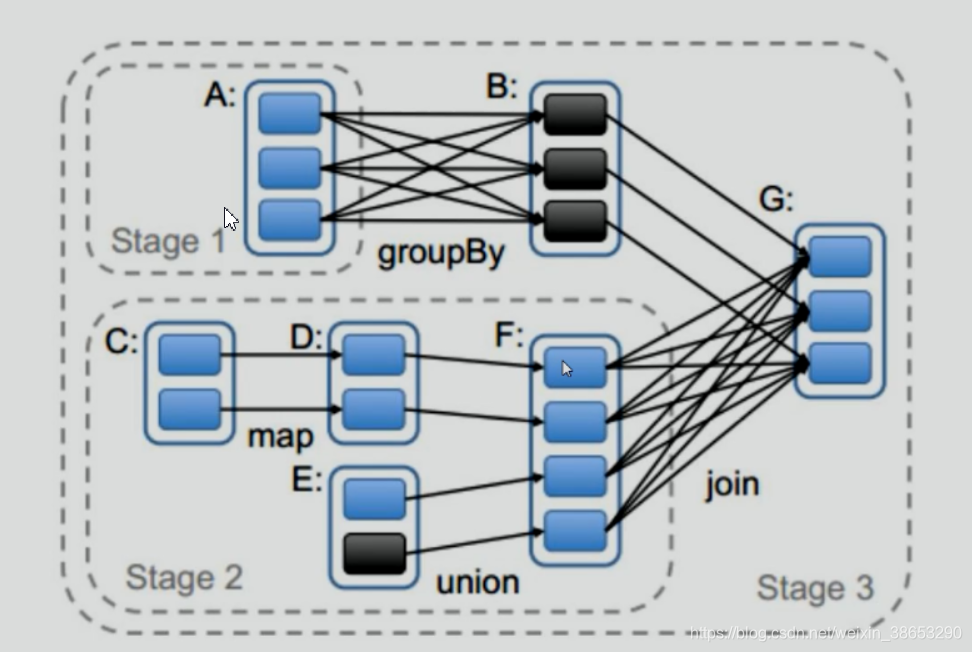
在这个方法里面通过stage.rdd先将finalRDD(G)放入栈中,然后调用这个方法里面的visit(waitingForVisit .pop),waitingForVisit = new StackRDD是一个栈,将G这个finalRDD弹栈,然后调用visit进行遍历,找出G这个RDD的所有依赖 ,在图中可以看到即与B是窄依赖,与F是宽依赖,比如说遍历的时候先遍历到窄依赖B,通过case到 NarrowDependency,然后将B压入栈中(以后通过再调用visit(waitingForVisit .pop)继续遍历B这个RDD的所有依赖),当匹配到F这个rdd的时候 是个宽依赖,然后开始划分stage,并将划分好的这个stage放入missing集合里面(从图中可以看出是会把A这个finalRDD组成的Stage和F这个finalRDD组成的Stage放进missing集合中),最后将miss这个集合toList后返回出去到submitStage这个方法里面,在这个里面判断miss的集合是否为空,如果不为空(说明可能还会有Stage的划分),则继续调用submitStage,然后将上面的过程循环往复,一直到没有算子之间的宽窄依赖,没有Stage的划分,那么missing的集合就会为空。当missing这个集合为空的时候,那么就不会在进行Stage的划分,而是进行submitMissingTasks(stage, jobId.get) 即开始将Stage划分为Task,并将Task封装为TaskSet提交到TaskScheduler上面。
submitStage方法:
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
//当所有的Stage划分之后,进行Task提交流程
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
getMissingParentStages方法
private def getMissingParentStages(stage: Stage): List[Stage] = {
//存放
val missing = new HashSet[Stage]
//存放没被访问过的RDD的临时变量
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]]
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
//如果这个RDD没被访问过就加入visited,下次循环就不会访问这个RDD了
visited += rdd
//做的双重检查:检查是否做了持久化操作
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
//Nil表示空list 当没有被持久化过的那么就是true,需要继续遍历上一个
//RDD的依赖
//只有到下次while循环才会遍历父RDD的依赖,可能一个或者多个
//其实这里主要是检测之前的createResultStage有没有成功创建好ShuffleMapStage
if (rddHasUncachedPartitions) {
for (dep <- rdd.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
//在之前的代码若成功创建了ShuffleMapStage
//那么就可以直接shuffleIdToMapStage拿取
val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
//判断map阶段是否准备好 也就是所有的partitions是否都有shuffle输出
//在直接创建shuffleMapStage的时候,会把shuffle信息注册到Driverv上的MapoutputTrackerMaster
//最终会用rdd.partitions.length == ShuffleStatus._numAvailableOut
if (!mapStage.isAvailable) {
//不相等则加入missing
missing += mapStage
}
//窄依赖就push回去 继续遍历
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
//把当前的stage的RDDpush进waitingForVisit
waitingForVisit.push(stage.rdd)
//一直循环到pop出所有的RDD
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())//第一次是将finalStage的rdd弹出栈放入visit方法中
}
missing.toList
}
DAGScheduler上的调度就先看到这里,TaskScheduler上的调度下回在分析