随便说几句
打完游戏
(带妹儿)、和学习之余,最喜欢看电影啦~
开学了,无聊的时候挑一部高分电影欣赏欣赏
而豆瓣电影:
号称提供最新的电影介绍及评论包括上映影片的影讯。
来这里找 高分的电影再好不过。
'''
博文说明:
编写时间: 2021-03-01
爬取入口url: https://movie.douban.com/top250
用到的库:request,fake-useragent,BeautifulSoup csv
工具:python 3.9、Pycharm、Chorme Browser
采用: select 方法来定位标签
爬取如下字段:
{
'排名':rank,
'标题': title,
'简介': info,
'影评':quote,
'电影评分': score,
'详情URL':movie_url,
'照片URL': movie_pic,
}
保存到: .csv 格式
'''
假设用到的库、工具都准备好了、也会使用啦,那么…
一、首先当然是分析网站
1.用打开website 豆瓣TOP 250 https://movie.douban.com/top250
2.按F12 打开chorme Developer Tools (开发者工具)
3.然后这样点Network 刷新页面,按F5 或者Ctrl + R,于是就会记录到network activity…
也就是记录
页面上的网络请求的详情信息,
从发起网页页面请求Request后分析HTTP请求后得到的各个请求资源信息
(包括状态、资源类型、大小、所用时间、Request和Response等)

一般第一个记录就是website url对应的web响应

4.然后点开top250,查看请求头Headers和预览Previw一下top250的 “样子”
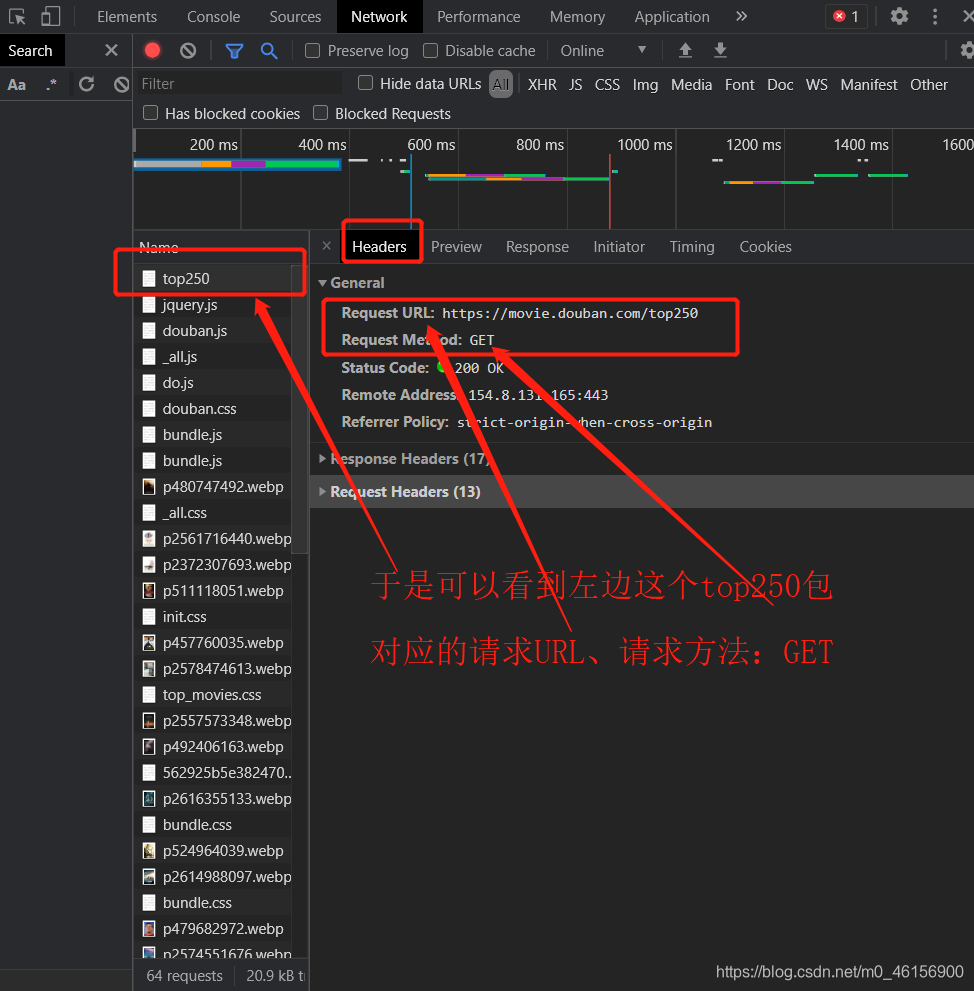
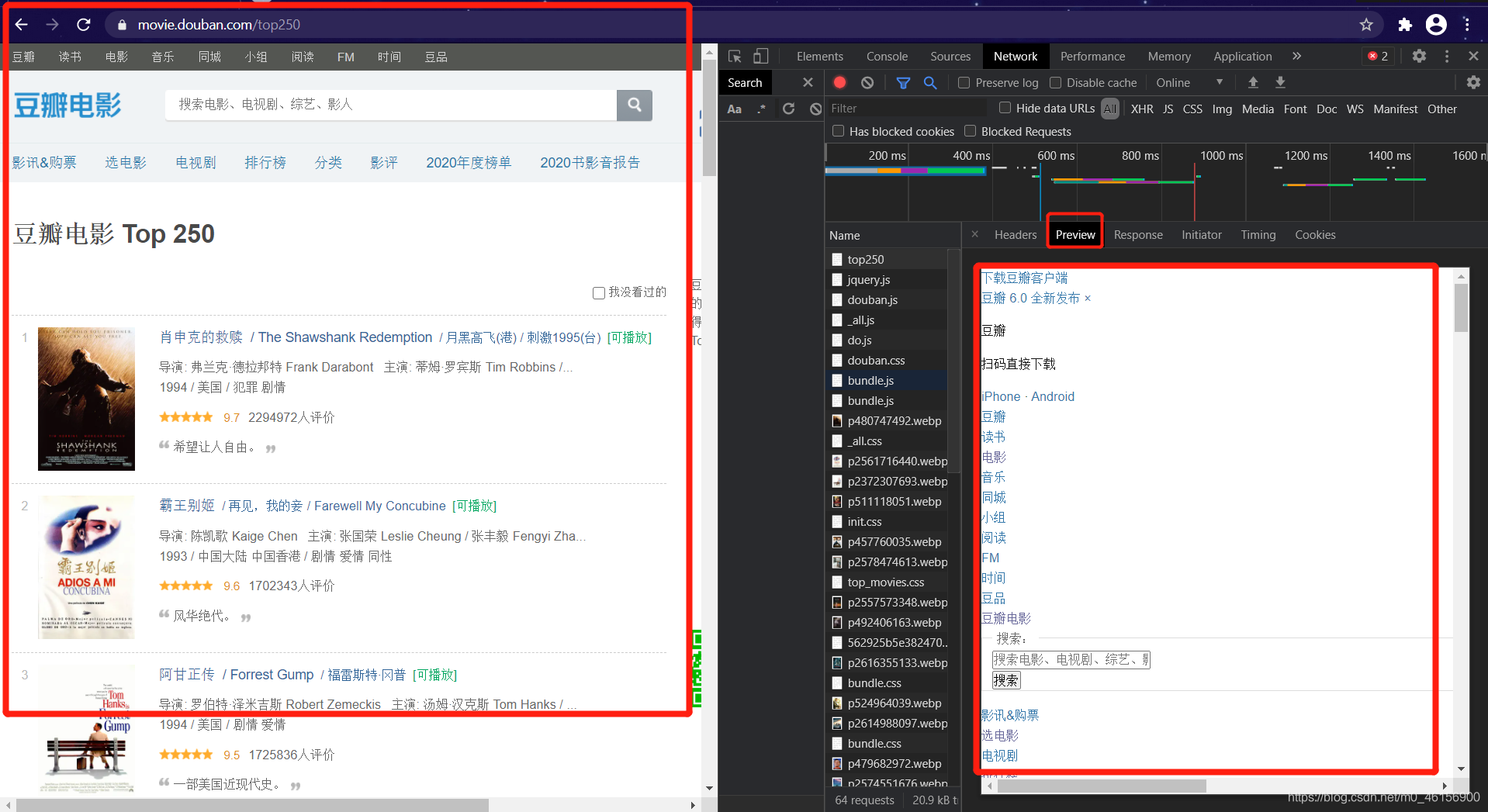

可以看到Top 250 Preview的 “样子(右边)”,和 浏览器下的样子(左边)
是比较相似的
在Top 250里面有我们需要的电影列表,页数。
为什么要查看
Top 250这个包呢?
因为有时候,请求的url所返回的response里面,并没有,自以为有的,所需要的东西
当没有的时候,就要考虑抓取别的"Top 250",也就是抓包了。
目前看来爬取豆瓣Top250不用抓包,比较简单。
电影列表就在请求的url(https://movie.douban.com/top250)里。
5.分析电影的html标签
有两种定位页面对象(比如网页的图片、文字)的办法:
选中对象,鼠标右键 ——> 检查
F12,打开开发者工具, 点一个左上角的按钮,再去选中对象


6.分析翻页
我复制了一下1~4页,翻页逻辑一目了然,

我们可以大胆的猜测:
这个start参数值,就是从哪个电影开始显示。
而且不一定要25、25地递增。
下面start=249,直接就返回了最后一部电影
当然,start >= 250的时候就没有电影返回了

可以发现,每次最多返回25部电影

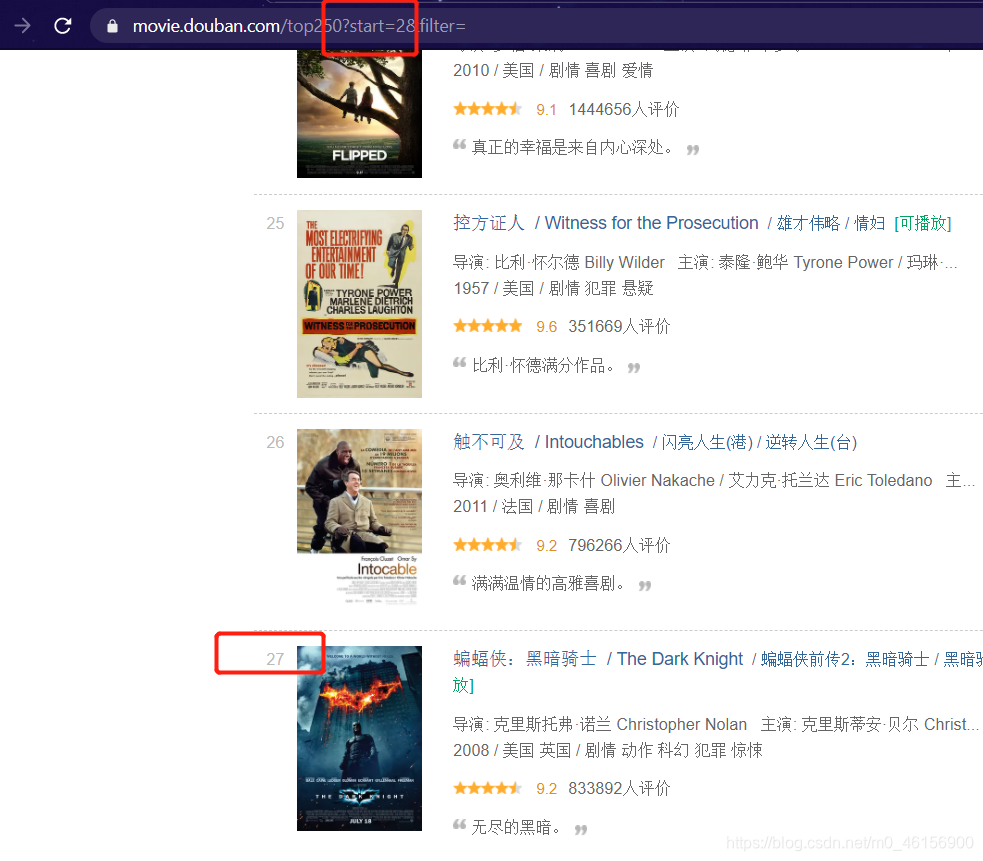
而且 &filter= 是无效参数,可以删掉~
是不是so easy~ ~!!
二、磨刀不误砍柴工,开始码代码
先上代码
import requests
from bs4 import BeautifulSoup as bs
from fake_useragent import UserAgent
import csv
def get_html(url):
ua = UserAgent()
try:
r = requests.get(url,headers={
'User-Agent':ua.random}) # ua.random 返回一个随机user-agent。
# 如果不加 headers = {...} 返回的Response(响应)就不是200(也就是响应异常)
return r.text
except:
print('Request ERROR')
def parse_html(url):
all_items = []
soup = bs(get_html(url),'html.parser') # 做一碗美丽汤~
items = soup.select('.item') # soup.select()返回一个列表,每个列表元素是一个item标签
for i in items: # 一个i(item) 就是一个数据元素(电影)、有许多数据项(排名、标题、...)
rank = i.select_one('em').text # 排名
movie_url = i.select_one('a').get('href') # 电影详情url
movie_pic = i.select_one('a img').get('src') # 电影图片url
title = i.select_one('.hd >a ').text.replace('\n','').strip() # 电影标题。去掉换行符、首尾的空格
info = i.select_one('.bd').text.replace('\n','').strip() # 导演、主演。去掉换行符、首尾的空格
score = i.select_one('.rating_num').text # 评分
try:
quote = i.select_one('.inq').text # 影评
except:
quote = None
print(f'《{title}》没有引用影评')
all_items.append( # 每个被append到all_items里面的,是一个 字典。有如下键值对
{
'排名':rank,
'标题': title,
'简介': info,
'影评':quote,
'电影评分': score,
'详情URL':movie_url,
'照片URL': movie_pic,
}
)
return all_items
def save2file(all_items):
keys = all_items[0].keys() # 返回dict_keys类型,其实可以看作列表。形如dict_keys(['排名', '标题', '简介',...])
with open('豆瓣TOP250.csv', 'w', newline='', encoding='utf-8') as output_file:
dict_writer = csv.DictWriter(output_file, keys) # 把字典写入CSV 文件
# 没有字段名列表的话,DictWriter就无法知道使用哪些键来从字典中检索值,它还使用字段名中的键将第一行写为列名。
dict_writer.writeheader() # 写header,即第一行
dict_writer.writerows(all_items) # 用keys为检索,每一行,写一个item值
output_file.close()
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start={}'
all_items = [] # 用来存所有item字典
for i in range(0, 250, 25):
print(f'正在爬取{url.format(i)}','')
items = parse_html(url.format(i)) # 返回前25名的电影items
all_items += items
print('爬取成功')
save2file(all_items)
print("爬取结束。")
关于我的代码(大概写一下给小白同学康康~)
首先呢,requests、bs4的用法,边查文档,边写多了,就炉火纯青啦,不成问题。
下面解释一下BeautifulSoup对象的 .select的用法
比如soup.select('.quote')
表示找到所有的
class = quote的标签。"."(小数点) 代表class
返回的是一个列表。(若没找到,就是空列表)
之后遍历这个列表。
.text拿的是标签中间的字符串,比如上图就是“王家卫…代表”
.attrs['class']拿的是属性class的属性值,比如上图就是“inq”

同理items = soup.select('.item')
表示找到所有的
class = item的标签。"."(小数点) 代表class
返回的是一个列表。(若没找到,就是空列表)
又比如title = i.select_one('.hd >a ')
表示找每一个i下面的,
满足class = hd所包含的直接子标签,名为a的第一个标签。
因为是select_one(),所以返回第一个满足查找条件的标签,
(如果没有找到,就是Nonetype)
成品截图:
