说实话,这一章算是这本书最难理解的部分了,所以挣扎了好几天这才决定想起来写写(其实这几天都看小说去了,哈哈哈哈) 书上给的案例很详细了,所以这篇文章我打算讲讲其他的部分,让大家觉得不那么枯燥。
支持向量机与Logistic回归的区别
当时看完Logistic回归这一部分后,觉得这方法还不错,很多方面都合情合理。但是看到支持向量机这部分后就发觉这两种方法没什么差别吧(不知道刚了解这两种方法的朋友们有没有这样的感觉),都是用一条直线来分割整个平面,只不过一个叫回归直线,另一个叫超平面。但仔细比较后才发现有些不同:
相同点
1、LR和SVM都是分类算法(曾经我认为这个点简直就是废话,了解机器学习的人都知道。然而,虽然是废话,也要说出来,毕竟确实是一个相同点。)
2、如果不考虑使用核函数,LR和SVM都是线性分类模型,也就是说它们的分类决策面是线性的。
其实LR也能使用核函数,但我们通常不会在LR中使用核函数,只会在SVM中使用。原因下面会提及。
3、LR和SVM都是监督学习方法。
监督学习方法、半监督学习方法和无监督学习方法的概念这里不再赘述。
4、LR和SVM都是判别模型。
判别模型和生成模型的概念这里也不再赘述。典型的判别模型包括K近邻法、感知机、决策树、Logistic回归、最大熵、SVM、boosting、条件随机场等。典型的生成模型包括朴素贝叶斯法、隐马尔可夫模型、高斯混合模型。
5、LR和SVM在学术界和工业界都广为人知并且应用广泛。(感觉这个点也比较像废话)
不同点
1、loss function不一样
LR的loss function是

SVM的loss function是
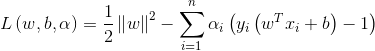
LR基于概率理论,通过极大似然估计方法估计出参数的值,然后计算分类概率,取概率较大的作为分类结果。SVM基于几何间隔最大化,把最大几何间隔面作为最优分类面。
2、SVM只考虑分类面附近的局部的点,即支持向量,LR则考虑所有的点,与分类面距离较远的点对结果也起作用,虽然作用较小。
SVM中的分类面是由支持向量控制的,非支持向量对结果不会产生任何影响。LR中的分类面则是由全部样本共同决定。线性SVM不直接依赖于数据分布,分类平面不受一类点影响;LR则受所有数据点的影响,如果数据不同类别strongly unbalance,一般需要先对数据做balancing。
3、在解决非线性分类问题时,SVM采用核函数,而LR通常不采用核函数。
分类模型的结果就是计算决策面,模型训练的过程就是决策面的计算过程。在计算决策面时,SVM算法中只有支持向量参与了核计算,即kernel machine的解的系数是稀疏的。在LR算法里,如果采用核函数,则每一个样本点都会参与核计算,这会带来很高的计算复杂度,所以,在具体应用中,LR很少采用核函数。
4、SVM不具有伸缩不变性,LR则具有伸缩不变性。
SVM模型在各个维度进行不均匀伸缩后,最优解与原来不等价,对于这样的模型,除非本来各维数据的分布范围就比较接近,否则必须进行标准化,以免模型参数被分布范围较大或较小的数据影响。LR模型在各个维度进行不均匀伸缩后,最优解与原来等价,对于这样的模型,是否标准化理论上不会改变最优解。但是,由于实际求解往往使用迭代算法,如果目标函数的形状太“扁”,迭代算法可能收敛得很慢甚至不收敛。所以对于具有伸缩不变性的模型,最好也进行数据标准化。
5、SVM损失函数自带正则项,因此,SVM是结构风险最小化算法。而LR需要额外在损失函数上加正则项。
我总结起来就是一句话:支持向量机方法最为强大,因为SVM可以采用核函数,使得其可以解决非线性分类问题
SMO算法
关于SVM算法公式的相关推导我这儿就不写了,网上的文章比比皆是了。我就只想提提关于书中提到的SMO算法的相关推导,因为书中没有具体给出,所以我会详细指出。
fXi = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b这一步就是这个意思

eta = 2.0 * dataMatrix[i, :] * dataMatrix[j, :].T - dataMatrix[i, :] * dataMatrix[i, :].T - \
dataMatrix[j, :] * dataMatrix[j, :].T这一步就是这个意思

alphas[j] = clipAlpha(alphas[j], H, L)
alphas[i] += labelMat[j] * labelMat[i] * (alphaJold - alphas[j])这一步的意思

b1 = b - Ei - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T - labelMat[j] * \
(alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T
b2 = b - Ej - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T - labelMat[j] * \
(alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T这一步的意思是

上面的核心步骤写完了下面就直接把源码贴出来
import random
import smoCom
from os import listdir
from numpy import mat, shape, zeros, multiply, nonzero, sign
# 加载本地数据
def loadDataSet(fileName):
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
# 加载本地图片数据
def loadImages(dirName):
hwLabels = []
trainingFileList = listdir(dirName)
m = len(trainingFileList)
trainingMat = zeros((m, 1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
if classNumStr == 9:
hwLabels.append(-1)
else:
hwLabels.append(1)
trainingMat[i, :] = img2vector('%s/%s' % (dirName, fileNameStr))
return trainingMat, hwLabels
# 随机选择不同数
def selectJrand(i, m):
j = i
while j == i:
j = int(random.uniform(0, m))
return j
# 用于调整大于H或小于L的alpha值
def clipAlpha(aj, H, L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
# 将图像转换为向量
def img2vector(filename):
returnVect = zeros((1, 1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j])
return returnVect
# 简化版SMO算法
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn)
labelMat = mat(classLabels).transpose()
b = 0
m, n = shape(dataMatrix)
alphas = mat(zeros((m, 1)))
iter = 0
while iter < maxIter:
alphsPairsChanged = 0
for i in range(m):
fXi = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[i, :].T)) + b
Ei = fXi - float(labelMat[i])
if ((labelMat[i] * Ei < -toler) and (alphas[i] < C)) or ((labelMat[i] * Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i, m)
fXj = float(multiply(alphas, labelMat).T * (dataMatrix * dataMatrix[j, :].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
if labelMat[i] != labelMat[j]:
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L == H:
print('L == H')
continue
eta = 2.0 * dataMatrix[i, :] * dataMatrix[j, :].T - dataMatrix[i, :] * dataMatrix[i, :].T - \
dataMatrix[j, :] * dataMatrix[j, :].T
if eta >= 0:
print("eta == 0")
continue
alphas[j] -= labelMat[j] * (Ei - Ej) / eta
alphas[j] = clipAlpha(alphas[j], H, L)
if abs(alphas[j] - alphaJold) < 0.00001:
print("j not moving enough")
continue
alphas[i] += labelMat[j] * labelMat[i] * (alphaJold - alphas[j])
b1 = b - Ei - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T - labelMat[j] * \
(alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T
b2 = b - Ej - labelMat[i] * (alphas[i] - alphaIold) * dataMatrix[i, :] * dataMatrix[i, :].T - labelMat[j] * \
(alphas[j] - alphaJold) * dataMatrix[j, :] * dataMatrix[j, :].T
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2)/2.0
alphsPairsChanged += 1
print("iter: %d i: %d, paris changed %d" % (iter, i, alphsPairsChanged))
if alphsPairsChanged == 0:
iter += 1
else:
iter = 0
print("iteration number: %d" % iter)
return b, alphas关于这一章节我暂时就只想写到这儿了,说实话我到现在还不能完全理解,所以我只敢写到这儿了,等过段时间我再回头来看看看能不能有些新收获