论文:CornerNet: Detecting Objects as Paired Keypoints
Github:https://github.com/umich-vl/CornerNet
ECCV2018 Oral,作者美国密歇根大学heilaw ,论文提出了基于左上和右下2点的有别于传统检测的检测框架,该框架是一种自下而上的检测框架。是一种先有检测顶点,再有物体边框的思想。而传统的检测框架都是自上而下的思想。都是先有边框,再在框中回归关键点。中间还提出了corner pooling也是神来之笔,简单奏效,可以比传统的pooling获得更大的感受野。中间的Embedding借鉴的openpose。
基于Anchor检测的缺点:
- 需要大量的anchor来覆盖检测物体,其中DSSD需要40K的anchor,RetinaNet需要100K的anchor。这样大量的anchor中只有一小部分会与GT覆盖成为正样本,其余大部分未与GT覆盖的就会成为负样本,使得训练中正负样本失衡。并且产生大量的计算消耗。
- 需要对anchor设置大量的长宽比和尺度。增加了设计的复杂性。设置还需要引入一些先验知识。
因此引出本文的只需要回归2个坐标点的无anchor检测框架。
整体框架:

CornerNet 为one-stage检测框架。有别于传统的检测框架,像faster RCNN,yolo,ssd等。传统的检测框架是要根据anchor来回归物体的检测框,通过中心坐标和长宽(x,y,width,height)实现。CornerNet 只需要回归左上顶点和右下顶点就可以确定物体的检测框,直接去掉了anchor。
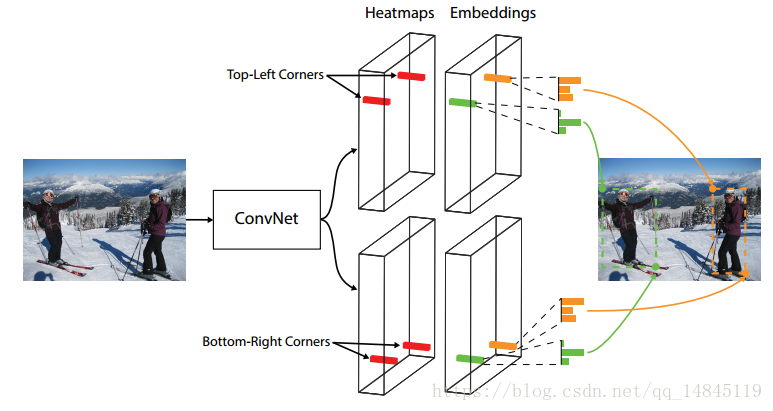
整体框架如上图,输入图像为511*511。输出特征为128*128。
CornerNet 的基础网络结构采用hourglass类型的网络模块,连续堆叠了2个这样的模块。hourglass结构可以很好的结合局部特征和全局特征。在hourglass模块中没有使用pooling操作,而是使用stride=2的卷积实现下采样,这也可以获得更快的速度。最终feature map被缩小5倍。其中卷积层的通道数分别为(256; 384; 384; 384; 512)。hourglass结构的网络深度为104层。
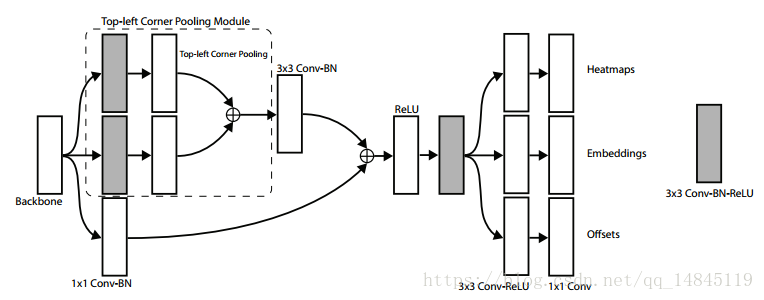
CornerNet 的检测模块如上图所示。上图只表示了top-left部分的结构,bottom-right也有类似的结构。经过backbone之后,首先经过corner pooling操作,输出pooling后的特征图,然后再和backbone的特征图做融合。相当于resnet中的shortcut结构在这里使用corner pooling替换。最终分为3个分支,分别输出heatmap,Embedding,offsets。
由于coco有80个类别,分类不带背景类别,所以网络最终输出的heatmap为128*128*80*2,分为top-left和bottom-right两个。
网络输出的嵌入向量Embedding为128*128*80*2,同样分为top-left和bottom-right两个。
网络偏移offsets为128*128*2,所有类别共用一个偏移量,分为x,y两个偏移值。
传统的检测框架的heatmap值作为了边框的分数,边框的位置是通过(x,y,width,height)确定的。而CornerNet 的heatmap既做了边框的分数,还做了边框的位置。由于网络不断下采样会造成最终的坐标和原始图像的有偏移,这里采用了回归的offsets解决。至于左上角的点和右下角的点的配对,使用Embedding来解决。
在网络模块输出完毕后,首先在top-left和bottom-right的heatmap中分别取100个分数最高的框。也就是100个左上角顶点,100个右下角顶点。两两组合一共可以产生10000个坐标框。然后两两配对的顶点中,如果类别不是同一类就会被剔除。如果bottom-right点的坐标高于top-left点的坐标,也就是说右下角的顶点在左上角的顶点的左上方时也会被剔除。再在剩下的配对坐标中计算两两相似度。相似度高于0.5的,也就是说不是一组组合,也会被剔除。最终将留下的配对点做NMS操作。输出最终的结果框。
Loss函数:
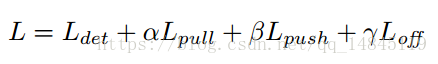
CornerNet的整体loss函数如上公式。包含检测的损失Ldet,Embedding的损失Lpull+Lpush,offsets的损失Loff。
检测的损失Ldet:

该损失为基于focal loss修改的分段损失函数。
C:通道数
H:高度
W:宽度
N:物体的个数
α,β :超参数,α=2,β=4
Pcij:通道c在(i,j)位置的预测的分数
Ycij:通道c在(i,j)位置的真实label,该label经过非归一化的高斯函数处理过。
其中2D高斯核函数为

中心为label位置的中心,方差σ 1/3物体的半径。
Embedding的损失Lpull+Lpush:

Embedding的损失包含将相同类别拉近的pull损失和将不同类别拉远的push损失。主要实现将相同类别的分数都学习到接近平均分数,将不同类别的分数之间的距离都学到>=1。
N:物体的个数
etk:top-left的物体k的分数
ebk:bottom-right的物体k的分数
ek:etk和ebk的平均
∆ :margin,这里取1
offsets的损失Loff:

Loff采用的损失为smooth L1损失,
ok :为偏移量,由(x,y)两项组成
Corner Pooling :
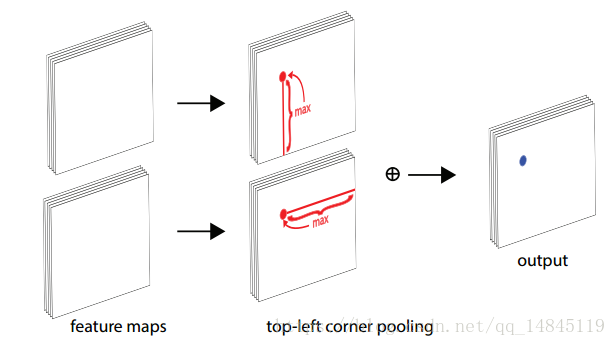
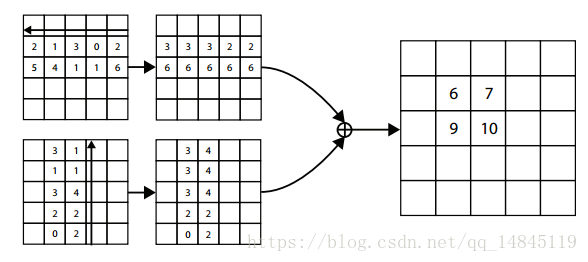
Corner pooling先做水平方向从右向左的max pooling,再做从下到上的max pooling。最终会得到1个水平方向pooling后的特征图和垂直方向pooling后的特征图。然后再将这2个特征图element-wise相加,得到最终的pooling 结果。

总结:
(1)CornerNet 第一次提出了一种自下而上的检测框架,并且在coco数据集上取得了one-stage最高的精度
(2)Corner pooling思想非常好,可以获得比传统pooling更好的感受野。