前言
上一期介绍了神经语言模型基础以及词向量表示。在开始介绍其他语言模型前,有必要了解一下它们的基础结构:RNN以及LSTM。
RNN(Recurrent Neural Networks)
网络结构
最简单的循环神经网络就是一个单层隐含层结构的网络;隐含层激活函数为tanh,输出层激活函数为softmax函数。因此和NNLM一样,RNN的输出为预测的概率,范围在0~1之间。
运作方式
RNN每一次运算都会将隐含层的输出储存起来(记为a),并在下一次运算时也作为输入的一部分(与x进行加权)参与计算。在第一个x输入时会首先为a设置一个初始值a0。
通过不断对这个简单的神经网络输入进行训练,每一次的训练又和上一次的运算有关,循环这个过程,因此被称作循环神经网络。
RNN采用基于时间的BPTT算法,该算法与BP算法并无差异,只是在导数中加入了运行的次数考虑。
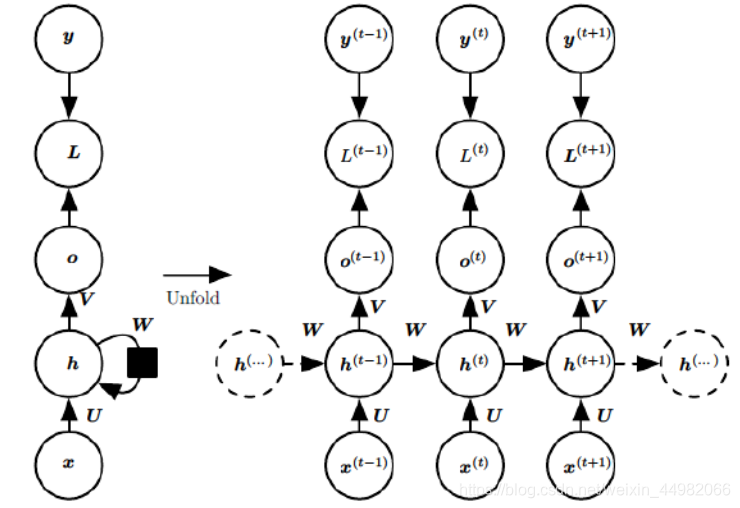
这里需要注意的是,RNN在每一次运算中会将上一次存储在隐含层中的结果清除掉,存进新的结果。在训练时,RNN本身只是一个简单的单输入网络,只是在不同的时间点下不同的输入进入同一个RNN而已。
由于RNN的上一次输入会影响下一次输出,因此RNN能够更好的参照之前的输入进行学习,这就很适合实现像NLP中需要关联上下文进行学习理解的想法了。
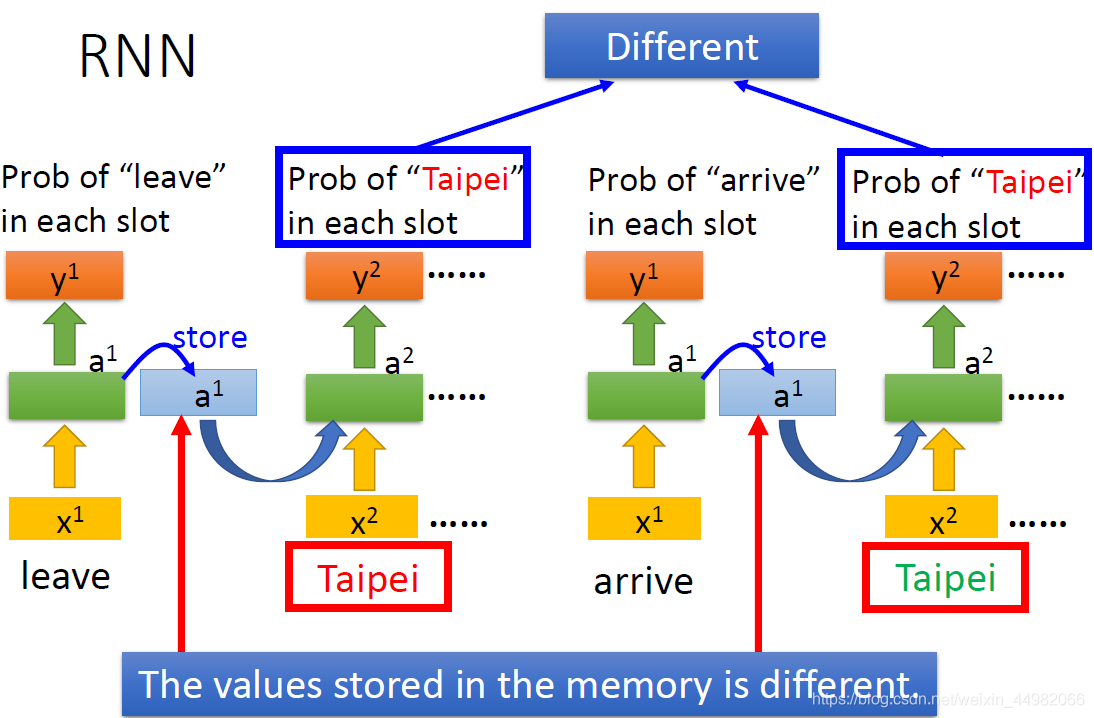
上图是一个举例,通过RNN,虽然输入相同的词(Taipei),但是机器可以知道他们代表的含义是不一样的(一个是目的地,一个是出发地)。
RNN拓展
首先,RNN可以是堆叠多层,即隐含层不止一层,每一个隐含层都可以储存输出,形成深度的循环网络。
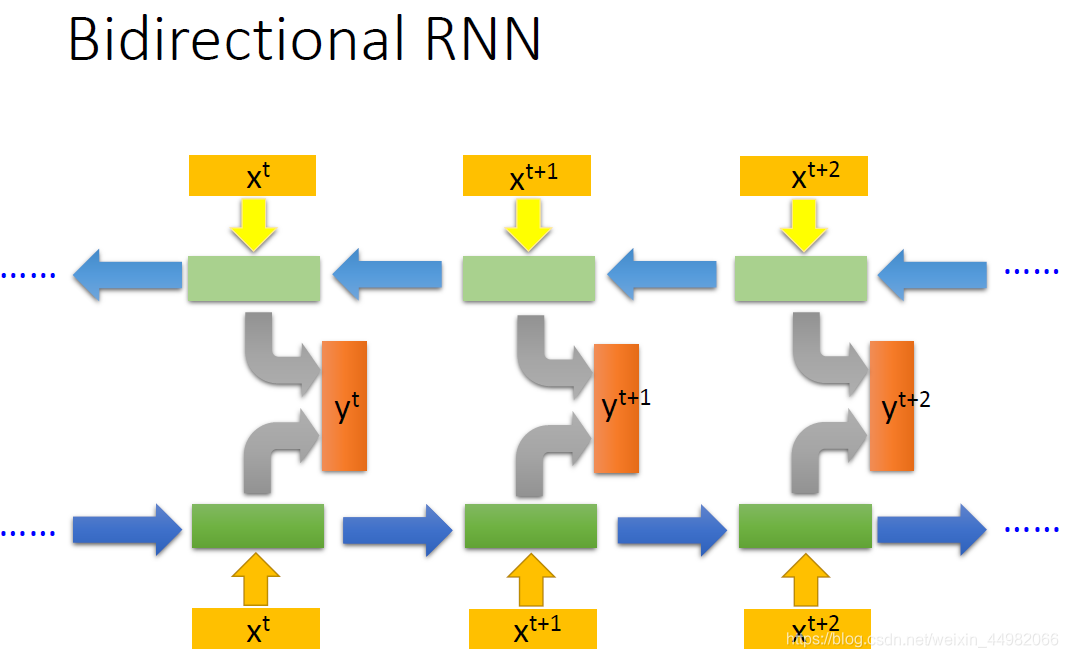
如果希望不仅参照前面的输入,还要参照后面的输入,那么可以使用双向RNN结构(Bidirectional RNN),首尾对接起来,再将两个的输出结合运算。
RNN的缺陷
由于RNN的BPTT算法,某一时刻的输出将会反向传播到前面所有时刻的系数,因此会出现较长的连乘系数。如果连乘系数小,则会出现梯度消失问题;如果连乘系数大,则会出现梯度爆炸问题。因此,RNN不适合输入序列较长的问题。
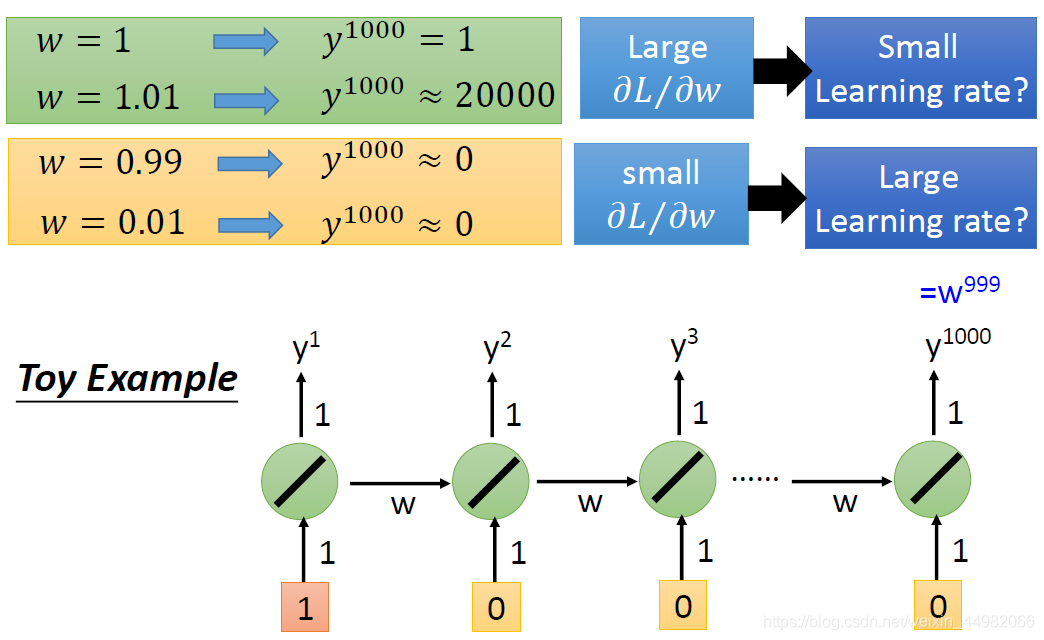
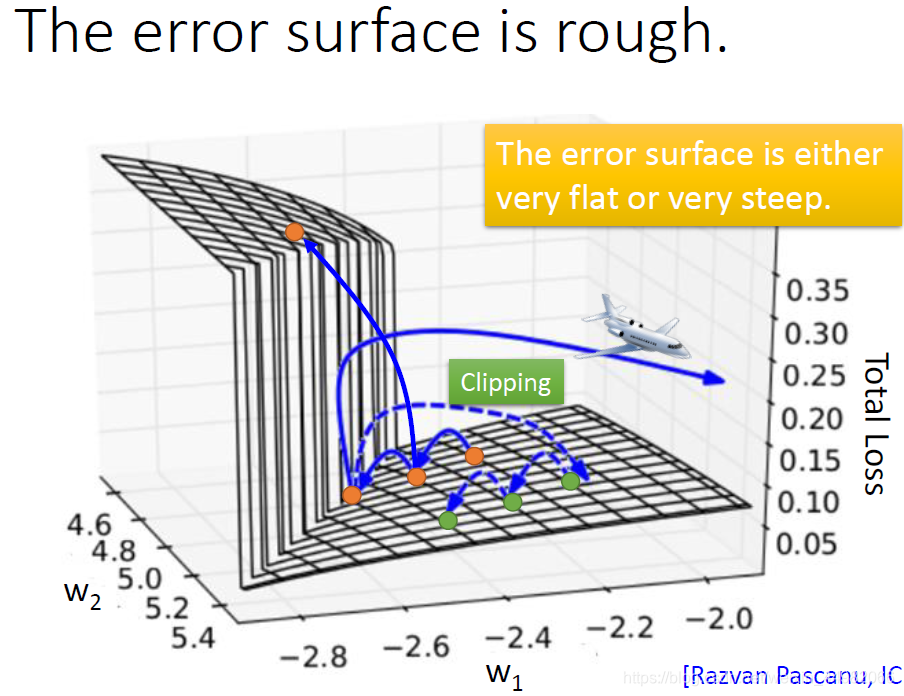
有学者做过相关的研究,将所有权值测试了一遍绘制出一张误差平面图。可以清晰地看到,在两个权值达到一定值的时候误差平面呈断崖式下跌,此时调整权值很容易出现问题。
LSTM(Long short-term memory)
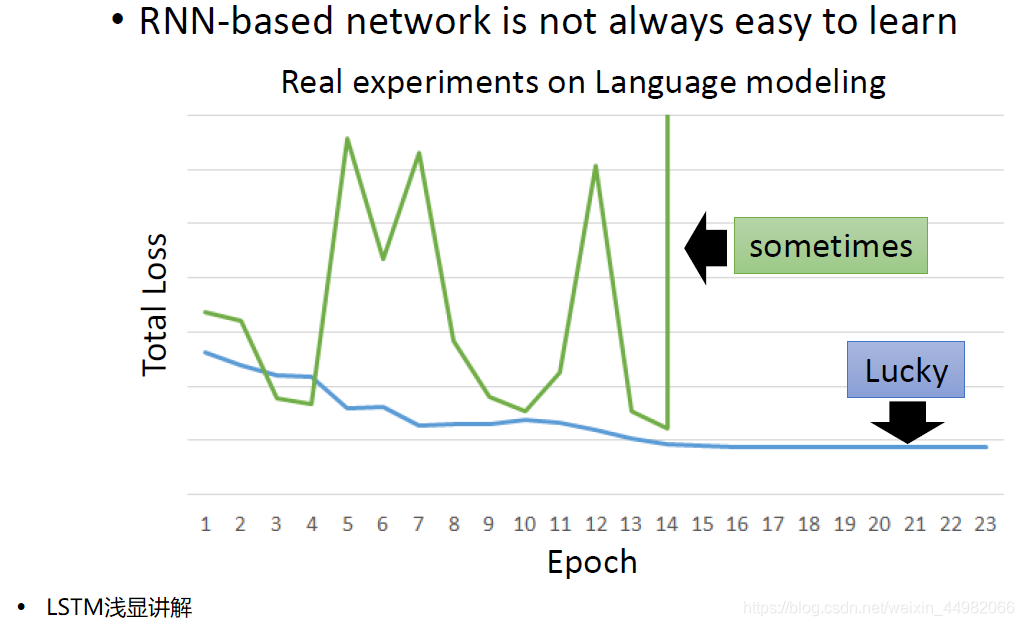
简单的RNN训练非常困难,而LSTM可以解决RNN的梯度消失问题。 这是因为LSTM的存储会进行相加计算,则除非遗忘门重置,之前对存储造成的影响将被保留,而RNN的存储在每一次运算都会被重置,因此前期造成的影响对后面的结果越来越小,也就是梯度消失的问题。
简化版介绍
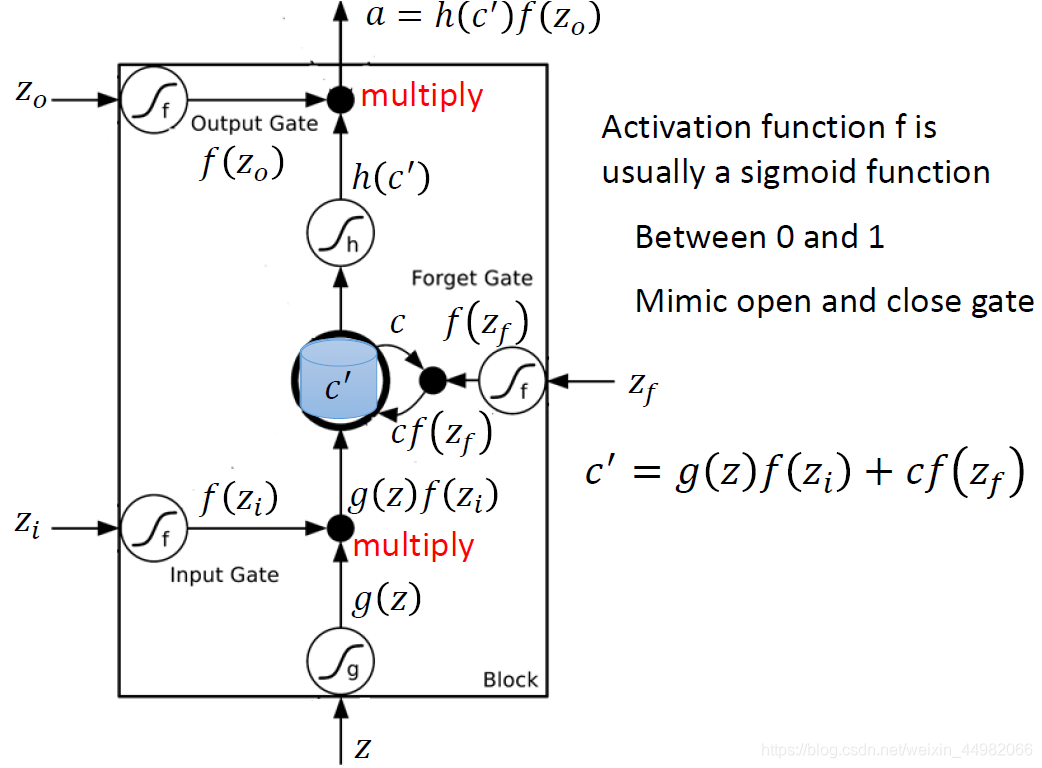
首先,LSTM神经元中有三个称为门的计算单元:输入门、输出门和遗忘门。
- 输入门打开时,网络的外界输入才能进入神经元(cell)进行存储。
- 输出门打开时,存储在神经元(cell)中的信息才会被读取并参与运算。
- 遗忘门打开时,存储在神经元(cell)信息得以保留,关闭时会清除存储数据。
则一个LSTM有四个输入:三个控制门开闭的信号和一个数据输入。
三个门信号是由三个外界输入通过sigmoid函数得到0~1之间的数值,表示门的开闭程度。可以看到,输入门信号和输入数据会相乘,最后的存储数据除了上面之外还要加上遗忘门信号乘上之前的存储值。因此如果输入门信号为0,则相当于没有接收外界输入;如果遗忘门信号为0,则相当于清除之前的数据。同理可以理解输出门的信号。
将上面的结构看作是一个神经元,每个输入则看作是由一个相同的输入经过不同的激活函数和变换得到的四种不同的输入。因此,相较于简单的RNN,LSTM有四倍的参数量。
具体来说,可以看做是网络的输入 xt 经过不同的运算变成四个不同的输入向量,向量的每一维都会被输入到一个LSTM中不同的位置。
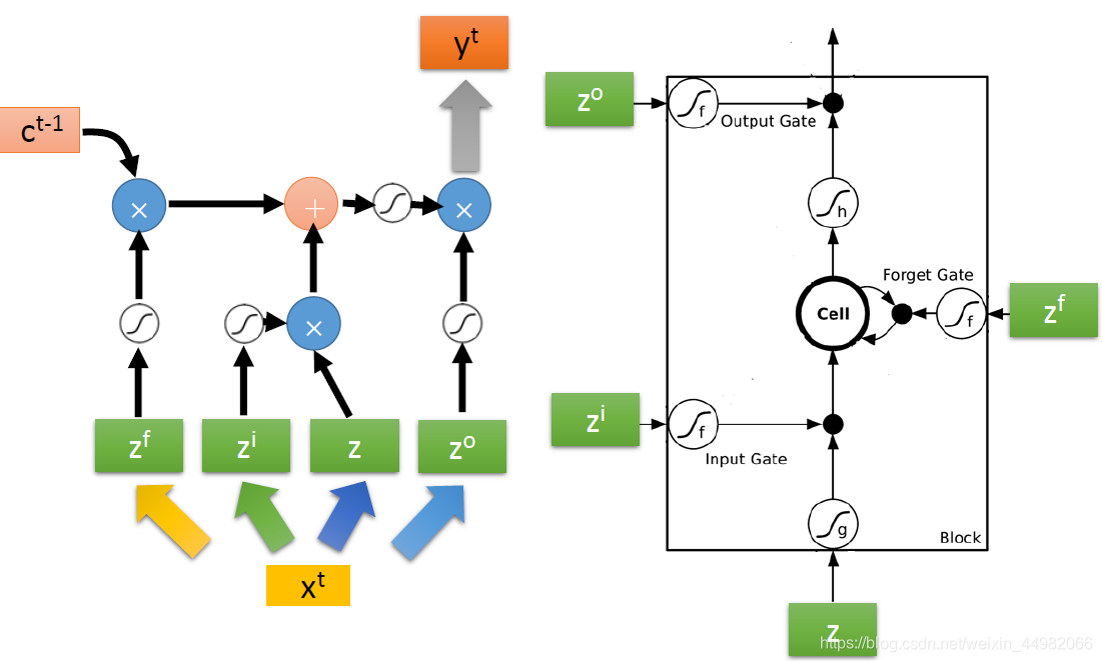
实际上LSTM会把输出也作为输入的一部分参与运算。(下图的y和h都表示LSTM的输出)
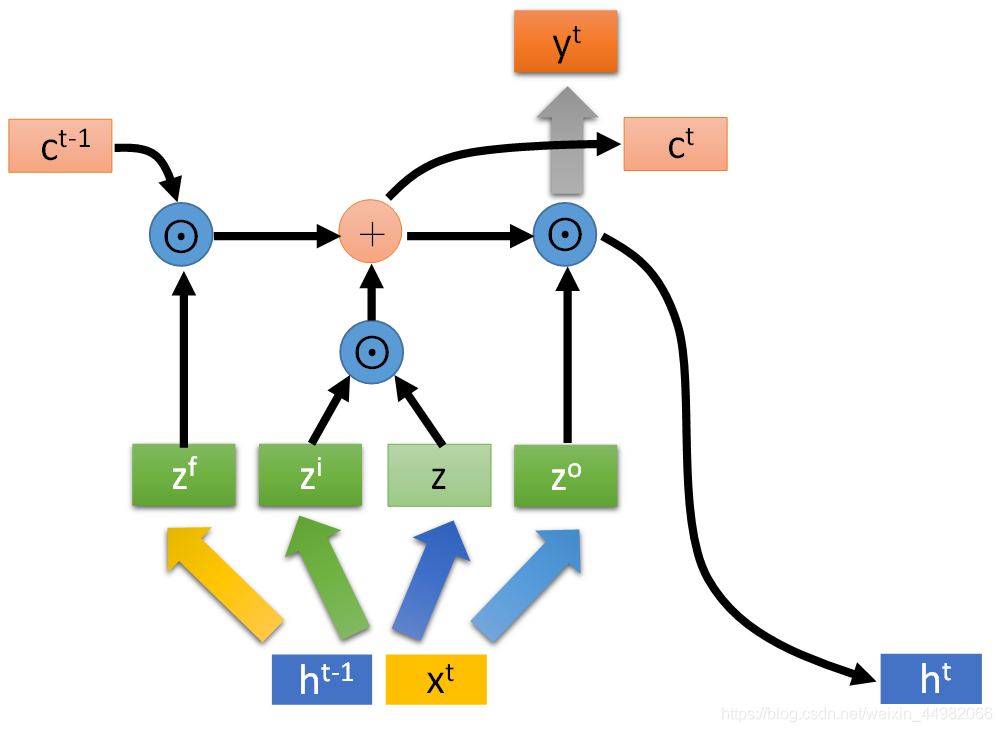
LSTM也可以像RNN一样堆叠多层,不过由于LSTM的参数量是简单RNN的四倍,因此容易出现过拟合的问题,所以出现了简化版本的GRU,可以理解为输入门与遗忘门开闭状态必须相反。
详细版介绍
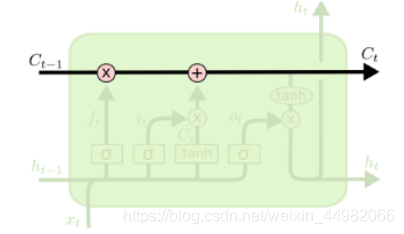
LSTM中有两种记忆:C表示长时记忆,h表示短时记忆。h类似简单RNN中的隐含层的状态参数,而C则是称为细胞状态的参数。在LSTM中的结构如下图。
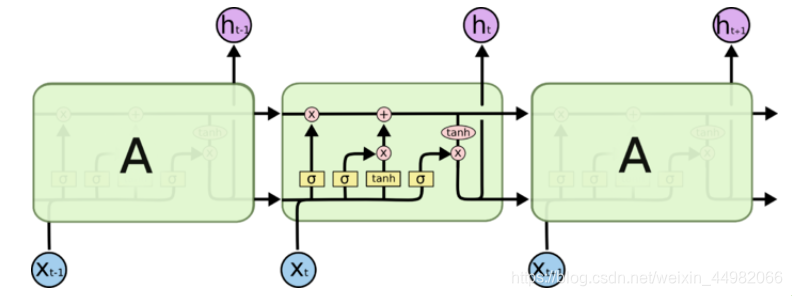
细胞状态存在于最上面直线中,在整条连通的链路中,只进行少量的线性交互(相加),通过各种门信号的运算向C中更新信息。细胞状态相当于之前的存储信息,因为变化较小,因此称为长时记忆。
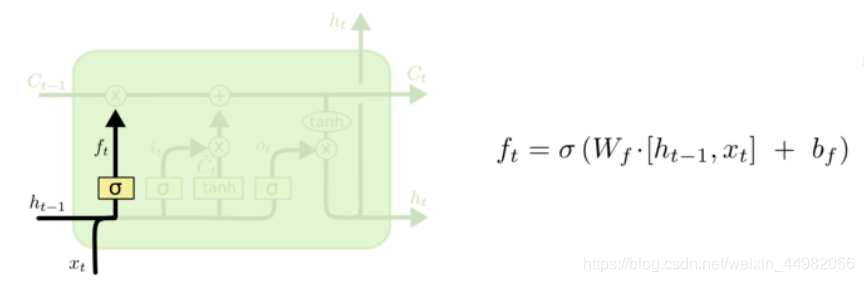
下面给出遗忘门的计算过程:ht-1 表示历史信息,xt 表示当前输入LSTM中新的信息。ft则可以理解为所提到的遗忘门信号。
进一步给出输入门计算过程:it为计算出的输入门信号,新候选向量C~t为需要存储的信息。之后对细胞状态(即存储的信息)进行更新,加上新的数值。
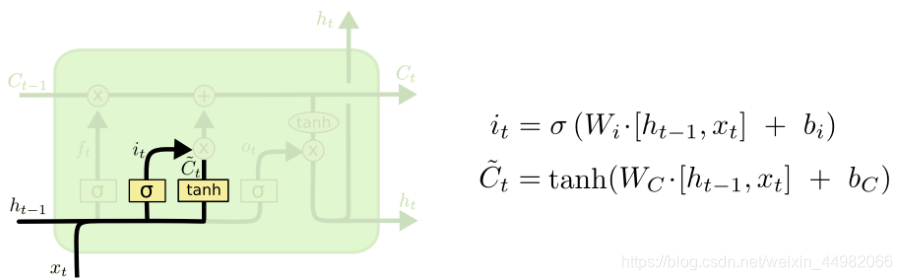

最后,给出输出门计算:ot为输出门信号,ht为最终的LSTM的输出。

虽然两个版本的介绍图片中的字母可能有所不同,但是实际上表达的是一个意思,不妨可以推推看,两个计算过程完全是一样的。
总结
本章我们介绍了RNN和LSTM两个系列的神经网络,以它们为基础构成的语言模型得到了广泛的应用,我们将在下一次进行介绍。
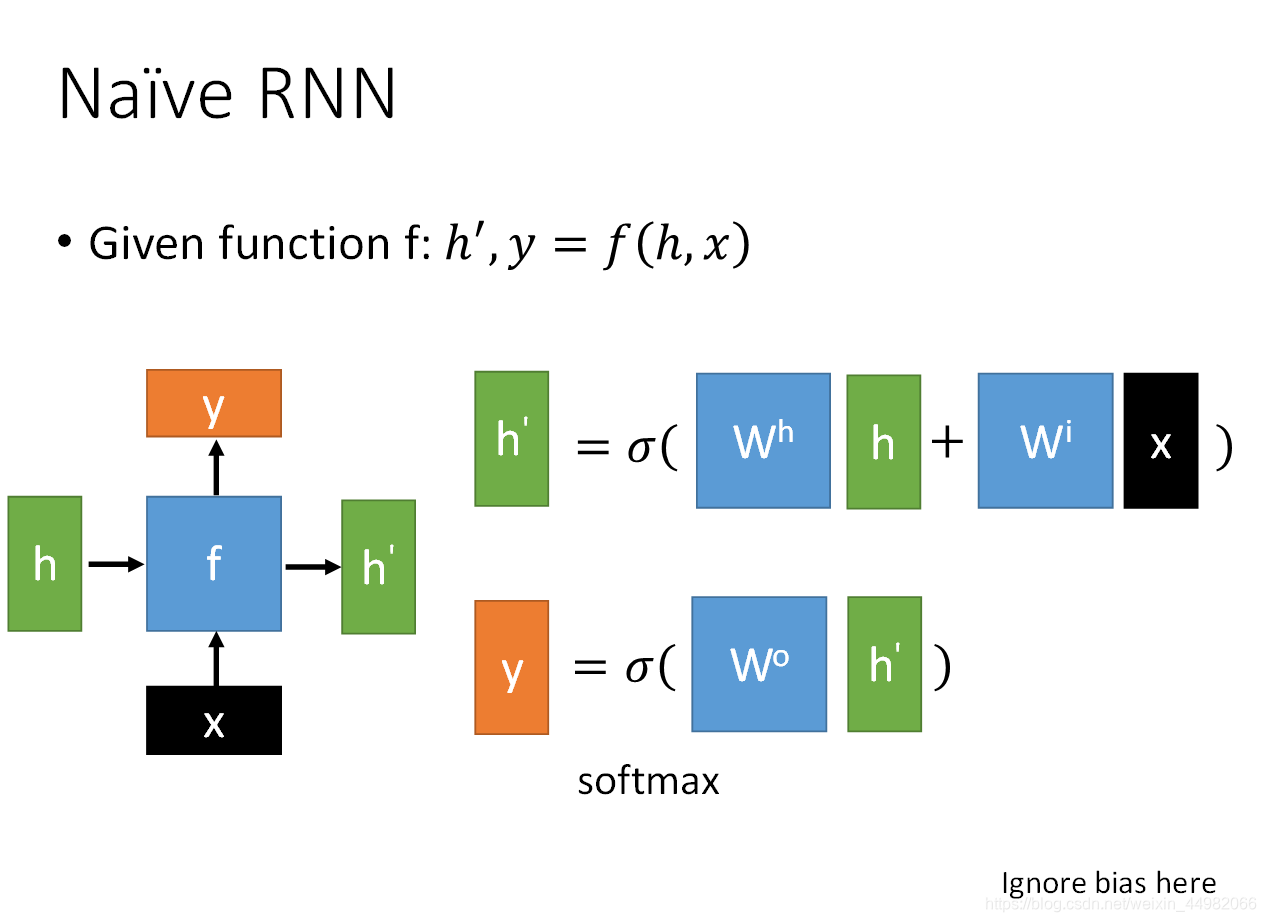
最后,为了为下一次介绍方便,这里再将RNN和LSTM进行一下简化:
将RNN简化一下,看作是两个输入:h、x,两个输出:h’,y。中间经过一个函数f()。

而双向RNN则变为:

将LSTM简化一下,三个输入,三个输出:c只是线性加上了一个数值,整体变化不会太大;而h则有可能每次输入运算后不太相同。将之前各个门信号的计算看作一个整体z,得到右边的式子。

