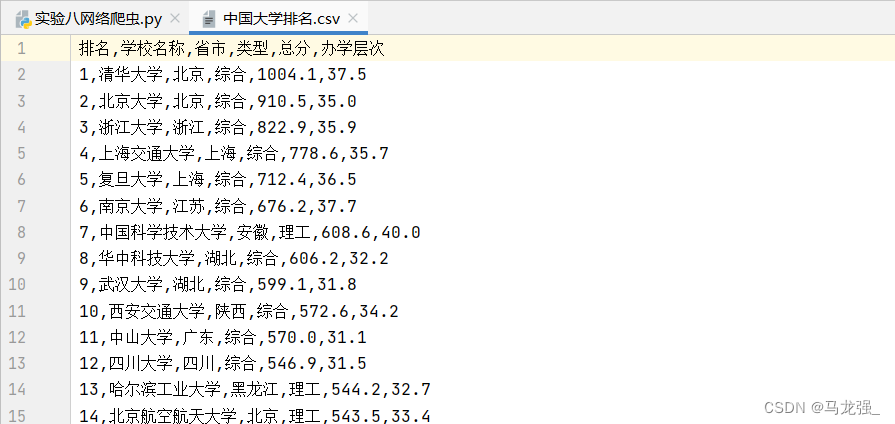
大学排名网址如下:
【软科排名】2023年最新软科中国大学排名|中国最好大学排名
网页内容信息
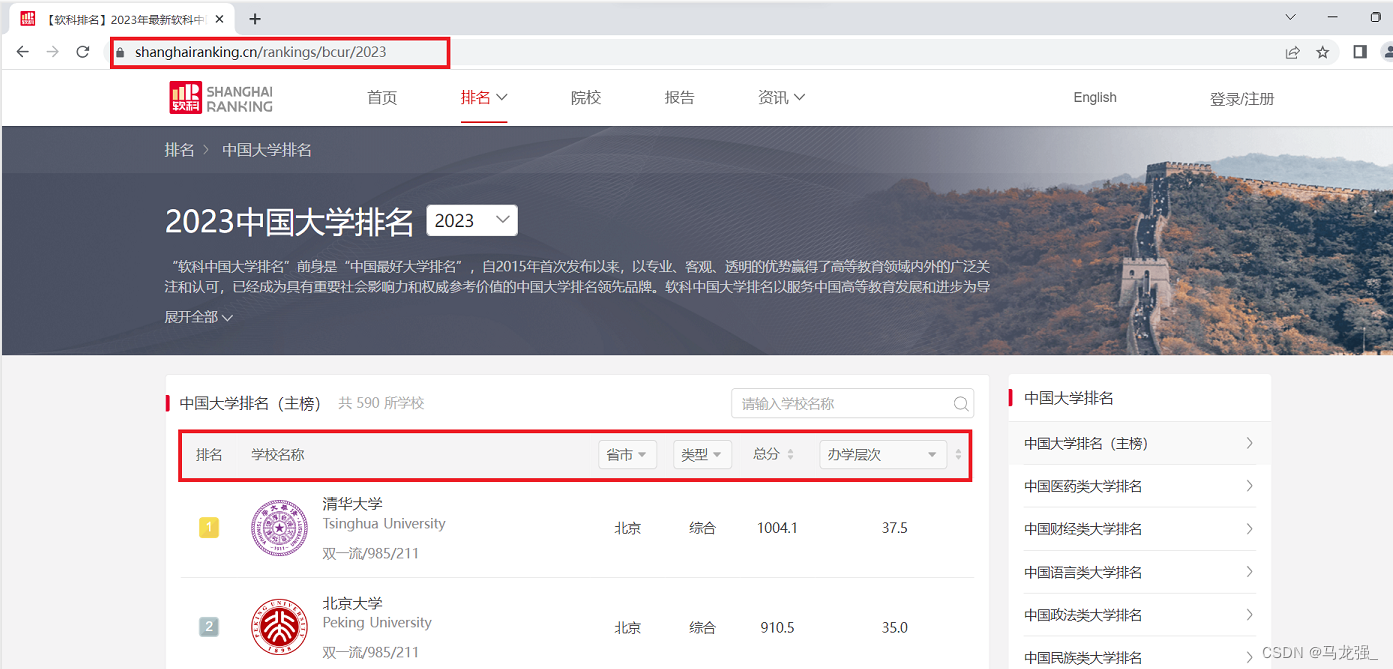
大学排名爬虫的构建需要三个重要步骤:
第一,从网络上获取网页内容;
第二,分析网页内容并提取有用数据到恰当的数据结构中;
第三,利用数据结构展示或进一步处理数据。
由于大学排名是一个典型的二维数据,因此,采用二维列表存储该排名所涉及的表单数据。
查找CSS 选择器,用于定位 HTML 元素
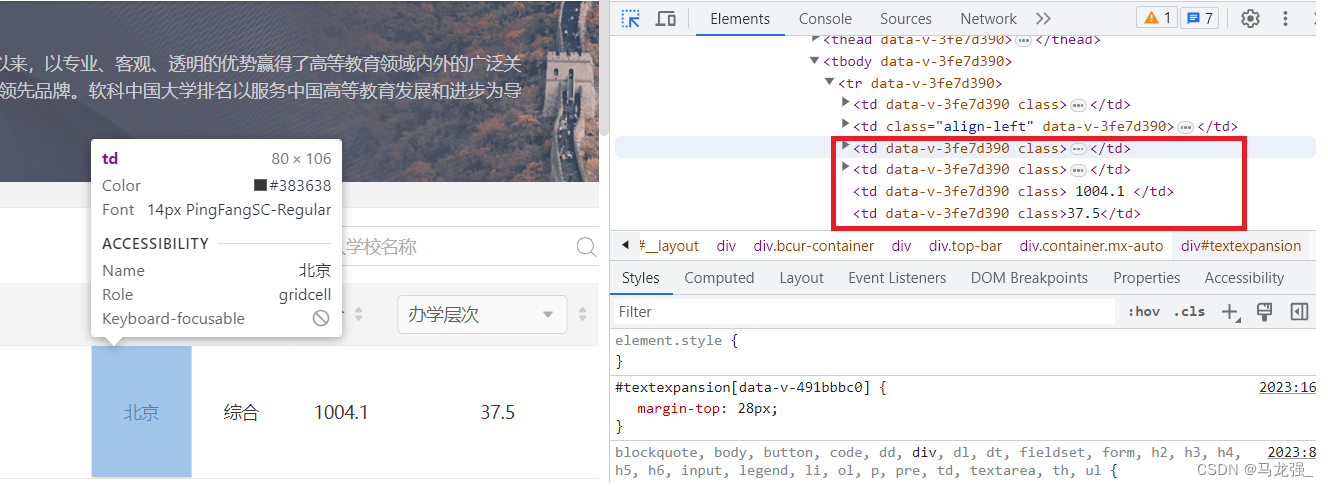
相关python代码:
# @Time: 2023/6/7 17:11
# @Author:
# @File: 实验八网络爬虫.py
# @software: PyCharm
import requests
import bs4
import csv
# 获取网页内容
def get_html(url):
response = requests.get(
url=url,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
)
response.encoding = response.apparent_encoding
html_text = response.text
return html_text
# 提取有用数据到恰当的数据结构中
def parse_html(html_text):
soup = bs4.BeautifulSoup(html_text, "html.parser")
table = soup.select("table[class='rk-table']")[0]
tbody = table.select("tbody")[0]
rows = tbody.find_all("tr")
data = []
for row in rows:
cols = row.find_all("td")
rank = cols[0].get_text().strip()
name = cols[1].select_one("div.univname div:nth-child(1) a").get_text().strip()
# type_elem = cols[1].select_one("div.univtype")
level = cols[2].get_text().strip()
score = cols[3].get_text().strip()
total_score = cols[4].get_text().strip()
educational_level = cols[5].get_text().strip()
data.append([rank, name, level, score, total_score, educational_level])
return data
# 创建 csv 文件并写入表头
with open('中国大学排名.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
# 将数据写入 csv 文件,并打印输出每个学校的信息
def write_to_csv(data):
with open('中国大学排名.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['排名', '学校名称', '省市' ,'类型', '总分', '办学层次'])
print("{:<5s}{:<13s}{:<10s}{:<10s}{:<10s}{:<10s}".format('排名', '学校名称', '省市' ,'类型', '总分', '办学层次'))
for item in data:
writer.writerow(item)
print("{:<5s}{:<13s}{:<10s}{:<10s}{:<10s}{:<10s}".format(item[0], item[1], item[2], item[3], item[4], item[5]))
def main():
# 从网络上获取网页内容
url = "https://www.shanghairanking.cn/rankings/bcur/2023"
html_text = get_html(url)
# 分析网页内容并提取有用数据到恰当的数据结构中
data = parse_html(html_text)
# 将数据写入 csv 文件,并打印输出每个学校的信息
write_to_csv(data)
if __name__ == '__main__':
main()爬取排名前30所大学信息,并生成csv文件
打印输出内容:
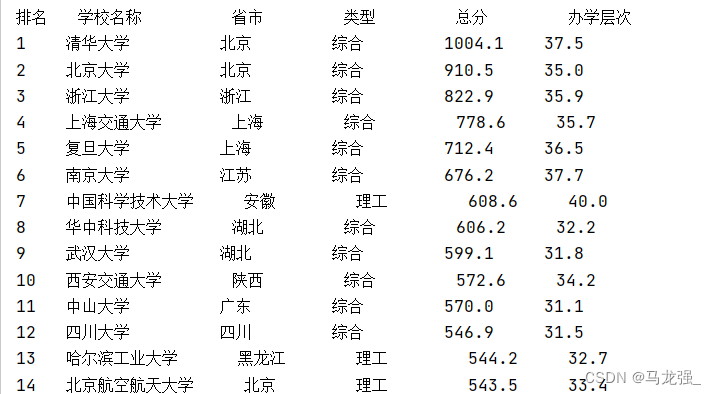
csv文件内容: