0.实例介绍
 右键点击查看源代码,ctrl+f查找清华大学找到相应数据。
右键点击查看源代码,ctrl+f查找清华大学找到相应数据。
查看robots协议:http://www.zuihaodaxue.cn/robots.txt 发现不存在,说明可以爬。

1.实例编写
import requests
from bs4 import BeautifulSoup #只是引入bs4类
import bs4 #引入bs4库
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children: #tr即每所大学
if isinstance(tr,bs4.element.Tag): #判断类型
tds=tr('td') #要对tr标签的td标签作查询
ulist.append([tds[0].string,tds[1].string,tds[2].string])
#将所有的td标签存在一个列表类型tds
def printUnivList(ulist,num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo=[] #将大学信息放在这个列表中
url='http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html'
html=getHTMLText(url)
fillUnivList(uinfo,html)#从html信息提取后放在uinfo变量中
printUnivList(uinfo,20) # 20 univs
main()
输出结果为:
排名 学校名称 总分
1 清华大学 北京
2 北京大学 北京
3 浙江大学 浙江
4 上海交通大学 上海
5 复旦大学 上海
6 中国科学技术大学 安徽
7 华中科技大学 湖北
7 南京大学 江苏
9 中山大学 广东
10 哈尔滨工业大学 黑龙江
11 北京航空航天大学 北京
12 武汉大学 湖北
13 同济大学 上海
14 西安交通大学 陕西
15 四川大学 四川
16 北京理工大学 北京
17 东南大学 江苏
18 南开大学 天津
19 天津大学 天津
20 华南理工大学 广东 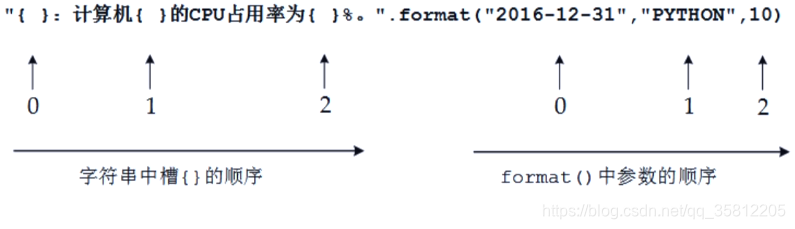
2.实例优化
优化原因:学校名称的中文格式不齐。
import requests
from bs4 import BeautifulSoup #只是引入bs4类
import bs4 #引入bs4库
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children: #tr即每所大学
if isinstance(tr,bs4.element.Tag): #判断类型
tds=tr('td') #要对tr标签的td标签作查询
ulist.append([tds[0].string,tds[1].string,tds[2].string])
#将所有的td标签存在一个列表类型tds
def printUnivList(ulist,num):
tplt="{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
def main():
uinfo=[] #将大学信息放在这个列表中
url='http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html'
html=getHTMLText(url)
fillUnivList(uinfo,html)#从html信息提取后放在uinfo变量中
printUnivList(uinfo,20) # 20 univs
main()
输出为
排名 学校名称 总分
1 清华大学 北京
2 北京大学 北京
3 浙江大学 浙江
4 上海交通大学 上海
5 复旦大学 上海
6 中国科学技术大学 安徽
7 华中科技大学 湖北
7 南京大学 江苏
9 中山大学 广东
10 哈尔滨工业大学 黑龙江
11 北京航空航天大学 北京
12 武汉大学 湖北
13 同济大学 上海
14 西安交通大学 陕西
15 四川大学 四川
16 北京理工大学 北京
17 东南大学 江苏
18 南开大学 天津
19 天津大学 天津
20 华南理工大学 广东3.单元小结
1