机器学习笔记之支持向量机
解决什么问题
支持向量机解决的是二分类及多分类问题,由于在学之前学习了logistic回归,其实可以看到两者有着非常相似的地方
原理与思考
原理方面这一个帖子说的很详细了,不再赘述
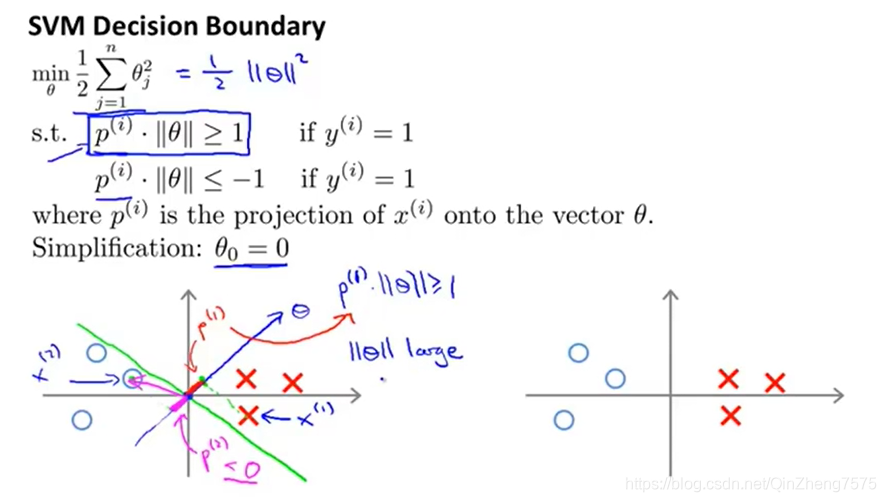
从图中可以看到,支持向量机的点乘操作,实际上就是让那个超平面与两个类的距离最大,因为你点乘下来是投影的和,而之后又带入代价函数。其实它的代价函数和logistic的代价函数非常像,为了让代价函数最小,我们选择的超平面也自然成为了那个最大间隔的分开向量。
但是在同时,我们有一个类似于正则化系数的C,这个C就是起到一个调节的作用
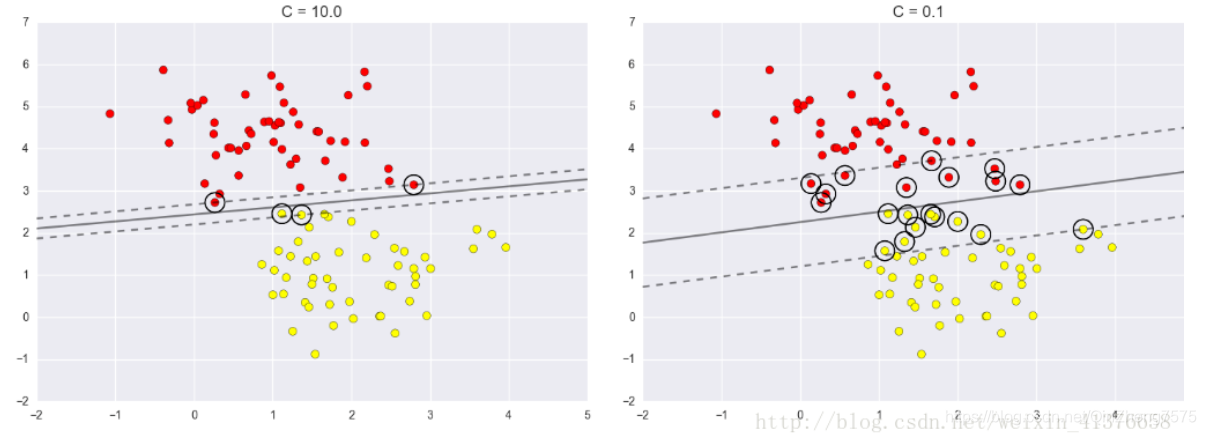
但是在这里,需要介绍一下对核函数的理解
如果我们不用核函数,也就相当于核函数默认为线性的,那么我们就相当于直接使用这个点乘来作为带入代价函数的输入。核函数的原理就是一个,当前点距离标志的相似程度,一般用距离为自变量,比如高斯核函数
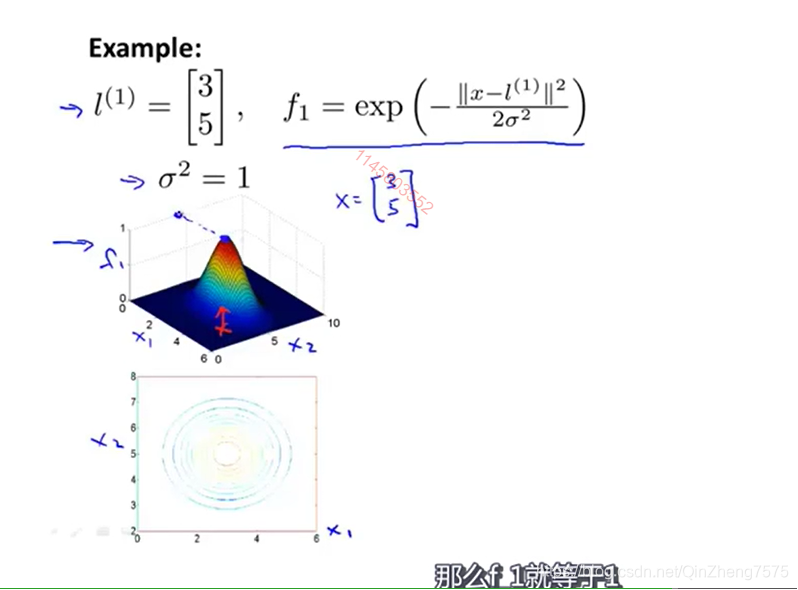
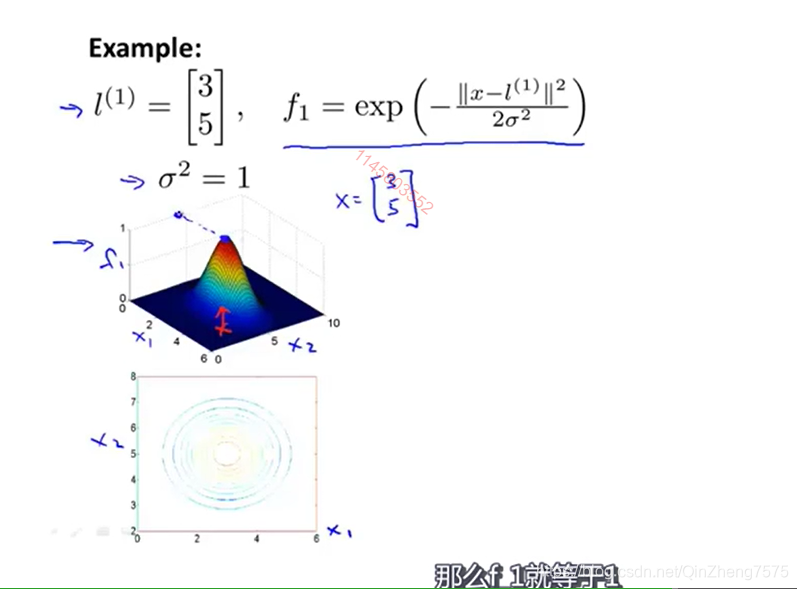
我们的核l,向量为[3,5],那么在评价一个输入的向量时,我们带入函数f1,再将结果带入代价函数。
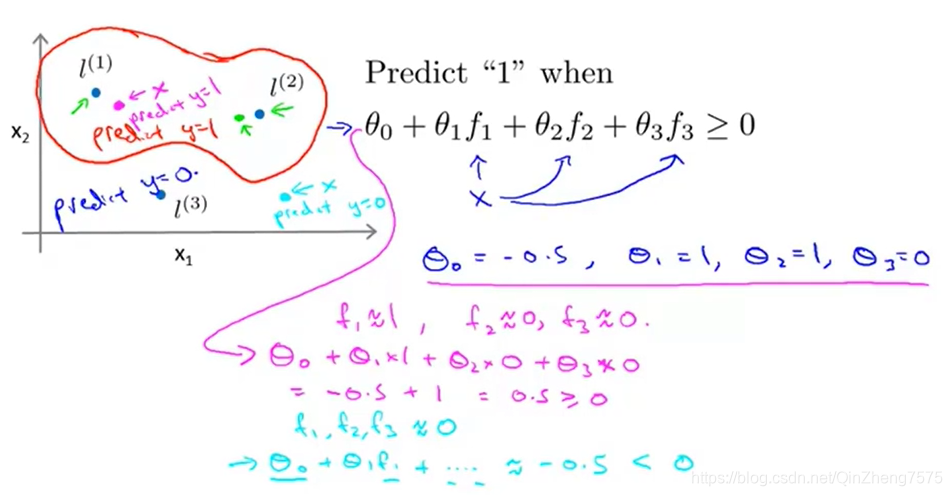
比如在这里,通过计算,落在红线以内的点,因为距离核l1 l2更近,我们将它们归为一类。别忘了核函数的意义:x与核的相似程度
核函数的选择,参考:


例子与总结
import numpy as np
import pylab as pl
from sklearn import svm
from sklearn import datasets
# we create 40 separable points
np.random.seed(0)#保证每次运行时抓的值不变
X, Y = datasets.make_blobs(n_samples=100,centers=2)
print(X, Y)
clf = svm.SVC(kernel='linear')
clf.fit(X, Y)
w = clf.coef_[0]
a= -w[0] / w[1]#斜率
xx=np.linspace(-4, 5)#-4到5产生值
yy=a * xx - (clf.intercept_[0] / w[1])
#b=clf.support_vectors_[0]
#yy_down=a * xx + (b[1] - a * b[0])
#b=clf.support_vectors_[-1]
#yy_up=a * xx + (b[1] - a * b[0])
print( "w: ")
print(w)
print ("a: ")
print(a)
# print "xx: ", xx
# print "yy: ", yy
#print ("support_vectors_: ")
#print("clf.support_vectors_")
print ("clf.coef_: ")
print(clf.coef_)
# switching to the generic n-dimensional parameterization of the hyperplan to the 2D-specific equation
# of a line y=a.x +b: the generic w_0x + w_1y +w_3=0 can be rewritten y = -(w_0/w_1) x + (w_3/w_1)
# plot the line, the points, and the nearest vectors to the plane
pl.plot(xx, yy, 'k-')
#pl.plot(xx, yy_down, 'k--')
#pl.plot(xx, yy_up, 'k--')
#pl.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
# s=80, facecolors='none')
pl.scatter(X[:, 0], X[:, 1], c=Y, cmap=pl.cm.Paired)
pl.axis('tight')
pl.show()
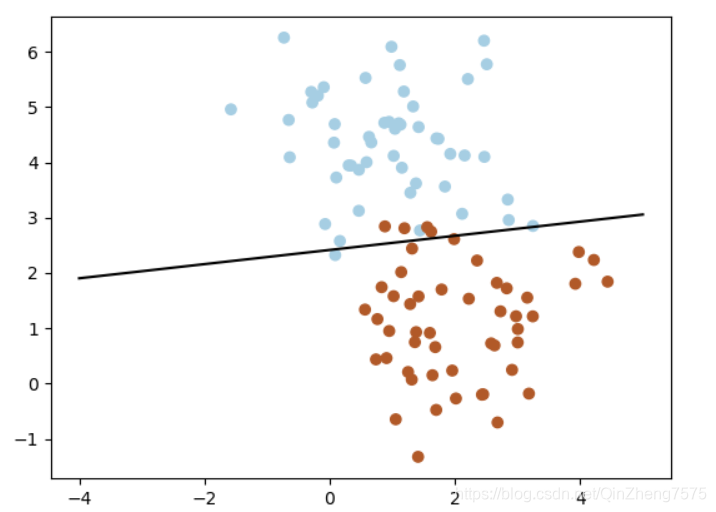
代码就是使用sklearn里的SVM包,不妨来看看这些:
各个参数详细
一个例子
最后,感谢这个:从0开始详细讲解操作