一、二叉堆
二叉堆本质上是一种完全二叉树,它分为两个类型:
- 最大堆:最大堆任何一个父节点的值,都大于等于它左右孩子节点的值。
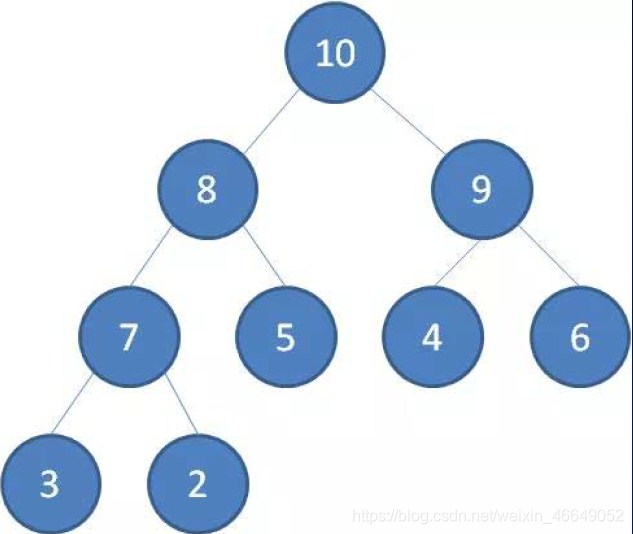
- 最小堆:最小堆任何一个父节点的值,都小于等于它左右孩子节点的值。
二叉堆的根节点叫做堆顶。最大堆和最小堆的特点决定了在最大堆的堆顶是整个堆中的最大元素;最小堆的堆顶是整个堆的最小元素。
二、堆的自我调整
1.插入节点
下面以最小堆为例,看看二叉堆是如何进行调整的?
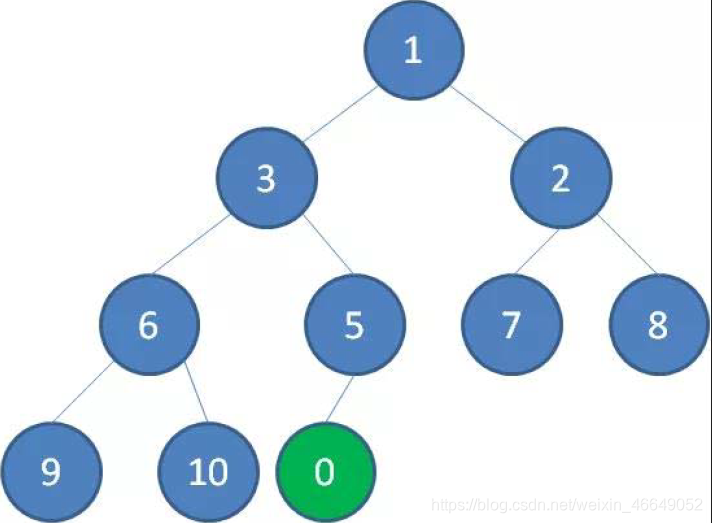
如图所示,在二叉堆中插入节点0,节点0与节点5不满足二叉堆的结构,所以节点0与节点5进行交换;节点0与节点3不满足二叉堆的结构,所以节点0与节点3进行交换,同时,交换后看节点3与节点5是否满足二叉树的结构,满足!节点0与节点1不满足二叉树的结构,两者进行交换,同时,同理看节点1与节点3是否满足二叉树的结构。
主要原则:
插入节点与父节点是否满足二叉堆的结构,如果不满足,则插入节点向上调整,父节点向下调整。
2.删除节点
删除节点即从堆中pop节点,一般是pop堆顶。下面以最小堆为例,展示二叉堆是如何删除节点的?
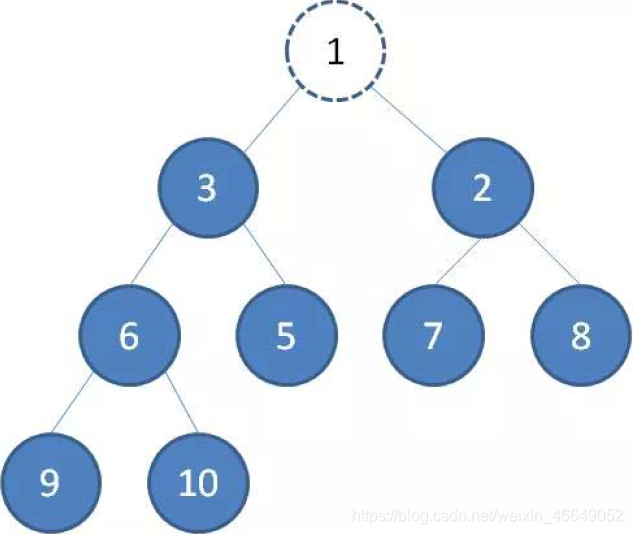
当我们删除最小堆的堆顶(并不是完全删除,而是替换到最后面)
如图所示,先把堆顶节点1与最后面的叶子节点10交换。然后看节点10是否满足二叉堆的结构,如果不满足,则向下调整,节点10与小的叶子节点2进行交换(如果与叶子节点3进行交换,仍然不会满足二叉堆结构),节点10仍然不满足最小堆的定义,与叶子节点7进行交换。
3.构建二叉堆
构建二叉堆。就是把一个无序的完全二叉树调整为二叉堆,本质上就是让所有非叶子节点一次下沉。
- 自下而上
- 自上而下
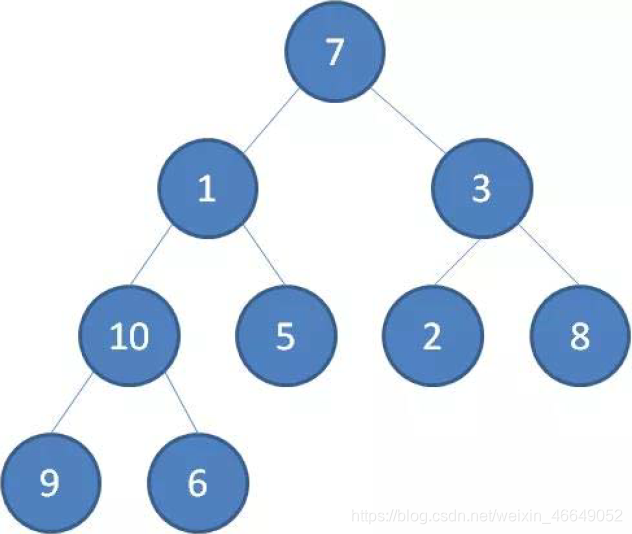
下面叙述自下而上的方式将上述无序二叉树调整成最小堆:
首先,节点6与节点10交换,节点2与节点3进行交换,由于节点5与节点2在原二叉树中为叶子节点,所以无需在向下调整。节点1与节点7交换,节点7向下调整,节点7与节点5交换,最小二叉堆建立完毕!
三、堆的实现
二叉堆虽然是一颗完全二叉树,但是它的存储方式并不是链式存储,而是顺序存储。换句话说,二叉堆的所有节点都存储在数组中。
那么,如何来定位孩子节点的父节点或者父节点的孩子节点呢?
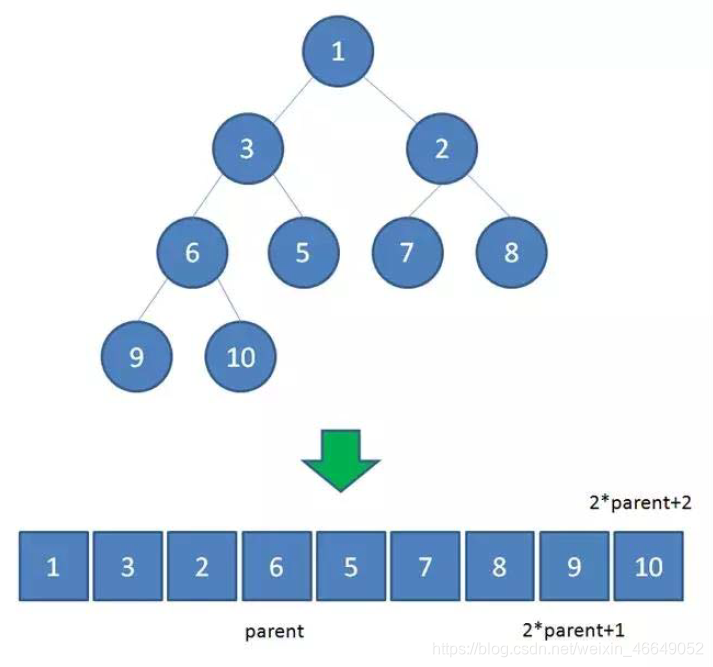
二叉堆可以转化成数组。数组也可以转化成二叉堆。数组中孩子节点与父节点的索引关系如下:
如果父节点的索引为n,两个子节点的索引分别为2n+1,2n+2。
如上图所示,节点6,9,10的索引分别为3,7,8.
7 = 2×3 + 1
8 = 2×3 + 2
如果已知子结点索引,(子节点索引 - 1)/2再向下取整。
四、LeetCode
215.在未排序的数组中找到第k个最大的元素(需要找的是数组排序后第k个最大的元素)
输入:[3,2,1,5,6,4]和k
输出:5
class Solution():
def findKthLarget(self, nums, k):
self._k = k
return self.heap_sort(nums)
def heap_sort(self, nums):
"""
堆排序
将根节点取出与最后一位做对调,对前面len-1个节点继续进行堆调整过程
:param nums: 数组
:return:
"""
self.build_max_heap(nums)
print(nums)
cnt = 0
# 调整后列表的第一个元素就是这个列表中最大的元素,
# 将其与最后一个元素交换,然后将剩余的列表再递归的调整为最大堆
for i in range(len(nums) - 1, -1, -1):
nums[0], nums[i] = nums[i], nums[0]
cnt += 1
if cnt == self._k:
return nums[i]
self.max_heapify(nums, i, 0)
def build_max_heap(self, nums):
"""
构建最大堆
:param nums: 数组
:return: 最大堆
"""
length = len(nums)
for i in range((length - 2) // 2, -1, -1): # 自底向上建堆
self.max_heapify(nums, length, i)
def max_heapify(self, nums, length, root):
'''
调整列表中的元素并保证以root为根的堆是一个大根堆
给定某个节点的下标root,这个节点的父节点、左子节点、右子节点的下标都可以被计算出来。
索引从0开始时
父节点:(root-1)//2
左子节点:2*root + 1
右子节点:2*root + 2 即:左子节点 + 1
'''
left = 2 * root + 1
right = left + 1
larger = root
if left < length and nums[larger] < nums[left]:
larger = left
if right < length and nums[larger] < nums[right]:
larger = right
# larger的值等于左节点或者右节点的值时,需要做堆调整
if larger != root:
nums[larger], nums[root] = nums[root], nums[larger]
# 递归的对子树做调整
self.max_heapify(nums, length, larger)
def main():
nums = [3,2,1,5,6,4]
k = 2
s = Solution()
kth_element = s.findKthLarget(nums, k)
print('数组中第%d个最大元素为%d' % (k, kth_element))
if __name__ == '__main__':
main()
[6, 5, 4, 3, 2, 1]
数组中第2个最大元素为5