一、概述
上篇文章:Spark2.x精通:Shuffle原理及对应的Consolidation优化机制,讲解了Spark早期版本的Shuffle原理及其优化,文章结尾也已经提及Spark2.x中已经将Hash Shuffle废弃,我自己也去看了Spark2.2.0的源码,在Spark-env初始化中只保留了两种Shuffle:Sort、Tungsten-Sort,下面是源码截图:
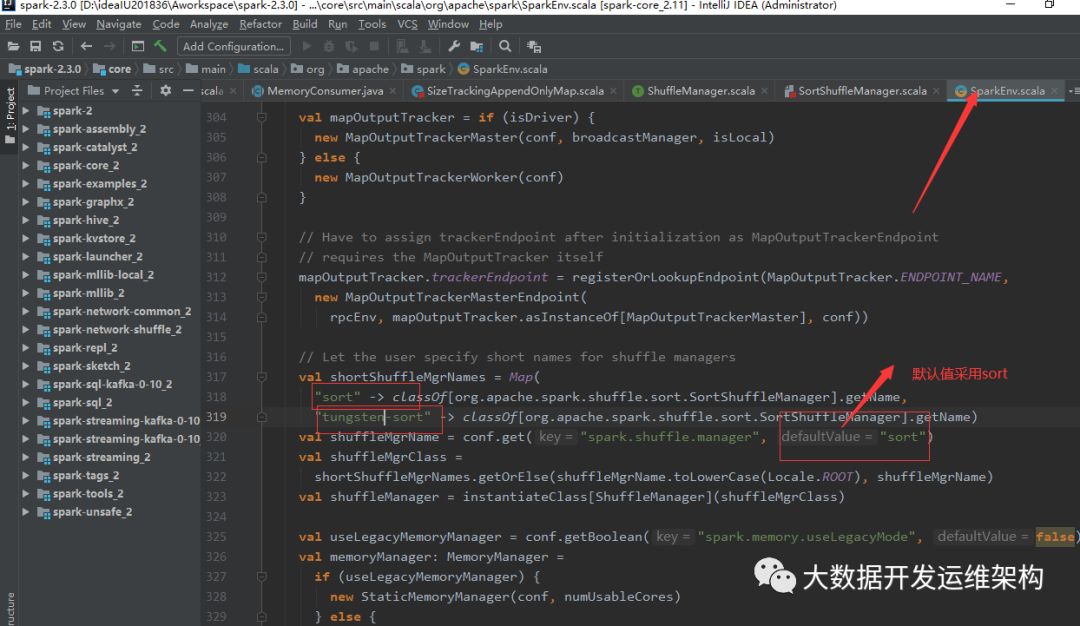
由于Spark Shuffle是Spark的核心之核心,为了对Spark Shuffle有更全面的认识,这里先来讲解一下Spark的技术演进历程及Shuffle阶段换分,后面文章再去对实现原理和源码进行深度剖析。
二、Spark Shuffle技术演进历程
1.Spark0.8以前,都是采用的HashShuffle,这是最开始的Shuffle,会存在生成很多小文件的问题,文件数M*R,其中M表示ShuffleMapTask个数,R表示Result个数;
2.Spark0.8.1中,引入了Consolidation优化机制,减少了小文件的生产,文件数变成了E*(C/T)*R,其中E表示Executor个数,C表示每个Executor中可用Core的个数,T表示Task所分配的Core的个数(默认值为1)。
3.Spark 0.9 中,引入ExternalAppendOnlyMap,combine的时候,可以将数据spill到磁盘,然后通过堆排序merge;
4.Spark 1.1 引入Sort Based Shuffle,但默认仍为Hash Based Shuffle,稍后会详解这种机制;
5.Spark 1.2 默认的Shuffle方式改为Sort Based Shuffle;
6.Spark 1.4 引入Tungsten-Sort Based Shuffle,将数据记录用序列化的二进制方式存储,把排序转化成指针数组的排序,引入堆外内存空间和新的内存管理模型,这些技术决定了使用Tungsten-Sort要符合一些严格的限制,比如Shuffle dependency不能带有aggregation、输出不能排序等。由于堆外内存的管理基于JDK Sun Unsafe API,故Tungsten-Sort Based Shuffle也被称为Unsafe Shuffle;
7.Spark 1.6 Tungsten-sort并入Sort Based Shuffle;
8.Spark 2.0 Hash Based Shuffle被启用,Sort Based Shuffle成为默认Shuffle机制。
三、Spark Shuffle的两阶段
Spark中有宽依赖、窄依赖两种,宽依赖会触发Stage的划分,这时候需要进行Shuffle,需要对RDD中的每个Paritioon数据进行重新分区,Spark Shuffle主要分成了两个阶段:Shuffle Write、Shuffle Read,两个阶段分属两个人Stage,前者属于父Stage,后者属于子Stage。
结合上篇文章的图我这里给他用不同颜色进行了标识,上面的部分是stage1中的ShuffleWrite负责Shuffle阶段数据写,下面就是stage0的中的ShuffleWrite负责Shuffle阶段数据读,如图所示:
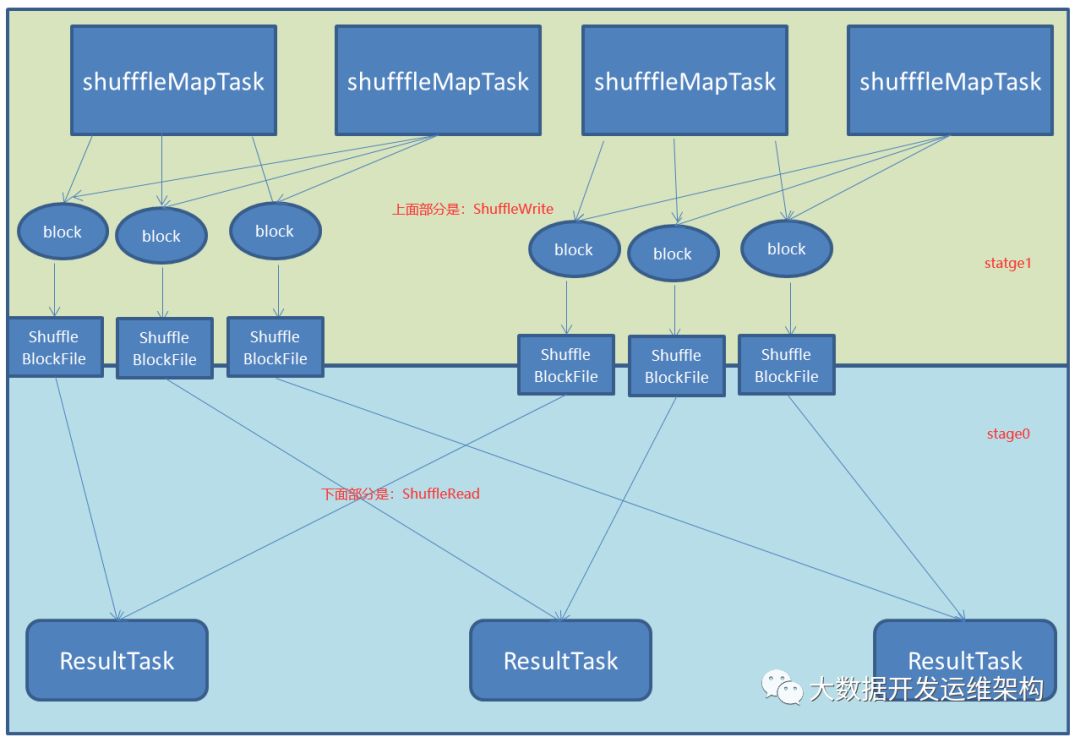
这里有一点需要说明一下:如果要按照map端和reduce端来分析的话,ShuffleMapTask可以即是map端任务,又是reduce端任务,因为Spark中的Shuffle是可以串行的;ResultTask则只能充当reduce端任务的角色。
Shuffle Write阶段
shuffle write阶段,主要就是在一个stage结束计算之后,为了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个task处理的数据按key进行“分类”。所谓“分类”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。
Shuffle Read阶段
shuffle read,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task为下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。