前言:
任意目标检测网络提高inference效率的两个方向:
- 减少处理的像素数量。
- 减少每个像素的处理过程。
CornerNet-Saccade:通过减少处理的像素个数来提高inference的效率。
实现方式:使用注意力机制(attention)消除了对图像的所有像素进行处理的需要,将cornernet单阶段检测器变为两阶段检测器。首先经过一个下采样后的输入图像,生成一个attention map,接着再将进行放大处理,然后进行后续的处理。
一、CornerNet-Saccade
Saccades:(扫视运动),模仿人类视觉眼睛的扫视,这里是指在推理时选择性的裁剪和处理图像区域。
- R-CNN系列论文中:saccades机制为single-type和single-objdet,即产生proposal的时候为单类型(前景类)、单目标(每个proposal中仅含有一个物体或没有)。
- CornerNet-Saccade中:saccades是single type和multi-objdet(每个裁剪区域中可以含有多个目标物体)。

估计目标位置(Estimating Object Locations)
CornerNet-Saccade第一阶段:通过下采样图片预测attention maps和coarse bounding box(粗糙边界框 ),以获得图片中物体的位置和粗略尺寸,这种降采样方式有助于减少推理时间和便于上下文信息获取。
流程细节:
1、首先将原始图片缩小到两种尺寸:长边为255或192像素,192填充0像素到255,然后并行处理。
2、经过hourglass-54(由3个hourglass module组成),在hourglass-54的上采样层预测3个attention maps(分别接一个3×3 Conv-ReLU module和一个1×1 Conv-Sigmoid module),分别用于小(小于32)中(32-96之间)大(大于96)物体预测,预测不同大小尺寸便于后面crop的时候控制尺寸(finer尺度预测小物体,coarser尺度预测大物体),训练时使用α= 2的focal loss,设置gt bbox的中点为positive,bbox其余为负样本,测试时大于阈值t=0.3的生成物体中心位置。
检测目标(Detecting Objects)
Crop区域的获取:
CornerNet-Saccade第二阶段:精细检测第一阶段在原图(高分辨率下)crop区域的目标。
- 从Attention maps获取到粗略中心位置:可以根据物体尺寸选择放大倍数(小物体放大更多,ss>sm>sl,ss=4,sm=2,sl=1),在每个可能位置(x,y),放大下采样图像si倍,i根据物体大小在(s,m,l)中选择,最后将此时的下采样图像映射回原图,以(x,y)为中心点取255×255大小为crop区域。
- 从coarse bounding box获取的位置:可以通过边界框尺寸决定放大尺寸,比如边界框的长边在放大后小物体应该达到24,中物体为64,大物体为192。
最终检测框生成
最终的检测框通过CornerNet-Saccade第二阶段的角点检测机制生成,与cornernet中完全一致,最后也是通过预测crop区域的corner heatmaps, embeddings and offsets,merge后坐标映射回原图。
冗余框消除
算法最后采用soft-nms消除冗余框,soft-nms无法消除crop区域中与边界接触的检测框,如下图figure3(这种检测框框出来的物体是不完整的,并与完整检测框iou较小,因此需要人工设置逻辑删除),可以在程序中直接删除与边界接触的框。

精度和效率权衡:
根据分数高低来排列第一阶段获取到的物体位置,取前Top K个区域送入第二阶段精检测网络,通过设置K的数量平衡精度和效率。
抑制冗余目标位置:
当物体接近时,如下图figure4中的红点和蓝点所代表的人,会生成两个crop区域(红框和蓝框),作者通过类nms处理此类情况,首先通过分数排序位置,然后取分数最大值crop区域,消除与该区域iou较大的区域。

骨干网络:
本文提出由3个hourglass module组成的Hourglass-54作为主干网络,相比cornernet的hourglass-104主干网络(2个hourglass module)更轻量。下采样步长为2,在每个下采样层跳连接,上采样层都有一个残差模块,每个hourglass module在下采样部分缩小三倍尺寸同时增加通道数(384,384,512),module中部的512通道也含有一个残差模块。
训练细节:
在4块1080ti上使用batch size为48进行训练,超参数与cornernet相同,loss function优化策略也是adam。
二、CornerNet-Squeeze
CornerNet-Squeeze:通过减少每个像素的处理过程来加速inference,结合SqueezeNet和MobileNet的思想。
PS:在CornerNet-Squeeze基础上结合Saccades并不会进一步提高其效率。
原因:有Saccade的存在,网络需要能够产生足够的attention map,而CornerNet-squeeze这种超轻量结构没有这种能力。
前言知识:SqueezeNet的三点设计理念:
- 将部分3x3卷积核替换为1x1卷积核;
- 削减3x3卷积的输入通道数;
- 延迟下采样。
SqueezeNet中使用的fire module囊括了前两点设计理念。
CornerNet-Squeeze主要操作是:
1)受SqueezeNet启发,CornerNet-Squeeze将residual block替换为SqueezeNet中的Fire module。
2)受MobileNet启发,CornerNet-Squeeze将第二层的3x3标准卷积替换为3x3深度可分离卷积(depth-wise separable convolution)。
下表是CornerNet-Squeeze中fire module和CornerNet中residual block的详细比较:

实验
测试硬件环境为:1080ti GPU + Intel Core i7-7700k CPU。

表table2对比CornerNet和CornerNet-Saccade训练效率,可以看出在gpu的内存使用上节省了将近60%。

表table3表明attention maps对于预测准确性的重要性,表3中将预测attention maps用真实的ground truth attention替代,AP值得到很大提升。作者表示,这也说明关于attention maps预测的方面还有改进提升的空间。

表table4为表明主干网络hourglass-54相比hourglass-104的性能提升,以及它对于attention maps预测的意义。

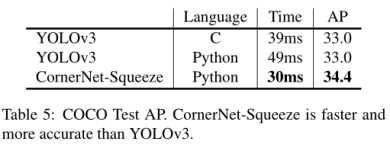
表table5是CornerNet-Squeeze与yolov3对比,可以看出无论是python还是效率更高的C版本yolo都弱于CornerNet-Squeeze
表table6为CornerNet-Squeeze的消融实验:

表table7中证明无法将本论文中的两种网络机制联合,原因是CornerNet-Squeeze没有足够的能力提供对CornerNet-Saccade贡献巨大的attention maps的预测。

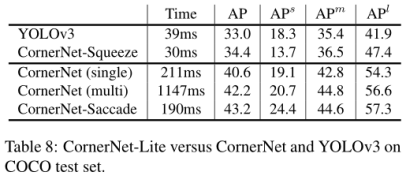
表table8表明本文中的两种网络架构,CornerNet-Squeeze在精度和速度方面对标YOLOv3完胜,CornerNet-Saccade主要在精度方面对标CornerNet完胜(速度意义不大)。