最近在家听贪心学院的NLP直播课。放到博客上作为NLP 课程的简单的梳理。
简介:虽然BERT模型本身是很有效的,但这种有效性依赖于大量的模型参数,所以训练一套BERT模型所需要的时间和资源成本是非常大的,甚至这样复杂的模型也会影响最终效果。在本次讲座里,我们重点来介绍一种瘦身版的重磅BERT模型 - ALBERT,它通过几种优化策略来获得比BERT小得多的模型,但在GLUE, RACE等数据集上反而超越了BERT模型。
ALBERT: A Lite BERT for Language understanding
回顾BERT
NLP 突破性进展,基于全网络、预训练模型。
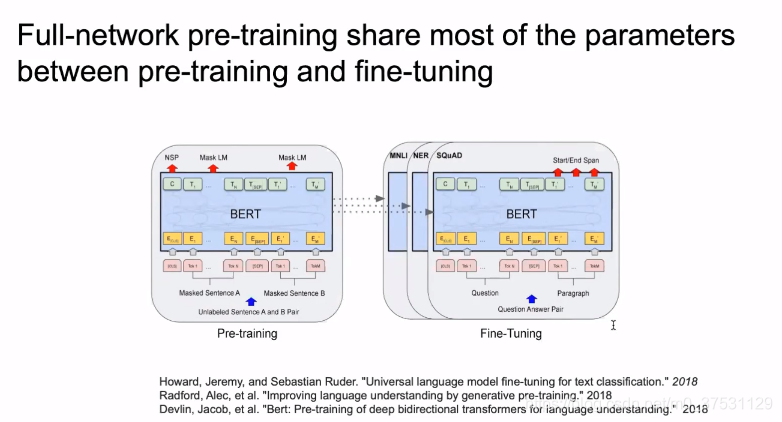
下图是全网络预训练模型 是 NLU领域的AlexNet(点燃AI的模型)
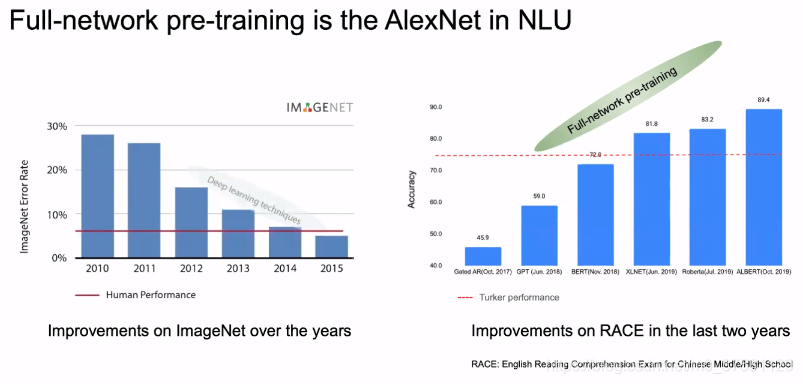
由于全网络预训练的原因 对于NLU的准确度 有突破性进展(从GPT开始)。

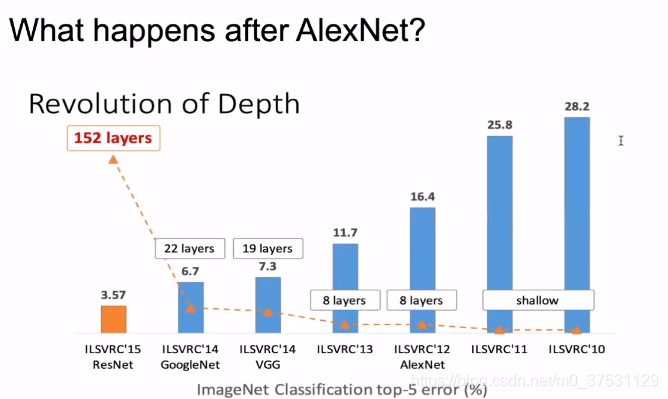
在计算机视觉里面 主要是网络的加深(之前的浅层神经网络error一直很高,从AlexNet 8层开始Error显著下降,到后面152层降低到3.57%)
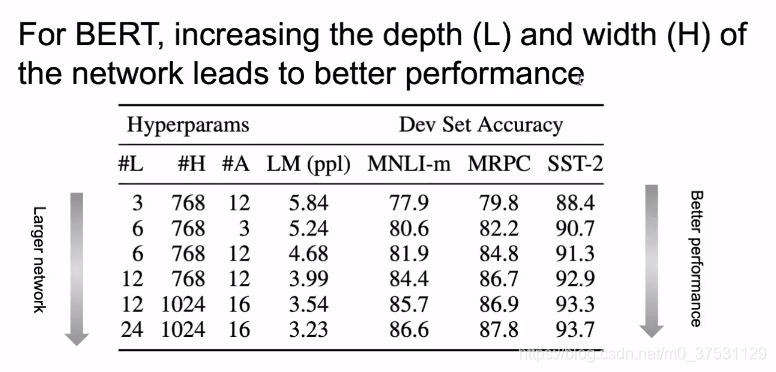
同样的 在BERT里面 随着网络加深(L)和加宽(H)结果会越来越好。
那么是不是简单的把网络加深变大 就会得到更好的效果?

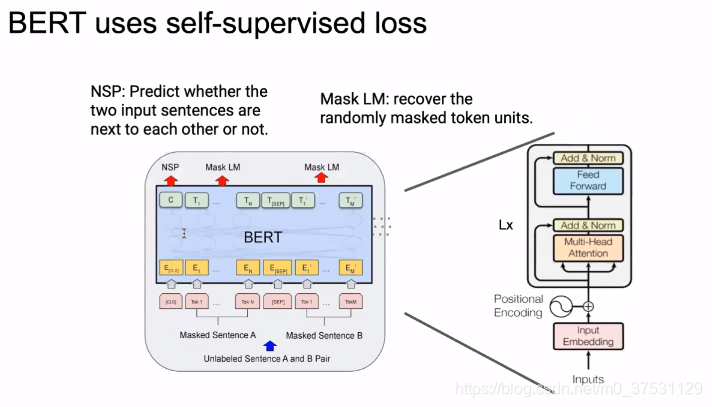
我们看一下BERT,bert里面是结合2个任务 一个是NSP一个是MLM
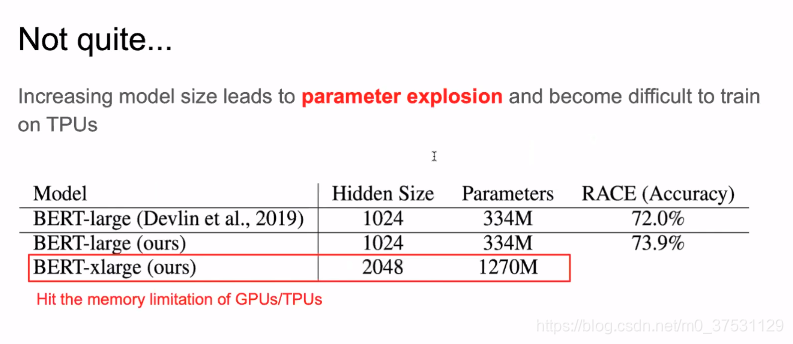
首先,我们恢复了BERT-Large的结果,并有了一些提升(73.9%)
然后,把宽度变成2倍之后,参数达到了1270M, 很快内存就不够了。
那么,我们能否在减少参数的情况下提高效果?
1. 降低模型参数,加宽加深模型

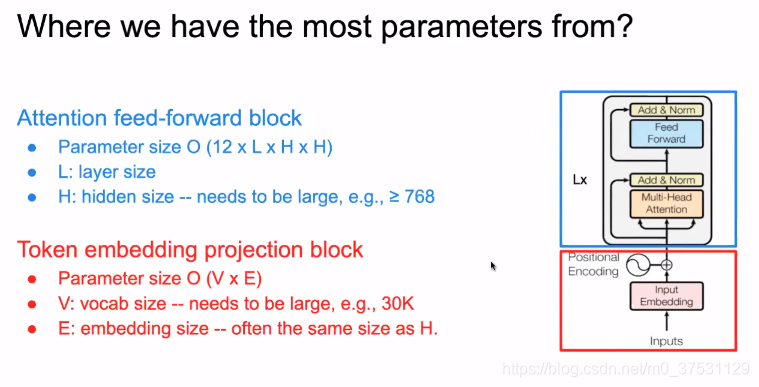
那么,我们就要看 Transformer 和BERT的主要参数来自于哪里?
Transformer 主要是2个部分,
输入部分:token embedding ,参数大小为 O(V*E), V是vocab size ,E是embedding size.
处理模块: 有12 * L * H *H 个参数。(80%)
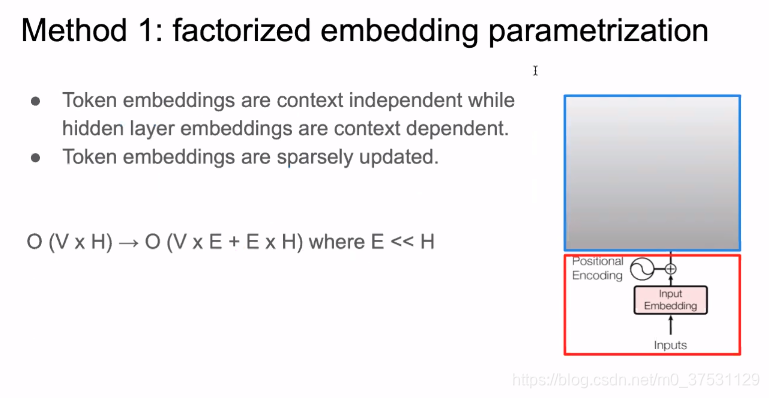
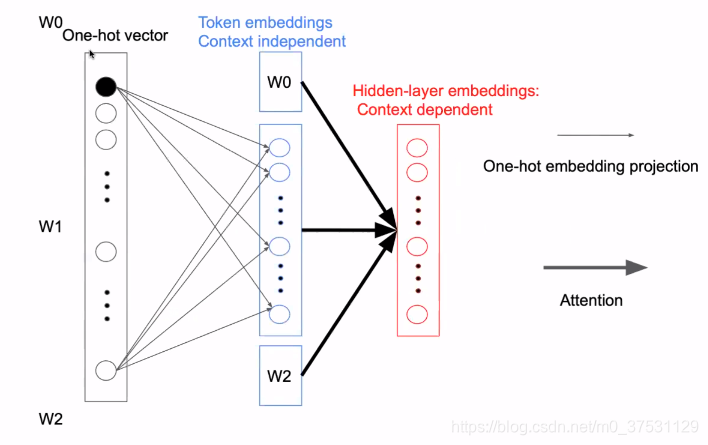
第一个是 one hot vector 是BERT的输入,首先通过全连接变成一个 dens embedding. 但是这里是稀疏编码(sparsing code) ,因为只需要更新一个 其他位置都是0,第二个原因是 这里是content independent ,到这里目前是上下文无关的,所以不需要用很高的维度来表示。
所以我们这里把One-hot -> Token embedding 进行矩阵分解 来降低模型参数。
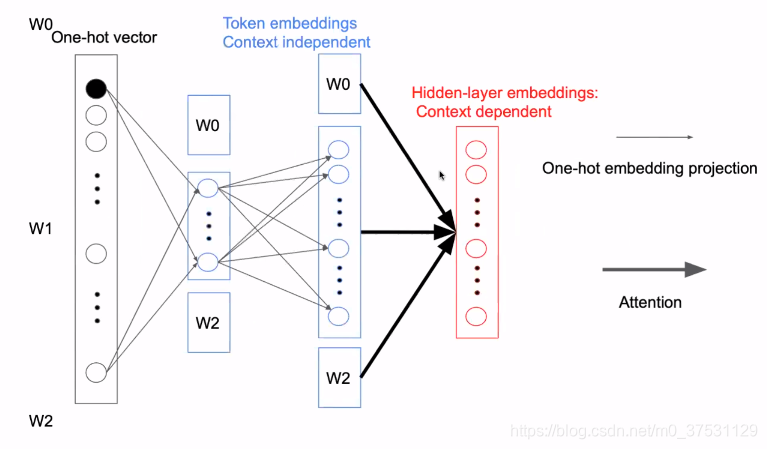
所以我们把context independent 这块儿通过矩阵分解 分成2部分。这样做的好处是:
第一,是可以自由把网络变宽。
第二,是 embedding size 变小后,整个模型就可以随意加深。

降低参数 是通过 矩阵分解,进行先降维后升维度。当E << H 时,参数降低很多。
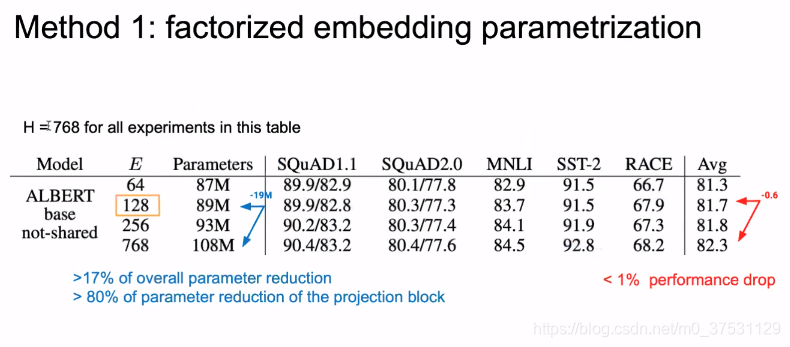
在BERT 中H=768。
我们这里把E变小,Bert中原始为768,参数为108M,我们减少到128后,参数为89M,这个模块的参数减少了 80%。但是结果只有0.1%的损失。
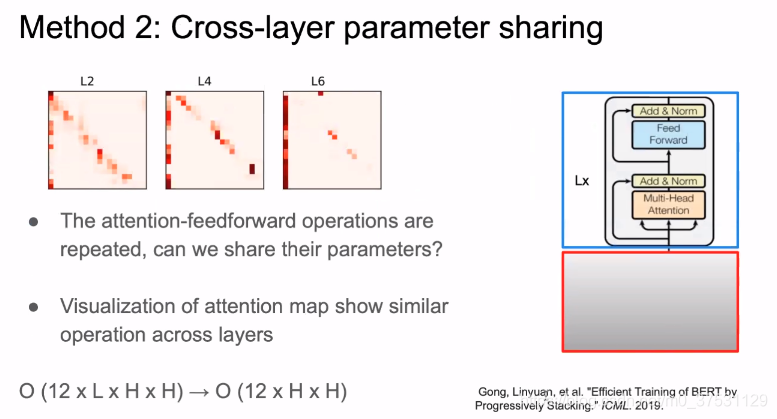
上图是BERT attention layer的可视化,基本上可以看到都是三角线上。(不同层 之间 参数的相似度很高)
第一个列是word embedding, 对角线是周围的词。如果各个layer的参数 是不是相似,如果相似的话 那么由 12LHH 可以变成121 * H*H 个参数。
那么,我们做实验对比,全部共享参数,和只共享attention的参数,和只共享FNN的参数。结果如下:
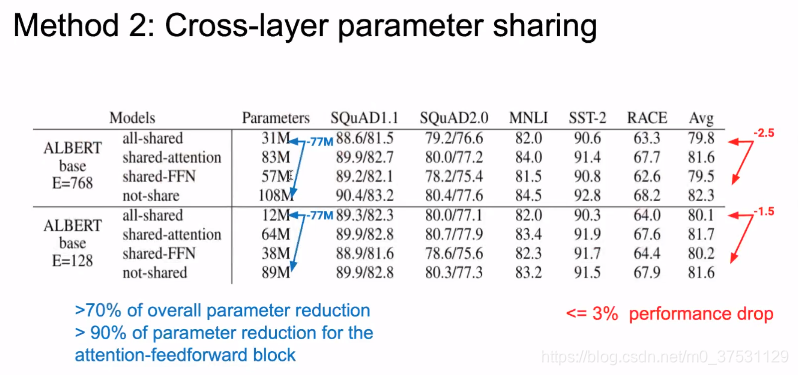
我们可以看到ALBERT E=768时,所有参数共享时, 参数大小是 31M,效果只是drop了2.5%。E=128时,共享所有参数后,参数大小压缩到12M,结果只drop了1.5%.
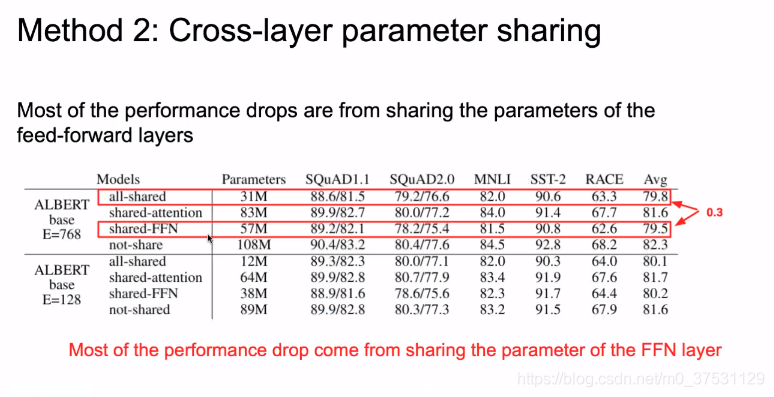
我们可以看到 全部共享和只共享FNN结果是几乎一样的。 共享attention layer 参数 几乎没有降低结构。
因为attention layer (3/8的参数)和FNN(5/8的参数)
最后ALBERT模型选择全部参数共享。
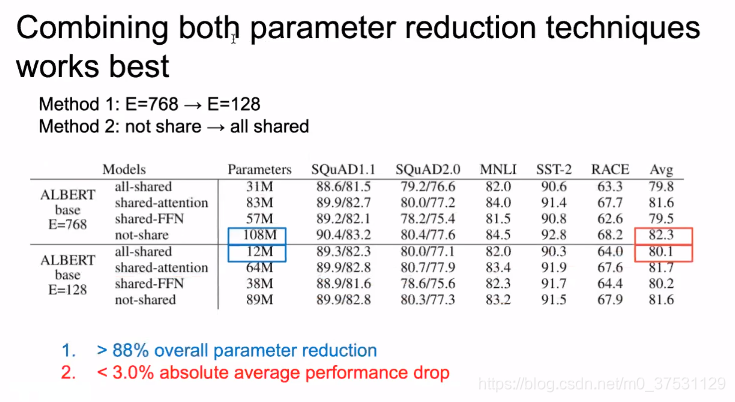
可以看出 参数 从108M --> 12M, 结从82.3->80.3.
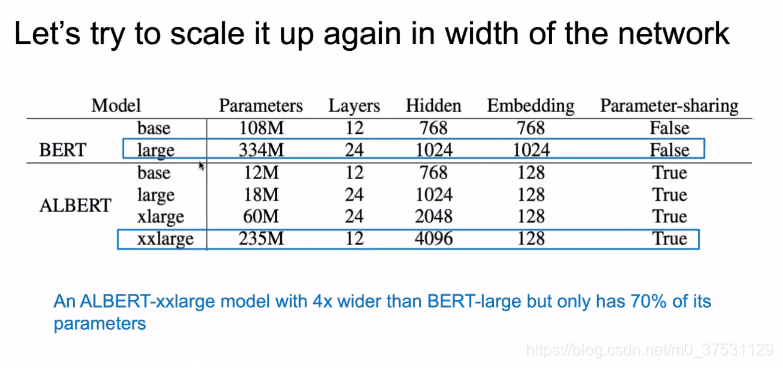
模型参数压缩后,我们就可以再变宽和变深 这里就不会超过内存了。
上面可以看出ALBERT的参数量 降低了很多,那么我们开始加宽模型,比如xlarge 和 xxLarge 敌营的参数量比BERT 还是低70%.
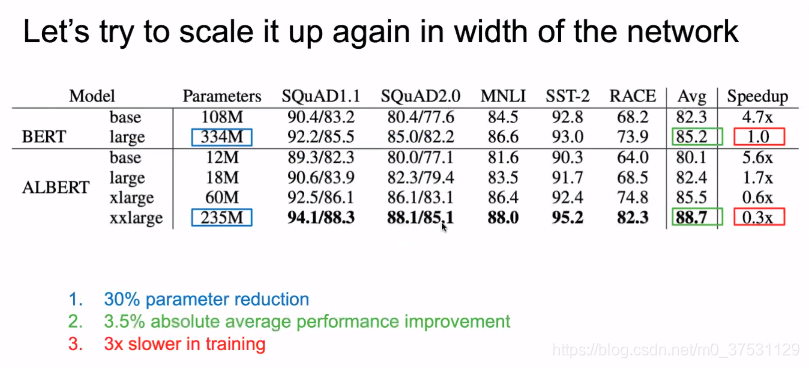
变宽后的结果 也提升了 88.7%。
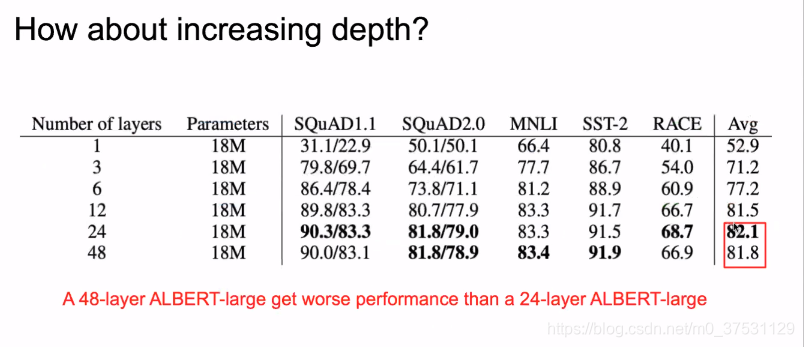
那么我们可以看变深后的结果 如何? 这里显示6-12后变好了 但是24-48后 平均结果却降低了。。。这个还在研究。
我们选择了12层。
2. 改进NSP任务为SOP

Bert 用到了NSP任务,是通过正负样本来构造输入数据。正样本是来自同一个文章的相邻的句子, 负样本是来自不同的文本里面的。
其实网络更容易学到这种模式的NSP,因为模型学到的不一定时真正的is next 而是通过学到前后句子的主题就可以区分是否为下个句子。所以很多模型说NSP没啥用。
但是我们认为句子的连续性学习 还是重要的。只是我们要改进训练的数据集。
为了让网络学到句子连续性的,我们改进了样本,正样本是正确的next sentence,负样本 我们通过将第一句和第二句反过来构造样本,这样的网络就不能通过主题学习 这个模型。

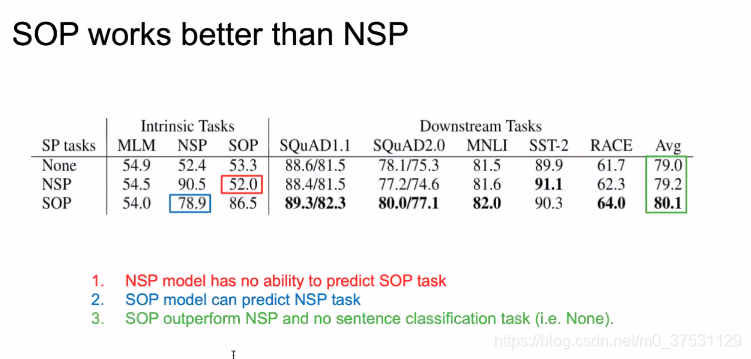
上图结果可以看出,
SOP task 中,无论是否有NSP 结果都是~52% 相当于乱猜,所以NSP并没有学到真正的next sentence.
NSP task 中,通过NSP,SOP 训练,结果有提升。
我们在各个下游任务中,SOP任务的结果 比 NSP 任务的结果 还是有提升的。
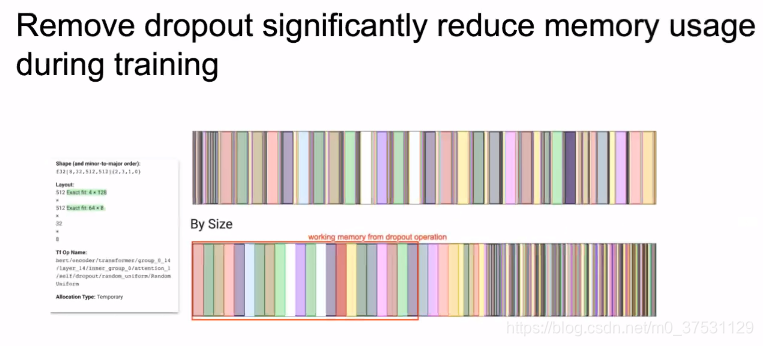
3. 去掉dropout

另外一个改进就是 去掉了drop out.
在MLM 中我们可以把全网络的数据都拿来学,所以数据不是问题,第二个是网络学习NLU比较难,只要学习越久结果肯定会越好,我们去掉dropout 因为不担心overfitting的问题。
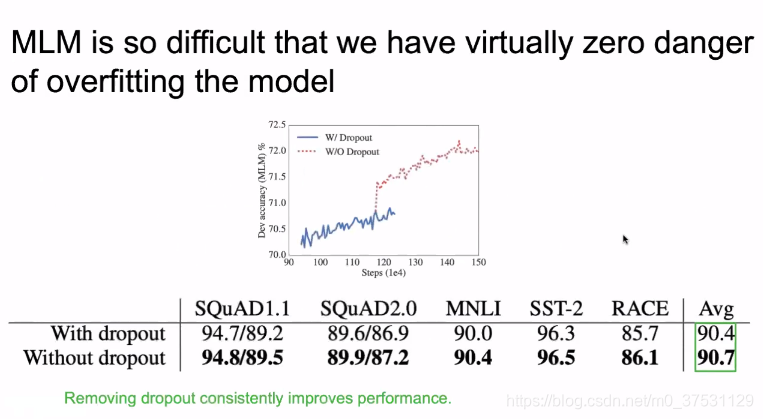
remove drop out 在下游任务上的提升不算太多。
但是在内存上提升很多,因为dropout 操作会增加很多临时变量。
4. 增加训练数据

最后就是加数据量,不过结果显示 提升并不是很高。

总结

- 通过矩阵分解,参数共享 得到更好的提升。
- 通过改进NSP任务 改为SOP,也得到了提升。
- 改进模型,去除dropout 得到内存的提高。
- 增加训练数据。
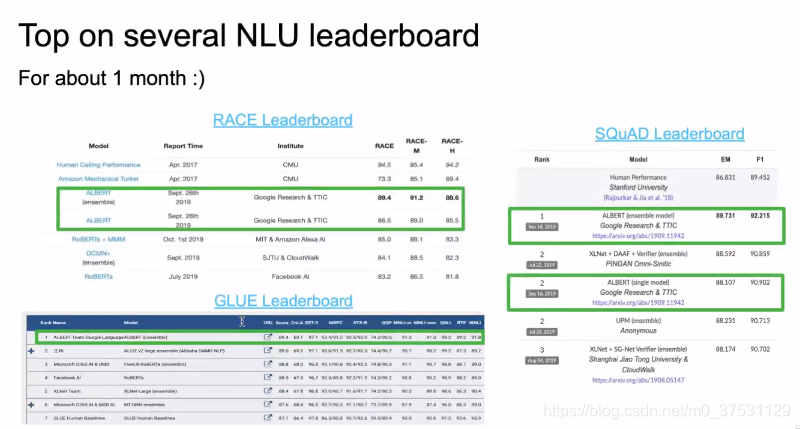
目前还在继续 改进和提升,比如改进 Transformer等。



(做summarization时 encoder和decoder 也可以共享参数)
