背景
自从Bert横扫各大榜单之后,对Bert的尝试就没有停止过。在这种思路下,实验显示隐藏层数越多,参数量越多,模型的效果越好。虽然效果变好,但是由于GPU/TPU的限制,这些SOA的模型要单机跑起来是很困难的。因此文中提出了一种参数共享的新思路。
Albert的改进
Albert主要是从三方面对Bert进行了改进
Emebdding因式分解(Factorized embedding parameterization)
在Bert, XLNet, RoBERTa这些模型中,WordPiece Emebeding的大小和hidden size的大小一致。这里来解释一下hidden size, 指的是transformer的encoder中的hidden size。即E=H
对于模型来时WordPiece Emebeding是学习上下文无关的表示,而hidden size则学习的是上下文有关的表示,后者明显更加复杂。因此正常情况下H应该是大于E的。但是随着H变大,正常情况下词汇表V是非常大的,如果E随着H增大,embedding matrix就会非常大。
文中提出了对Encoder层进行因式分解,打破了E和H之间的关系。具体的做法是将embedding matrix分解成了两个矩阵V*E和E*H,这样当H非常大的时候可以有效地降低embedding matrix的计算量。在代码中的体现则是在Encoder层中增加了embedding_hidden_mapping_in层,即增加了E*H的矩阵。使得Embedding层和Encoder层解除绑定。
class AlbertEncoder(nn.Module):
def __init__(self, config):
super(AlbertEncoder, self).__init__()
self.hidden_size = config.hidden_size
self.embedding_size = config.embedding_size
self.embedding_hidden_mapping_in = nn.Linear(self.embedding_size, self.hidden_size)
self.transformer = AlbertTransformer(config)
def forward(self, hidden_states, attention_mask=None, head_mask=None):
if self.embedding_size != self.hidden_size:
prev_output = self.embedding_hidden_mapping_in(hidden_states)
else:
prev_output = hidden_states
outputs = self.transformer(prev_output, attention_mask, head_mask)
return outputs # last-layer hidden state, (all hidden states), (all attentions)
跨层参数共享(Cross-layer parameter sharing)
为了提升模型的效率,论文提出了跨层参数共享机制。参数共享有三种方式:只共享feed-forward network的参数、只共享attention的参数、共享全部参数。Albert是默认共享全部参数的,后续实验结果会说明几种方式的模型的效果。
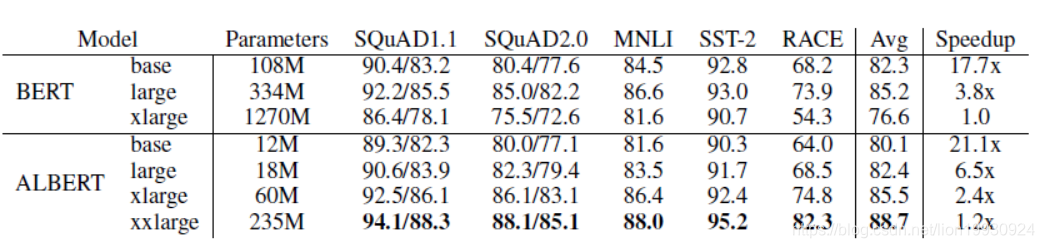
下图是Bert和Albert的模型参数对比,可以看出在同等规模的情况下Albert的参数数量比Bert要小很多,以base为例,Albert的参数数量为12M而Bert为108M,固然有共享参数的原因,上一个优化embedding matrix的分解也有贡献。

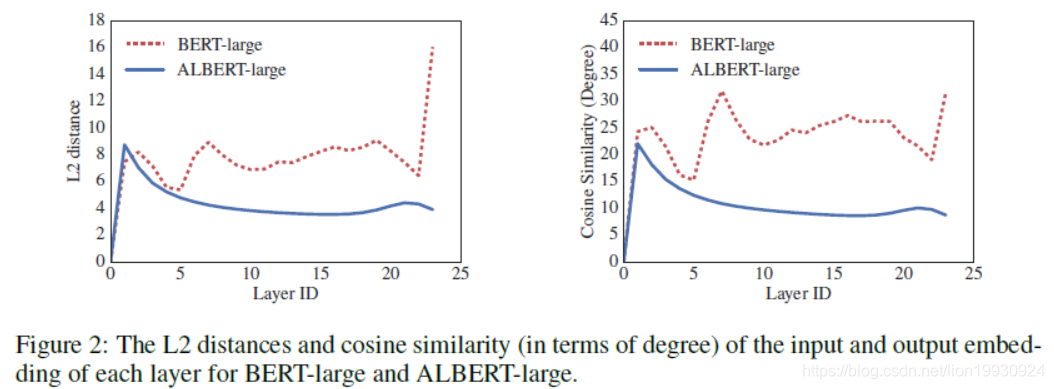
下图是Bert和Albert每一层的L2 Distance和cosine相似度,可以看到共享了参数的Albert在层和层之间的变化是非常平滑的。Albert的L2 Distance和cosine相似度也可以看出embedding的震荡比bert小,同时是在震荡而不是收敛,在24层之后并没有到0。这表示相比于Bert Albert具有更好的模型稳定性。
在Albert的源码中,模型的参数共享是通过modeling_utils中PreTrainedModel的_tie_or_clone_weights实现的。PreTrainedModel作为基类实现了_tie_or_clone_weights,他的子类在init_weight之后调用tie_weight实现参数共享。而tie_weight的核心就是_tie_or_clone_weights。
def _tie_or_clone_weights(self, first_module, second_module):
""" Tie or clone module weights depending of weither we are using TorchScript or not
"""
if self.config.torchscript:
first_module.weight = nn.Parameter(second_module.weight.clone())
else:
first_module.weight = second_module.weight
if hasattr(first_module, 'bias') and first_module.bias is not None:
first_module.bias.data = torch.nn.functional.pad(
first_module.bias.data,
(0, first_module.weight.shape[0] - first_module.bias.shape[0]),
'constant',
0
)
句间一致loss(Inter-sentence coherence loss)
Bert使用了NSP(next-sentence prediction)作为loss,NSP是一个二分类问题。训练的正样本是一个文档中连续的句子,负样本是不同文档中的句子。但是后续的研究发现NSP的效果并不可靠,主要原因是NSP的任务过于简单。
NSP主要包含了两个任务,主题预测和一致性预测,相比于一致性预测,主题预测更加简单,而且和MLM所学习的重叠了。因为正样本的来自同一文档中,而负样本来自不同的文档,例如前一句来自娱乐新闻,而后一句来自社会新闻,两句话不连贯,而且不是一个主题,差异性可能比较大。
MLM类似于完形填空,模型需要来预测MASKED的词。MLM的训练样本是连续的文本流,这些训练文本都是出自一个主题。这也是为什么和NSP有所重合的原因。
Albert关注句子的一致性问题,提出新的任务SOP(sentence-order prediction),正样本获取方法和Bert相同。负样本是将连续的句子互换顺序。这也使模型专注于句子连续性的预测。
模型效果
实验效果
下图是Albert的实验效果,可以看到同等规模下Albert的效果比Bert低2点。但是Albert xxlarge的效果要优于Bert。
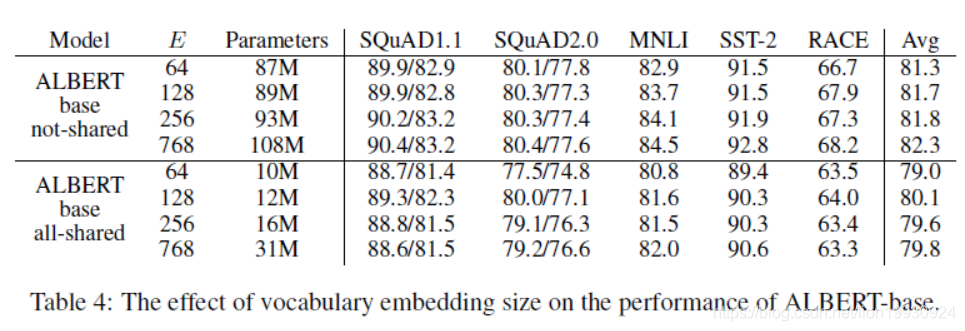
Emebdding因式分解(Factorized embedding parameterization)
对Embedding因式分解作者做了实验,发现不共享参数的效果优于共享参数的。并且随着WordPiece Emebeding size的增大而变好。但是这样参数的数量明显增多,增加了训练的时间。共享参数的效果在E=128时效果最好,这也是我们目前Albert的形态。
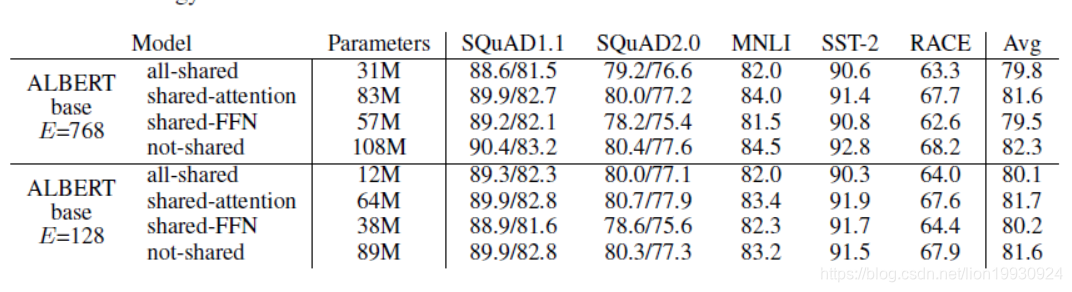
跨层参数共享(Cross-layer parameter sharing)
可以看出完全共享对模型的效果是有伤害的,在E=128时伤害效果小一点,在E=768时伤害效果较大。全部共享在E=128是效果伤害小一点,因此文中选择了完全共享。
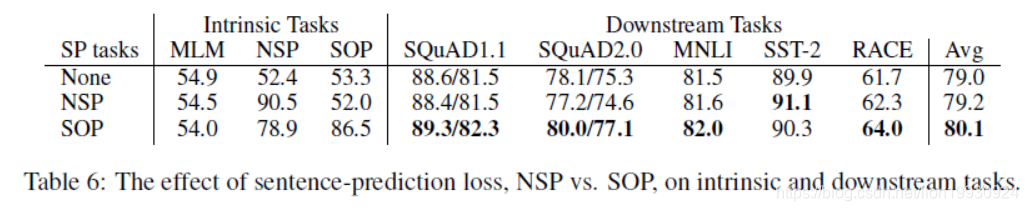
SOP任务
论文使用Albert的形式对各种任务的训练形式进行了尝试,发现在下游任务中SOP的效果最好。内部任务中NSP对SOP任务的正确率只有52%,而SOP对NSP的任务正确率有78.9%。说明NSP更加集中于对主题转换的学习,SOP可以覆盖大多数NSP的任务。
其他发现
同时文中发现在训练了100万步之后模型都没有过拟合,于是作者移除dropout发现对xxlarge的规模效果居然还有所提升。这应该是训练数据规模较大同时模型因为共享参数等操作降低参数规模导致的,在bert上的效果没有做过实验不得而知,不过我个人觉得可能和这个实验结果会有所区别。

相关链接
- Albert-Tensorflow: https://github.com/lonePatient/albert_pytorch
- Albert-Pytorch: https://github.com/lonePatient/albert_pytorch
- Albert:https://arxiv.org/pdf/1909.11942.pdf
