— 抓住主线,全神贯注,决胜于速
1.SVM意义
支持向量机是一种二分类模型,基本模型是定义在特征空间的间隔最大的线性分类器。
- 间隔最大使它不同于感知机,感知机利用误分类最小的策略,得到分离超平面有无数个,而SVM加上间隔最大后,只有一个;
- 包括核技巧将其扩展为非线性分类器;
- 学习策略是间隔最大化,其可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。
- 支持向量机的学习算法就是求解凸二次规划的最优算法。
模型包含:线性可分支持向量机(硬间隔支持向量机),软间隔支持向量机,非线性支持向量机。
2.SVM模型
2.1 线性可分支持向量机
从二分类问题开始,给定一个特征空间上的训练数据集
T={(x1,y1),…,(xN,yN)} ,其中
,xi∈RN,yi∈{+1,−1},对于
y 取值的限制是一个 trick,用函数间隔正负来判别分类正确性。一个重要的假设是,数据集线性可分。
学习的目标是找到的特征空间的分离超平面,用
w⋅x+b=0 表示,参数是法向量
w和截距
b,空间被划分为两个部分,正类和负类,法向量指向的一侧是正类。
使用公式
d=∣w∣w⋅x+b
求解点到面的距离是,法向量和
x 内积运算有个夹角,这个夹角决定了距离的正负,而我们定义距离为正的是正样本,因而,可以说法向量指向的一侧是正类。
这里的
w⋅x代表的是点积运算,就是
wTx。
样本点到分离超平面的间隔分为函数间隔和几何间隔,SVM分类时,
w⋅x+b 为正时,代表是正类,为负时,代表是负类。乘以标签值
y 之后,
y(w⋅x+b) 用来表示分类的正确与否,为正则代表分类正确,为负代表分类错误。
∣w⋅x+b∣ 的值大小代表分类的置信度。
函数间隔:
γ~=yi(w⋅x+b),进一步,定义超平面关于训练集T的函数间隔为所有点函数间隔的最小值,即
γ~=minγ~i。
几何间隔:很明显,当成比例的改变w和b时,函数间隔可以任意大小,所以定义几何间隔,表示空间中点到超平面的真实距离。即
γ~=∣w∣yi(w⋅x+b),SVM学习的目标就是正确划分训练数据集并且几何间隔最大化的。
考虑如何求一个几何间隔最大的分离超平面,问题可以表述为约束最优化问题:
w,bmaxγs.t.yi(∣∣w∣∣w⋅xi+∣∣w∣∣b)≥γ, i=1,…N.
可以改写为
w,bmax∣∣w∣∣γ~s.t.yi(w⋅xi+b)≥γ~, i=1,…N.
函数间隔
γ~ 并不会影响问题的解,我们可以将
w,b 重写为变量
w/γ~,b/γ~,可以看出问题没有发生变化,而函数间隔变量没有了。因此,我们不妨直接令
γ~=1。
这时,几何间隔变为
∣∣w∣∣1,结合之前所述,函数间隔为1的点称为支持向量,而这些点的几何间隔则和
w 有关系,需要具体的求解。
这时优化问题转化为
KaTeX parse error: Expected 'EOF', got '\label' at position 99: …\ i=1,\ldots N.\̲l̲a̲b̲e̲l̲{raw}
这是一个典型的凸二次规划问题。
可以求得最优解为
w∗,b∗,得到分离超平面:
w∗⋅x+b∗=0,分类决策函数为
f(x)=sign(w∗⋅x+b∗)。
支持向量就是指的那些使约束条件成立的点,函数间隔为1.
我们使用对偶算法来对上述凸二次规划问题求解,首先写出拉格朗日函数,引入拉格朗日乘子
αi≥0,i=1,…,N
L(w,b,α)=21∣∣w∣∣2−i=1∑Nαiyi(w⋅xi+b)+i=1∑Nαi
-
求解
w,bminL(w,b,α),使用偏导数为0
∇wL(w,b,α)=w−i=1∑Nαiyixi=0∇bL(w,b,α)=i=1∑Nαiyi=0
得到
w=i=1∑Nαiyixii=1∑Nαiyi=0
代入可得
L(w,b,α)=21i=1∑Nj=1∑Nαiαjyiyjxi⋅xj−i=1∑Nαiyi((j=1∑Nαjyjxj)⋅xi+b)+i=1∑Nαi=−21i=1∑Nj=1∑Nαiαjyiyjxi⋅xj+i=1∑Nαi
求解时候注意,
αi和
y是值,只有
xi是向量,值是可以随意调换位置的,另外,求和符号相乘的处理规则要记住,很简单。
2.对偶问题为
αmin21i=1∑Nj=1∑Nαiαjyiyjxi⋅xj−i=1∑Nαis.t.i=1∑Nαiyi=0αi≥0
解出
αi∗ 之后,求出w和b即可得到模型,其中可以得到至少有一个
αj>0,
w∗=i=1∑Nαi∗yixib∗=yj−i=1∑Nαi∗yixi⋅xjf(x)=w∗⋅x+b∗
可以看出,分类决策函数只依赖与输入
x和训练样本的内积。
从对偶问题解出的
αi 对应着每一个训练样本,注意到式 KaTeX parse error: Expected 'EOF', got '\ref' at position 1: \̲r̲e̲f̲{raw} 中有不等式约束,因此上述过程要满足KKT条件 ,即要求:
⎩⎪⎨⎪⎧αi≥0;yif(xi)−1≥0;αi(yif(xi)−1)=0.
可以看出,对任意的训练样本
(xi,yi),总有
αi=0或
yif(xi)−1=0 ,若前者,则该样本不会出现在
w∗的解中,若是后者,则必有
,α>0,yif(xi)=1,所对应的样本点位于最大间隔边界上,是一个支持向量。这显示处支持向量一个重要的性质:训练完成后,大部分的训练样本都不会出现在判别函数中,最终模型只与支持向量有关。
2.2 软间隔最大化
当训练数据线性不可分时,不是所有的数据都能够划分正确,我们修改硬间隔最大化,使其成为软间隔最大化。通常情况下,训练数据线性不可分,我们把那些不可分的特异点去掉,剩下的样本点组成的集合是线性可分的。
线性不可分这里意味着,某些样本点不能满足函数间隔大于等于 1的约束条件,为了解决这个问题,对每个样本点引入一个松弛变量
ξi≥0。 使函数间隔加上松弛变量后大于等于1,这样约束条件变为
yi(w⋅xi+b)≥1−ξi
相应的,每个松弛变量要在目标函数中加上“代价”,目标函数变为
21∣∣w∣∣2+Ci=1∑Nξi
这里的C称为惩罚参数,最小目标函数包含两层含义:使几何间隔尽可能小,同时使误分类点的个数尽可能小,C是调和二者的系数。
软间隔支持向量机的学习问题变为
w,b,ξmin21∣∣w∣∣2+Ci=1∑Nξis.t.yi(w⋅xi+b)≥1−ξi, i=1,…Nξi≥0, i=1,…N.
该问题仍是一个凸二次规划问题,因为
(w,b,ξ)的解是存在的,可以证明
w的解是唯一的,但是
b的解不唯一,存在于一个区间内。
原始问题的对偶问题为
αmin21i=1∑Nj=1∑Nαiαjyiyjxi⋅xj−i=1∑Nαis.t.i=1∑Nαiyi=00≤αi≤C
求解对偶问题时,由于原问题由两项约束条件,因此有两组拉格朗日乘子(两组,不是两个),分别是
,αi, μi,i=1,…N,求解过程中得到约束条件
C=αi+μi,μi≥0,这里把
μi消去了,变为
αi≤C。
前面说了,支持向量到超平面的函数距离为1,几何距离为
∣∣w∣∣1,软间隔加入松弛变量后,由于
yi(w⋅xi+b)+ξi=1,可以看出样本点到支持向量的边界的几何距离就是
∣∣w∣∣ξi。
类似的,上述过程要求满足KKT条件
⎩⎪⎪⎪⎨⎪⎪⎪⎧αi≥0,μi≥0;yif(xi)+ξi−1≥0;αi(yif(xi)+ξi−1)=0.ξi≥0,μiξi=0
可以看出,对任意的训练样本
(xi,yi),总有
αi=0或
yif(xi)=1−ξi。若前者,则该样本不会出现在
w∗的解中,若是后者,则必有
,αi>0,yif(xi)=1−ξi,是一个支持向量(不一定在最大间隔上) 。若
αi<C,由于
C=αi+μi,则
μi>0,进而
ξi=0,该样本落在最大间隔边界上。否则,当
αi=C,有
μi=0,此时若
ξi≤1,则该样本落在分离超平面和最大间隔之间,若
ξi>1,则
yif(xi)=1−ξi<0,该样本点被分类错误。
2.3 合页损失函数
线性支持向量机学习,其模型为分离超平面和决策函数,学习策略是软间隔最大化,学习算法是凸二次规划。其还有另外一种解释,就是最小化目标函数
i=1∑N[1−yi(w⋅xi+b)]++λ∣∣w∣∣2
合页损失函数为:
[z]+={z,0,z>0z≤0
目标第一项表示,当样本点的函数间隔大于1时,损失为0,这是符合前面的思想的,否则损失就是
1−yi(w⋅xi+b)。目标函数第二项是正则化项。
可以证明,软间隔线性支持向量机学习问题:
w,b,ξmin21∣∣w∣∣2+Ci=1∑Nξis.t.yi(w⋅xi+b)≥1−ξi, i=1,…Nξi≥0, i=1,…N.
等价于最优化问题:
w,bmini=1∑N[1−yi(w⋅xi+b)]++λ∣∣w∣∣2
软间隔支持向量机原本的思想是,不满足最小间隔约束的点尽可能少,目标函数应该是
w,b,ξmin21∣∣w∣∣2+Ci=1∑Nl0/1(yi(w⋅xi+b)−1)
其中,
l0/1是0/1损失函数,
l0/1(z)={1,0,z>0z≤0
但是,该损失函数非凸函数,不连续,不易求解,所以,通常用一些函数替代,比如
- 合页损失:
lhinge(z)=max(0,1−z)
- 指数损失:
lexp(z)=exp(−z)
- 对率损失:
llog=log(1+exp(−z))

2.4 支持向量回归(SVR)
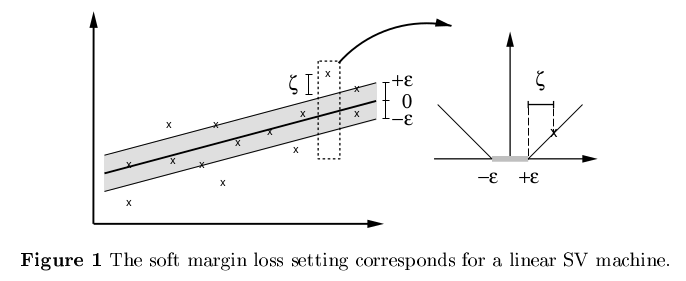
传统的回归模型基于模型输出和真实输出之间的差别来计算损失,当且仅当
f(x)=y时,损失才为0,支持向量回归模型中,假设我们能够容忍的偏差为
ϵ,即当
∣f(x)−y∣>ϵ时才计算损失,这相当于以
f(x)为中心,构建了一个宽度为
2ϵ的间隔带,若训练样本落入此间隔带内,则被认为是预测正确的,不包含在损失计算中。
支持向量回归的目标函数为
αmin21∣∣w∣∣2+Ci=1∑Nlϵ(w⋅xi+b−yi)
其中,C为正则化常数,
lϵ是形如上面右图的损失函数
lϵ(z)={0,∣z∣−ϵ,if∣z∣≤ϵotherwise.
这里没有什么函数间隔与几何间隔,只有预测偏差
f(x)−z。
引入松弛变量
ξi,ξi~,将优化问题重写为
w,b,ξ,ξi~min21∣∣w∣∣2+Ci=1∑N(ξ+ξi~)s.t.w⋅xi+b−yi≤ϵ+ξiyi−(w⋅xi+b)≤ϵ+ξi~ξi≥0, ξi~≥0, i=1,…N
求解对偶问题,首先引入拉格朗日乘子
μi≥0,μi~≥0,αi≥0,α~i≥0,令拉格朗日函数对于变量的偏导数为零可以求得
w=i=1∑N(αi~−αi)xii=1∑N(αi~−αi)=0αi+μi=Cαi~+μi~=C
代入之后可以求得对偶问题为
α,αi~max−21i=1∑Nj=1∑N(αi~−αi)(αj~−αj)αjxi⋅xj+i=1∑Nyi(αi~−αi)−ϵ(αi~−αi)s.t.i=1∑N(αi~−αi)=00≤α,αi~≤C
上述求解要满足KKT条件要求,
⎩⎪⎪⎪⎨⎪⎪⎪⎧αi(f(xi)−yi−ϵ−ξi)=0α~i(yi−f(xi)−ϵ−ξi~)=0αi~αi=0, ξi~ξi=0(C−αi)ξi=0, (C−αi~)ξi~=0
由原问题约束条件可以看出,当
f(xi)−yi−ϵ−ξi=0时,由于
ξi≥0,此时必定有
f(xi)−yi−ϵ≥0,表明此时样本点一定落在了误差容许间隔外,而KKT第一个约束表明$f(x_i)-y_i-\epsilon-\xi_i=0
或\alpha_i
必有一个成立,因而得出,只有当样本点在误差容许间隔外,即f(x_i)-y_i-\epsilon-\xi_i=0
时,才可能有\alpha_i
取非零值。又因为f(x_i)-y_i-\epsilon-\xi_i=0
和y_i-f(x_i)-\epsilon-\tilde{\xi_i}=0
不可能同时成立(正负问题),所以\alpha_i
和\tilde{\alpha_i}$必有一个为0。
若是落在误差间隔内,由于
∣f(xi)−yi∣<ϵ,且
ξi≥0,因为必有
f(xi)−yi−ϵ−ξi<0,所以必有
αi,αi~=0。
SVR模型的解为
f(x)=i=1∑N(αi~−αi)xi⋅x+b
显然,能使
(αi~−αi)=0的样本点必定落在误差间隔线上或者误差间隔外。
另外,SVR也可以使用核技巧。
3. 非线性SVM与核函数
3.1核技巧
非线性问题是指通过非线性模型才能很好地进行分类的问题,如下图所示,无法用直线(超平面)将正负实例分开,但是可以用一条椭圆曲线(超曲面)分来。

这个问题的解决方法是进行一个非线性变换,将非线性问题转换为线性问题,通过变换后的线性问题的方法来求解原来的非线性问题。上面的问题,原空间和新空间都是
R2,但是经过了非线性映射的处理。更一般的,往往将低维空间的特征映射到高维空间,从而使低维的线性不可分问题转换为高维线性可分问题。
设原空间为
,X∈R2,x=(x1,x2)T∈X,新空间为
Z∈R2,z=(z1,z2)∈Z,非线性映射为
z=ϕ(x)=(x12,x22)T
经过映射,原空间X变为新空间Z,原空间中的点相应变换为新空间中的点,原空间的椭圆变为新空间的直线
w1x12+w2x22+b=0→w1z1+w2z2+b=0
核技巧本质即,通过一个非线性变换将输入空间对应于一个特征空间,使得在输入空间中的超曲面模型对应于特征空间中的超平面模型。
如何理解映射和空间:在非线性映射中用基的角度讨论空间变换没有任何意义,因为任何空间中的向量用基向量进行表示,是线性表示,非线性映射不满足
f(ax+by)=af(x)+bf(y)。这里,非线性映射前后的空间采用的都是自然坐标系,真正重要的是找到映射关系(函数)。
核函数:设X是输入空间(欧式空间
Rn子集或者离散集合),又设H为特征空间(希尔伯特空间),如果存在一个从X到H的映射:
ϕ(x):X→H
使得对于所有的
x,z∈X,函数
K(x,z)满足
K(x,z)=ϕ(x)⋅ϕ(z)
则称K为核函数,
ϕ为映射函数,其中
ϕ(x)⋅ϕ(z)为内积运算。
核技巧的根本目的在于,在学习和预测中只定义核函数,而不显示地定义映射函数。因为,通常直接计算
K(x,z)比较简单,而通过映射
ϕ(x)⋅ϕ(z)计算则比较困难。这里的特征空间一般是高维的,甚至是无穷维的。而且,对于给定的核函数
K(x,z),特征空间和映射函数的取法并不唯一,可以去不同的特征空间,即便是在同一特征空间,也可以取不同的映射。
一个理解核函数由特征空间和映射函数决定的非常好地例子:

3.2 核技巧在SVM的应用
线性支持向量机的对偶问题中,目标函数和决策函数都只涉及输入实例与实例之间的内积。自然想到,我们将样本点经过非线性映射投射到高维空间后,使用线性支持向量机求解后,使用核技巧
K(xi,xj)=ϕ(xi)⋅ϕ(xj)。可以看出,确定新特征空间、非线性映射这两步可以直接省略,给定核函数即可,至于什么样的特征空间与非线性映射能够得出我们设定的核函数,不需要关心。
此时给定核函数,目标函数转换为
W(α)=21i=1∑Nj=1∑NαiαjyiyjK(xi⋅xj)−i=1∑Nαi
分类函数用核函数替换为
f(x)=sign(j=1∑Nαi∗yiϕ(xi)⋅ϕ(x)+b∗)=sign(i=1∑Nαi∗yiK(xi,x)+b∗)
这等价于经过映射函数将原来的输入空间变换到一个新的特征空间,将输入空间的内积变换为特征空间中的内积
ϕ(xi)⋅ϕ(xj),在新的特征空间中从训练样本中学习非线性支持向量机。
通常所说的和核函数是正定核函数,一个函数是正定核函数的充要条件如下

3.3 常用的核函数
- 多项式核函数:
K(xi,xj)=(xi⋅xj)d
- 高斯核函数:
K(xi,xj)=exp(−2σ2∣∣xi−xj∣∣2)
- 拉普拉斯核函数:
K(xi,xj)=exp(−σ∣∣xi−xj∣∣2)
- Sigmoid核函数:
K(xi,xj)=tanh(βxi⋅xj+θ)
几个性质:
- 若
K1和
K2是核函数,则对于任意的正数
γ1,γ2,其线性组合也是核函数;
- 若
K1和
K2是核函数,则核函数的直积
K1(x,z)K2(x,z)也是核函数;
- 若
K1是核函数,则对于任意的函数
g(x),
K(x,z)=g(x)K1(x,z)g(z)也是核函数。
3.4 算法总结

3.4 核方法
前面提到,SVM和SVR模型都可以表示成核函数的线性组合,更一般的结论成为“表示定理”
表示定理:令H为核函数K对应的再生核希尔伯特空间,
∣∣h∣∣H表示H空间中关于h的范数,对于任意单调递增函数
Ω:[0,∞]→R和任意非负损失函数
l:Rm→[0,∞],优化问题
h∈HminF(h)=Ω(∣∣h∣∣H)+l(h(x1),h(x2),…,h(xN))
解总是可以写为
h∗(x)=i=1∑NαK(x,xi)
注意,表示定理对损失函数没有限制,不连续、不凸都行,对正则化项仅要求单调递增,甚至不要求是凸函数,这表明对于一般的损失函数和正则化项,优化问题的解都可以表示为核函数的线性组合。