
题目:ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
https://github.com/google-research/ALBERT.
动机
降低模型大小,并改进性能
采用两种参数简化技术:
- factorized embedding parameterization(对Embedding因式分解)。
- Cross-layer parameter sharing.
相比于BERT的改进
定义
ALBERT架构的主干类似于BERT(Transformer encoder with GELU),词embedding大小表示为E,number of encoder layer 表示为L,hidden_size表示为H。FNN/fliter大小设置为4H,attention的head个数设置为H/64。
Factorized embedding parameterization.
BERT中, E E E ≡ H H H ≡768,思考:词嵌入意味着学习上下文无关的表示,隐藏层嵌入学习上下文表示,理论上隐藏层表示的信息应该更多一些,应该让 H H H>> E E E。
从实用的角度来看,自然语言处理通常要求词汇量 V V V很大,如果 E E E≡ H H H,那么就增加了嵌入矩阵的大小( V V V× E E E),ALBert对Embedding因式分解,首先将one-hot投影到一个低维空间,大小为 E E E,然后再将结果映射到一个高纬空间,大小为 H H H,所以参数量从 O O O( V V V× H H H)讲到 O O O( V V V× E E E+ E E E× H H H),在 H H H>> E E E的情况下,参数大大减少。但是,不采用参数共享优化方案时E设置为768效果反而好一些,在采用了参数共享优化方案时E取128效果更好一些。
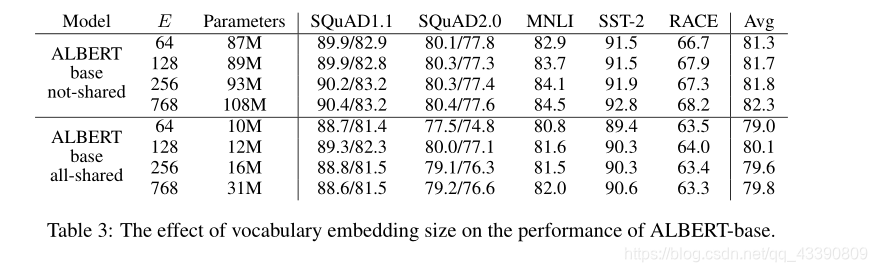
Cross-layer parameter sharing.
Transformer中共享参数有多种方案,只共享全连接层,只共享attention层,ALBERT结合了上述两种方案,全连接层与attention层都进行参数共享,也就是说共享encoder内的所有参数,同样量级下的Transformer采用该方案后实际上效果是有下降的,但是参数量减少了很多,训练速度也提升了很多。
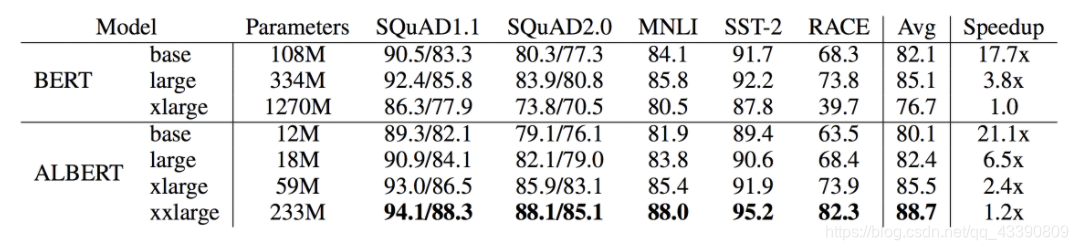
下图是BERT与ALBERT的一个对比,以base为例,BERT的参数是108M,而ALBERT仅有12M,但是效果的确相比BERT降低了两个点。由于其速度快的原因,我们再以BERT xlarge为参照标准其参数是1280M,假设其训练速度是1,ALBERT的xxlarge版本的训练速度是其1.2倍,并且参数也才223M,评判标准的平均值也达到了最高的88.7
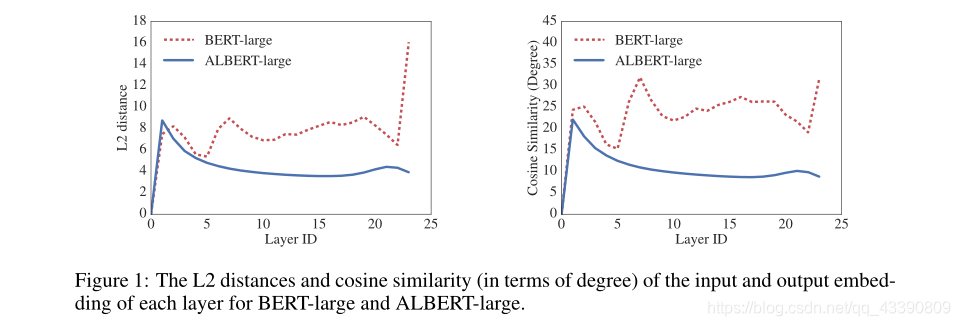
另外,ALBERT每一层的输出的embedding相比于BERT来说震荡幅度更小一些。下图是不同的层的输出值的L2距离与cosine相似度,可见参数共享其实是有稳定网络参数的作用的。
Inter-sentence coherence loss
BERT的NSP任务实际上是一个二分类,训练数据的正样本是通过采样同一个文档中的两个连续的句子,而负样本是通过采用两个不同的文档的句子。该任务主要是希望能提高下游任务的效果,例如NLI自然语言推理任务。但是后续的研究发现该任务效果并不好,主要原因是因为其任务过于简单。NSP其实包含了两个子任务,主题预测与关系一致性预测,但是主题预测相比于关系一致性预测简单太多了,并且在MLM任务中其实也有类型的效果。
主题预测的缺点: 因为正样本是在同一个文档中选取的,负样本是在不同的文档选取的,假如我们有2个文档,一个是娱乐相关的,一个是新中国成立70周年相关的,那么负样本选择的内容就是不同的主题,而正样都在娱乐文档中选择的话预测出来的主题就是娱乐,在新中国成立70周年的文档中选择的话就是后者这个主题了。
在ALBERT中,为了只保留一致性任务去除主题识别的影响,提出了一个新的任务 sentence-order prediction(SOP),SOP的正样本和NSP的获取方式是一样的,负样本把正样本的顺序反转即可。SOP因为实在同一个文档中选的,其只关注句子的顺序并没有主题方面的影响。并且SOP能解决NSP的任务,但是NSP并不能解决SOP的任务,该任务的添加给最终的结果提升了一个点。

4、移除dropout
除了上面提到的三个主要优化点,ALBERT的作者还发现一个很有意思的点,ALBERT在训练了100w步之后,模型依旧没有过拟合,于是乎作者果断移除了dropout,没想到对下游任务的效果竟然有一定的提升。这也是业界第一次发现dropout对大规模的预训练模型会造成负面影响。
结论
虽然ALBERT-xxlarge的参数比BERT-large少,并且获得了明显更好的结果,但由于其更大的结构,它的计算成本更高(推理时间相比于BERT更长)。
参考
1.https://blog.csdn.net/u012526436/article/details/101924049
2.ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS