Python网络爬虫与信息提取笔记01-Requests库入门
Python网络爬虫与信息提取笔记02-网络爬虫之“盗亦有道”
Python网络爬虫与信息提取笔记03-Requests库网络爬虫实战(5个实例)
Python网络爬虫与信息提取笔记04-Beautiful Soup库入门
本文索引:
- “中国大学排名定向爬虫”实例介绍
- “中国大学排名定向爬虫”实例编写
- “中国大学排名定向爬虫”实例优化
1、 “中国大学排名定向爬虫”实例介绍
这一篇我们就是进行实例的实验了,是一个关于大学排名的的爬虫练习,首先我们来介绍一下这个例子的情况,首先针对大学的排名数不胜数,大多数的野榜也没有什么说服力,这里我们采用上海交通大学设计几种不同的排名方法,网址为:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html:

那么我们要做的就是用一段代码获取到这个排名并输出:
功能描述:
- 输入:大学排名URL链接
- 输出:大学排名信息的屏幕输出(排名,大学名称,总分)
- 技术路线:使用requests库和bs4库
- 定向爬虫:仅针对输入URL进行爬去,不扩展其他URL
因为我们这里先讲述静态网页的爬取方法,我们需要先确定这个网页页面是否为定向静态页面,我们在这个网页页面打开源代码,下拉找到第一的清华大学,发现这是用标签<tr>...</tr>来索引的,且各种信息都在这个标签内,所以这个定向的爬虫设计是可行的。

另外我们需要手动查看一下这个网站的Robots协议,发现不存在,这说明没有对爬虫进行相关的限制,我们就可以合法实现这个功能。

接下来就看一下这个程序的结构设计步骤:
- 从网络上获取大学排名网页内容
- 提取网页内容中信息到合适的数据结构
- 利用数据结构展示并输出结果
我们想到,这个最终的统计结果是一个二维数组(包括大学名称,总分,城市等信息),所以我们可以设计成一个二维列表,即列表的元素还是列表,我们对应上面的步骤可以定义3个函数分别对应上述三个步骤:getHTMLText()、fillUnivList()、printUnivList()。
2、“中国大学排名定向爬虫”实例编写
- 1、打开IDLE,File->New File,导入我们所需的requests和BeautifulSoup库。
import requests
from bs4 import BeautifulSoup- 2、先声明我们之前说到的三个主要函数,我们现在写框架,待会具体实现功能
def getHTMLText(url):
return ""
def fillUnivList(ulist,html):
pass # 不做任何处理
def printUnivList(ulist,num):
print("Suc" + str(num)) 这三个函数我们没有具体定义功能,但是需要清晰的定义他们的接口,第一个getHTMLText()的输入为一个url信息,输出为url内容,fillUnivList()则是将一个url页面放在一个列表中ulist,最后一个就是打印出列表ulist的内容,而这里我们又指定一个参数为num,即打印列表中多少组大学数据。
- 3、下面开始写主函数:
def main():
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html"
html = getHTMLText(url)
fillUnivList(unifo,html)
print(UnivList(unifo,20)
mian()- 4、下面我们需要完善三个函数进行功能的定义,利用我们之前说到的try和except代码框架:
第一个getHTMLText()函数主要完成获取网页的功能:
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30) # 获取网页信息,并设定生存时间30秒
r.raise_for_status() # 收集错误信息
r.encoding = r.apparent_encoding # 更改编码方式
return r.text
except:
return ""第二个fillUnivList()函数要玩好才能对输出结果的“美化”,我们先查看下网页的源代码:
<tbody class="hidden_zhpm" style="text-align: center;">
<tr class="alt">
<td>1</td><td><div align="left">清华大学</div></td><td>北京</td><td>94.6</td><td
class="hidden-xs need-hidden indicator5">100.0</td><td class="hidden-xs need-hidden
indicator6"style="display: none;">98.30%</td><td class="hidden-xs need-hidden
indicator7"style="display: none;">1589319</td><td class="hidden-xs need-hidden
indicator8"style="display: none;">48698</td><td class="hidden-xs need-hidden
indicator9"style="display: none;">1.512</td><td class="hidden-xs need-hidden
indicator10"style="display: none;">1810</td><td class="hidden-xs need-hidden
indicator11"style="display: none;">126</td><td class="hidden-xs need-hidden
indicator12"style="display: none;">1697330</td><td class="hidden-xs need-hidden
indicator13"style="display: none;">302898</td><td class="hidden-xs need-hidden
indicator14"style="display: none;">6.81%</td>
</tr>
<tr class="alt">
<td>2</td><td><div align="left">北京大学</div></td><td>北京</td><td>76.5</td><td
class="hidden-xs need-hidden indicator5">95.2</td><td class="hidden-xs need-hidden
indicator6"style="display: none;">98.07%</td><td class="hidden-xs need-hidden
indicator7"style="display: none;">570497</td><td class="hidden-xs need-hidden
indicator8"style="display: none;">47161</td><td class="hidden-xs need-hidden
indicator9"style="display: none;">1.409</td><td class="hidden-xs need-hidden
indicator10"style="display: none;">1402</td><td class="hidden-xs need-hidden
indicator11"style="display: none;">100</td><td class="hidden-xs need-hidden
indicator12"style="display: none;">554680</td><td class="hidden-xs need-hidden
indicator13"style="display: none;">14445</td><td class="hidden-xs need-hidden
indicator14"style="display: none;">6.15%</td>
</tr>是这样的格式,我们发现整个排名的列表是通过<tbody>...</tbody>标签来组织封装的,而各个大学的信息是通过<tr>...</tr>标签来组织封装的,大学的各个信息又是通过<td>...</td>标签来组织封装的,所以我们需要先找到tbody标签,解析<tr>标签,再将其中<td>标签的信息写到ulist列表中:
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string,tds[1].string,tds[2].string])这段代码中我们是利用前面所说的遍历和查找方法,然后需要判断tr标签的儿子标签(即<td>)中的数据类型,如果不是bs4库定义的Tag类型就过滤掉,这里我们需要在导入库处添加一个导入bs4库,注意这里我们导入的是bs4整个库,前面BeautifulSoup只是其中的一个类模块:
import bs4然后我们将tr标签中的td标签存到一个tds列表中,然后需要往里面添加列表信息,包括大学排名,大学名称和大学排分。
最后我们完善输出的格式化:
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))- 完整代码如下:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20)
main()运行结果:

3、“中国大学排名定向爬虫”实例优化
我们发现,乍一看输出的结果还算漂亮,但是中间还是会有瑕疵,比如中间列对齐问题,因为中间列为中文大学名称,所以对齐方式有问题,我们先看一下输出的格式函数:
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))- 中文对其问题的原因
| : | <填充> | <对齐> | <宽度> | , | <精度> | <类型> |
|---|---|---|---|---|---|---|
| 引导符号 | 用于填充的单个字符 | <左对齐 >右对齐 ^居中对齐 |
槽的设定输出宽度 | 数字的千位分隔符 适用于整数 和浮点数 |
浮点数小数部分 的精度或字符串 的最大输出长度 |
整数类型 b,c,d,o,x,X 浮点数类型 e,E,f,% |
当中文字符宽度不够时,采用西文字符填充;中西文字符占用宽度不同。
- 中文对齐问题的解决
采用中文字符的空格填充chr(12288)
我们可以对输出函数进行改造:
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))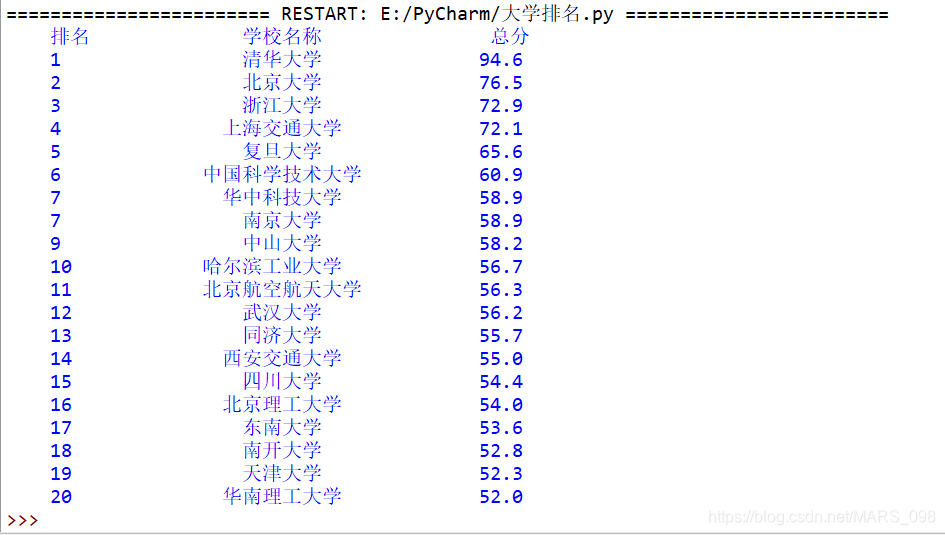
我们发现,此时的输出中文格式就是类似于excel表格的居中对齐了,希望以后在使用到爬虫输出多多使用练习,加油!!!