Python爬虫实例——2019中国大学排名100强
伪装headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0'
}
url地址
http://gaokao.xdf.cn/201812/10838484.html
url = 'http://www.shicimingju.com/book/sanguoyanyi.html'
请求
#请求
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8'
response = response.text
这个页面的content-type,没有使用charset:utf-8,所以我们要定义一下
response.encoding = ‘utf-8’

如果没有定义,得到结果全是乱码,具体的还要根据网页来说:
将页面的资源加载到BeautifulSoup对象中
soup = BeautifulSoup(response,'lxml')
然后分析一下网页,抓取我们想要的数据
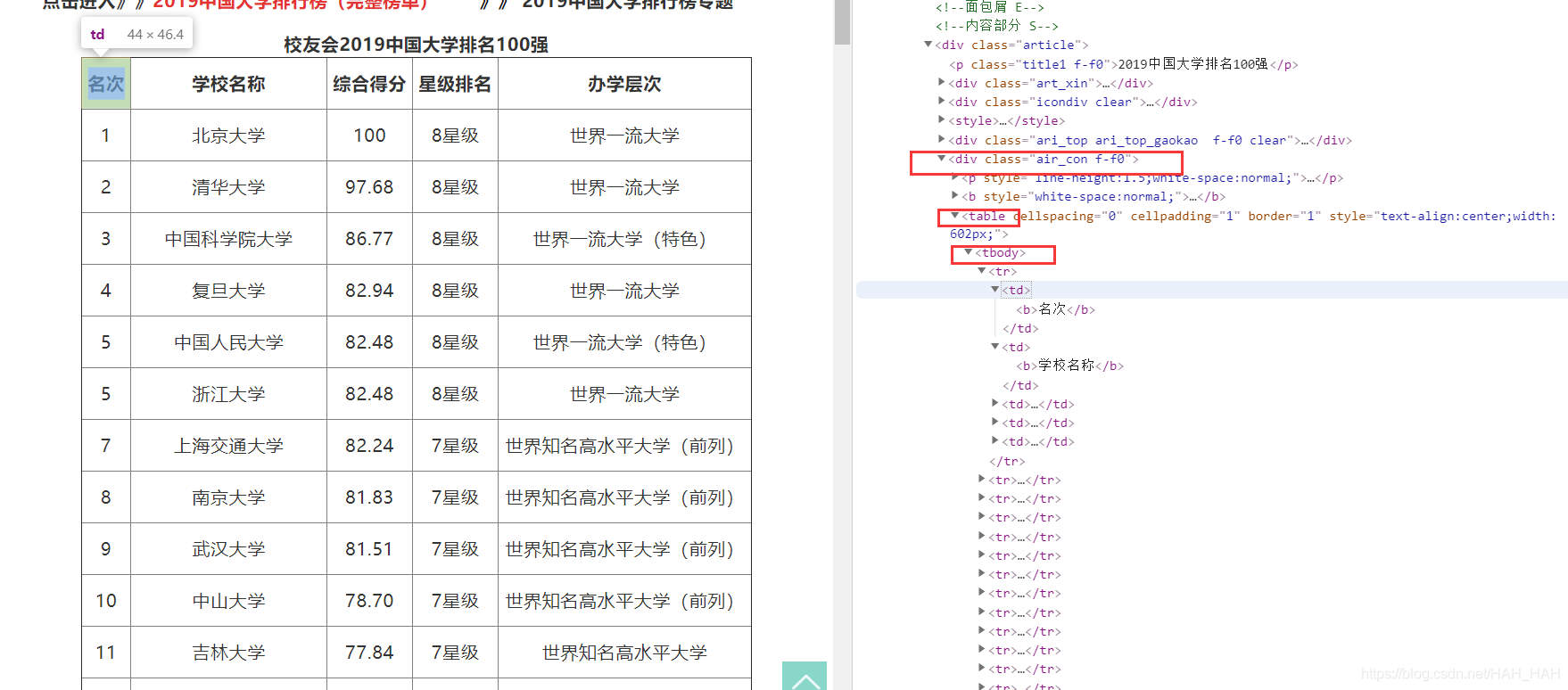
因为学校一百个呢,所以我们用select ()方法来进行数据分析,select返回的是一个列表,紧接着就可以循环列表分别解析每一个学校的数据
#获取学校的信息
schoole_list = soup.select('.air_con.f-f0 tr')
在这里注意一点:

在这里显示中间有一个空格,但是在select()中空格代表多个层级,如果在代码中使用空格的话是找不到相应的内容的。
直接copy selector
body > div.content.wrap1000 > div.conL-box > div > div.article > div.air_con.f-f0
这时看到其实中间是有“.”的
循环遍历出每个学校并持久化存储
for li in schoole_list:
detail = li.text
school_detail = (' '.join(detail.split())+'\n')
print(school_detail+'爬取成功!!!')
fp.write(school_detail)
在持久化存储时,我选择了直接存储到txt文本文件
但是循环出来的数据是列表的形式,所以我们需要进行转换
以school_list中第一个元素为例
title = schoole_list[0]
title_data = title.text
print(title_data)
结果:

所以先分片:
new_title = title_data.split()
分片结果:

下一步就是转化为字符串的形式:
new_data = (' '.join(new_title))
结果:

扫描二维码关注公众号,回复:
10527807 查看本文章

完整代码:
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
#伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0'
}
#url
url = 'http://gaokao.xdf.cn/201812/10838484.html'
fp = open('./高校.txt','w',encoding='utf-8')
#请求
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8'
response = response.text
#将页面的资源加载到BeautifulSoup对象中
soup = BeautifulSoup(response,'lxml')
#获取学校的信息
schoole_list = soup.select('.air_con.f-f0 tr')
# title = schoole_list[0]
# title_data = title.text
# new_title = title_data.split()
# new_data = (' '.join(new_title))
# print(new_data)
#text 读取标签下的所有内容,但是因为html中有大量的空格,所以对空格切片,
# 切片后的数据成为一个列表,把数据持久化存储到txt文件
for li in schoole_list:
detail = li.text
school_detail = (' '.join(detail.split())+'\n')
print(school_detail+'爬取成功!!!')
fp.write(school_detail)
踩过的坑:
- 爬取网页的时候首先要观察一下网页的信息
- 要注意文字格式的转换
- 要了解解析方法,清楚每个方法的作用,方法之间的不同
