"Learning Efficient Object Detection Models with Knowledge Distillation"这篇文章通过知识蒸馏(Knowledge Distillation)与Hint指导学习(Hint Learning),提升了主干精简的多分类目标检测网络的推理精度(文章以Faster RCNN为例),例如Faster RCNN-Alexnet、Faster-RCNN-VGGM等,具体框架如下图所示:

教师网络的暗知识提取分为三点:中间层Feature Maps的Hint;RPN/RCN中分类层的暗知识;以及RPN/RCN中回归层的暗知识。具体如下:

具体指导学生网络学习时,RPN与RCN的分类损失由分类层softmax输出与hard target的交叉熵loss、以及分类层softmax输出与soft target的交叉熵loss构成:

由于检测器需要鉴别的不同类别之间存在样本不均衡(imbalance),因此在L_soft中需要对不同类别的交叉熵分配不同的权重,其中背景类的权重为1.5(较大的比例),其他分类的权重均为1.0:

RPN与RCN的回归损失由正常的smooth L1 loss、以及文章所定义的teacher bounded regression loss构成:

其中Ls_L1表示正常的smooth L1 loss,Lb表示文章定义的teacher bounded regression loss。当学生网络的位置回归与ground truth的L2距离超过教师网络的位置回归与ground truth的L2距离、且大于某一阈值时,Lb取学生网络的位置回归与ground truth之间的L2距离,否则Lb置0。
Hint learning需要计算教师网络与学生网络中间层输出的Feature Maps之间的L2 loss,并且在学生网络中需要添加可学习的适配层(adaptation layer),以确保guided layer输出的Feature Maps与教师网络输出的Hint维度一致:
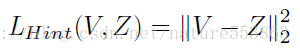
通过知识蒸馏、Hint指导学习,提升了精简网络的泛化性、并有助于加快收敛,最后取得了良好的实验结果,具体见文章实验部分。