
论文地址:https://openreview.net/pdf?id=H1eA7AEtvS
中文预训练ALBERT模型:https://github.com/brightmart/albert_zh
曾经,预训练是大模型(玩家)的天下
语言表征学习领域的这些进展表明,大模型对于实现 SOTA 性能表现极其重要。预训练大模型,并在实际应用中将它们提炼成更小的模型已经成为一种常见的做法。考虑到模型大小的重要性,研究者提出一个问题:建立更好的 NLP 模型像构建更大的模型一样容易吗?
解答该问题的难点在于可用硬件的内存会受到限制。考虑到当前的 SOTA 模型常常包含数亿甚至数十亿参数,扩展模型时很容易受到内存的限制。
研究者还观察到,仅仅增加 BERT-large 等模型的隐藏层大小也会导致性能下降。如下表 1 和图 1 所示,研究者将 BERT-large 的隐藏层大小增加一倍,该模型(BERT-xlarge)在 RACE 基准测试上的准确率显著降低。

表 1:增加 BERT-large 的隐藏层大小,模型在 RACE 上的表现变差。

图 1:BERT-large 和 BERT-xlarge 的训练损失(左)和 dev mask 的 LM 准确率(右)。模型增大之后,其 mask LM 准确率降低了,同时没有出现明显的过拟合迹象。
现在,小模型也已崛起(其实还是玩不起)
为了解决上述问题,谷歌的研究者设计了「一个精简的 BERT」(A Lite BERT,ALBERT),参数量远远少于传统的 BERT 架构。
ALBERT 通过两个参数削减技术克服了扩展预训练模型面临的主要障碍。
- 第一个技术是对嵌入参数化进行因式分解。研究者将大的词汇嵌入矩阵分解为两个小的矩阵,从而将隐藏层的大小与词汇嵌入的大小分离开来。这种分离使得隐藏层的增加更加容易,同时不显著增加词汇嵌入的参数量。
- 第二种技术是跨层参数共享。这一技术可以避免参数量随着网络深度的增加而增加。两种技术都显著降低了 BERT 的参数量,同时不对其性能造成明显影响,从而提升了参数效率。ALBERT 的配置类似于 BERT-large,但参数量仅为后者的 1/18,训练速度却是后者的 1.7 倍。
这些参数削减技术还可以充当某种形式的正则化,可以使训练更加稳定,而且有利于泛化。
为了进一步提升 ALBERT 的性能,研究者还引入了一个自监督损失函数,用于句子级别的预测(SOP)。SOP 主要聚焦于句间连贯,用于解决原版 BERT 中下一句预测(NSP)损失低效的问题。
基于这些设计,ALBERT 能够扩展为更大的版本,参数量仍然小于 BERT-large,但性能可以显著提升。研究者在知名的 GLUE、SQuAD 和 RACE 自然语言理解基准测试上都得到了新的 SOTA 结果:在 RACE 上的准确率为 89.4%,在 GLUE 上的得分为 89.4,在 SQuAD 2.0 上的 F1 得分为 92.2。
ALBERT 的三大改造
前面已经展示了小模型的优势,以及 ALBERT 的核心思想,那么 ALBERT 具体结构又是怎么样的。在这一部分中,我们将简要介绍 ALBERT 的三大模块,并提供与标准 BERT 的量化对比。
ALBERT 架构的骨干网络与 BERT 是相似的,即使用 Transformer 编码器和 GELU 非线性激活函数。现在先约定一下 BERT 的表示方式,即指定词嵌入大小为 E、编码器层数为 L、隐藏层大小为 H。与 Devlin 等人的研究一样,这篇论文将前馈网络/滤波器大小设置为 4H,将注意力 Head 的数量设置为 H/64。如下将介绍 ALBERT 的三大特效。
嵌入向量参数化的因式分解
在 BERT 以及后续的 XLNet 和 RoBERTa 中,WordPiece 词嵌入大小 E 和隐藏层大小 H 是相等的,即 E ≡ H。由于建模和实际使用的原因,这个决策看起来可能并不是最优的。
从建模的角度来说,WordPiece 词嵌入的目标是学习上下文无关的表示,而隐藏层嵌入的目标是学习上下文相关的表示。通过上下文相关的实验,BERT 的表征能力很大一部分来自于使用上下文为学习过程提供上下文相关的表征信号。因此,将 WordPiece 词嵌入大小 E 从隐藏层大小 H 分离出来,可以更高效地利用总体的模型参数,其中 H 要远远大于 E。
从实践的角度,自然语言处理使用的词典大小 V 非常庞大,如果 E 恒等于 H,那么增加 H 将直接加大嵌入矩阵的大小,这种增加还会通过 V 进行放大。
因此,对于 ALBERT 而言,研究者对词嵌入参数进行了因式分解,将它们分解为两个小矩阵。研究者不再将 one-hot 向量直接映射到大小为 H 的隐藏空间,而是先将它们映射到一个低维词嵌入空间 E,然后再映射到隐藏空间。通过这种分解,研究者可以将词嵌入参数从 O(V × H) 降低到 O(V × E + E × H),这在 H 远远大于 E 的时候,参数量减少得非常明显。
O(V * H) to O(V * E + E * H)
如以ALBert_xxlarge为例,V=30000, H=4096, E=128
那么原先参数为V * H= 30000 * 4096 = 1.23亿个参数,现在则为V * E + E * H = 30000*128+128*4096 = 384万 + 52万 = 436万,
词嵌入相关的参数变化前是变换后的28倍。跨层参数共享(参数量减少主要贡献)
- 这主要是为了减少参数量(性能轻微降低,参数大量减少,这整体上是好的事情)
- 论文里的消融实验的分数也说明no-share的分数是最高的
对于 ALBERT,研究者提出了另一种跨层参数共享机制来进一步提升参数效率。其实目前有很多方式来共享参数,例如只贡献前馈网络不同层之间的参数,或者只贡献注意力机制的参数,而 ALBERT 采用的是贡献所有层的所有参数。
参数共享能显著减少参数。共享可以分为全连接层、注意力层的参数共享;注意力层的参数对效果的减弱影响小一点。这种机制之前也是有的,但研究者的度量发现词嵌入的 L2 距离和余弦相似性是震荡而不是收敛。如下图 2 展示了每一层输入与输出嵌入矩阵间的 L2 距离与余弦相似性。
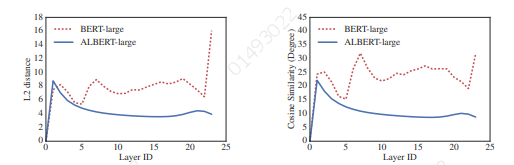
图 2:BERT-Large 与 ALBERT-Large 每一层输入嵌入与输出嵌入间的 L2 距离与余弦相似性。
研究者发现 ALBERT 从一层到另一层的转换要比 BERT 平滑得多,结果表明,权重共享有效地提升了神经网络参数的鲁棒性。即使相比于 BERT 这两个指标都有所下降,但在 24 层以后,它们也不会收敛到 0。
句间连贯性损失(SOP)
谷歌自己把它换成了 SOP。这个在百度 ERNIE 2.0 里也有,叫 Sentence Reordering Task,而且 SRT 比 SOP 更强,因为需要预测更多种句子片段顺序排列。ERNIE 2.0 中还有一些别的东西可挖,比如大小写预测 Captialization Prediction Task、句子距离 Sentence Distance Task。
- NOP:下一句预测, 正样本=上下相邻的2个句子,负样本=随机2个句子
- SOP:句子顺序预测,正样本=正常顺序的2个相邻句子,负样本=调换顺序的2个相邻句子
- NOP任务过于简单,只要模型发现两个句子的主题不一样就行了,所以SOP预测任务能够让模型学习到更多的信息
BERT使用的NSP损失,是预测两个片段在原文本中是否连续出现的二分类损失。目标是为了提高如NLI等下游任务的性能,但是最近的研究都表示 NSP 的作用不可靠,都选择了不使用NSP。
作者推测,NSP效果不佳的原因是其难度较小。将主题预测和连贯性预测结合在了一起,但主题预测比连贯性预测简单得多,并且它与LM损失学到的内容是有重合的。
SOP的正例选取方式与BERT一致(来自同一文档的两个连续段),而负例不同于BERT中的sample,同样是来自同一文档的两个连续段,但交换两段的顺序,从而避免了主题预测,只关注建模句子之间的连贯性。
具体的损失函数表达式读者可以查阅原论文,但研究者表示,在使用了该损失函数后,ALBERT 能显著提升下游多句子编码任务的性能。
使用段落连续性任务。正例,使用从一个文档中连续的两个文本段落;负例,使用从一个文档中连续的两个文本段落,但位置调换了。
避免使用原有的NSP任务,原有的任务包含隐含了预测主题这类过于简单的任务。
运行一定步后删除Dropout
Dropout 个人觉得可以一开始就不用,而不是训练一段时间再关掉。学都学不动,防啥过拟合啊。
- 模型的内部任务(MLM,SOP等等)都没有过拟合
- dropout是为了降低过拟合而增加的机制,所以对于bert而言是弊大于利的机制

如上图所示,ALBERT的最大模型在训练1M步后仍然没有过拟合,于是作者决定删除dropout,进一步提高模型能力。
Segments-Pair
BERT为了加速训练,前90%的steps使用了128个token的短句子,最后10%才使用512个token的长句子训练位置向量。
ALBERT貌似90%的情况下使用512的segment,从数据上看,更长的数据提供更多的上下文信息,可能显著提升模型的能力。
Masked-ngram-LM
BERT的MLM目标是随机MASK15%的词来预测,ALBERT预测的是N-gram片段,包含更多的语义信息,每个片段长度n(最大为3),根据概率公式计算得到。比如1-gram、2-gram、3-gram的的概率分别为6/11、3/11、2/11.越长概率越小:

读后感就是,所谓的“A Lite Bert”,并不像我所期望的那样“轻量级”。
推荐一篇文章:用深度矩阵分解给词向量矩阵瘦身
