
Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
nlp.cs.washington.edu/denspi
Training takes 16 hours (64-GPU hours) and indexing takes 5 days (500 GPU-hours)
1.摘要
现有的开放域问答(QA)模型不适合实时使用,因为它们需要针对每个输入查询按需处理多个长文档。 在本文中,作者介绍了文档短语的与查询无关的可索引表示形式,它可以大大加快开放域质量检查的速度,还可以达到长尾目标。在SQuAD-Open上的实验表明,作者的模型比DrQA更精确,计算成本降低了6000倍,这意味着在CPU上的端到端推理基准至少快58倍。
2.介绍
open-domain QA 依赖第一阶段检索的文档质量。此外,在文档上应用阅读理解模型计算消耗巨大,比如一个BERT在NVIDIA P40 GPU上每秒只能处理上千个单词。
在本文中,作者引入了 Dense-Sparse 短语索引(DENSPI),一种用于实时开放领域问答的可索引的查询无关短语表示模型。短语表示使用memory-efficient和time-efficient的训练和存储进行离线索引。在推理过程中,输入问题被映射到相同的表示空间,并检索具有最大内积搜索的短语。
作者将短语表示结合Dense和Sparse 向量。Dense向量可有效利用BERT来编码局部句法和语义线索,而Sparse向量在编码精确词法信息方面更胜一筹。 文档短语和question的独立编码可实现实时推理; 无需为每个question重新编码文档。 根据短语的开始和结束标记对短语进行编码,可以使Wikipedia中多达600亿个短语的索引更容易实现。 而且,在可索引表示形式上的近似最近邻搜索允许在Web规模环境中进行快速直接检索。
为了学术环境下的再现性,作者讨论了在每个阶段减少时间和内存使用的优化策略。这使我们能够在一周内使用4-GPU、64GB内存、2 TB SATA SSD服务器完全部署该模型。
3.Overview
3.1 Problem Definition
给定一套wikipedia文档:{
x x x 1 ^1 1,…, x x x K ^K K} ( K K K经常是上亿的)
每个文档有 N N N个词{
x x x 1 _1 1 k ^k k,…, x x x N _N N k _k k k ^k k}
问题定义为对于给定的问题 q q q,根据{
x x x 1 ^1 1,…, x x x K ^K K} 找到答案 a a a
一个开放域 Q Q Q A A A模型是一个评分函数 F F F,用于每个候选短语跨度 x x x k ^k k i _i i : _: : j _j j,即:
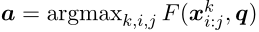
3.2 Encoding and Indexing Phrases
DENSPI模型对Wikipedia中text span的query-agnostic 表示进行编码,并通过在推理时执行最近邻搜索来实时获取答案。作者用dense向量和sparse向量来表示语料库(维基百科)中的每个短语跨度。密集向量对于编码句法和语义线索是有效的,而稀疏向量擅长编码精确的词汇信息。也就是说,文档 x x x k ^k k中每个跨度( i i i, j j j)的嵌入表示为:
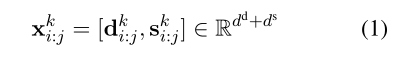
对于第 k k k个文档,dense向量表示为:
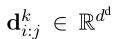
sparse向量表示为 S S S i _i i : _: : j _j j k ^k k ∈ ∈ ∈ R R R d ^d d s ^s s。
需要强调的是:
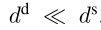
对所有文档执行预计算的短语索引操作,然后在推理的时候,把每个question嵌入到同一个向量空间:
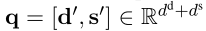
d ’ d^’ d’ 和 s ’ s^’ s’分别表示dense向量和sparse向量。
最后通过求 q q q和 x x x k ^k k i _i i : _: : j _j j之间的最大内积得到问题的答案:
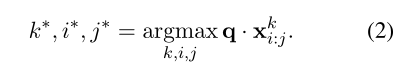
4 Phrase and Question Embedding
4.1 Dense Model
dense向量负责相对于其上下文对短语的句法或语义信息进行编码。作者将dense向量 d d d k ^k k i _i i : _: : j _j j(等式1)分解为三个分量:对应于短语开始位置的向量、对应于结束位置的向量和测量开始向量和结束向量之间一致性的标量值。将短语表示为起始向量和结束向量的函数允许我们有效地计算和存储向量,而不是枚举所有可能的短语。
一致性标量允许我们在推理过程中避免使用非构成短语。例如,考虑像“Barack Obama was the 44th President of the US. He was also a lawyer.” 这样的句子。当有一个问题“What was Barack Obama’s job?”。由于“44th President of the US”和“lawyer”这两个答案在技术上是正确的,如果我们独立地对向量的开始和结束进行建模,我们可能会得到从“44th”到“lawyer”的答案。一致性标量通过将其建模为起始位置和结束位置的函数来帮助我们避免这种情况。形式上,短语向量分解成dense和sparse后,我们可以把稠密向量展开成:
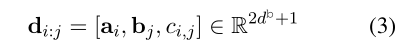
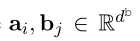
表示为文档中开始向量和结束向量
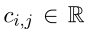
是一个位置标量,所以 d d d i _i i : _: : j _j j的最后维度为 2 2 2 d d d b ^b b + + + 1 1 1。下面将介绍这几个向量怎么获得:

首先,dense采用BERT获得:
对于输入token:{
x 1 x_1 x1,…, x N x_N xN}
输出: H H H=[ h 1 h_1 h1,…, h N h_N hN] ∈ ∈ ∈ R R R N ^N N × ^× × d ^d d。
然后从 H H H中获得三个dense分量。通过微调后,将 h i h_i hi分解成4个向量:
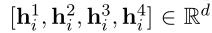
令: a i a_i ai = h h h 1 ^1 1 i _i i , b j b_j bj= h h h 2 ^2 2 j _j j c c c i _i i , _, , j _j j = h h h 3 ^3 3 i _i i ⋅ · ⋅ h h h 4 ^4 4 j _j j
其中·表示为向量内积。
4.2 Sparse Model
使用基于词频的编码来获取每个短语的稀疏嵌入 s s s k ^k k i _i i : _: : j _j j。 这里与DrQA相同,构造基于 2 2 2 − - − g g g r r r a a a m m m的 t t t f f f − - − i i i d d d f f f,从而导致每个文档的稀疏表示( d d d d ^d d≈16 M M M)。 对稀疏向量进行归一化,以便内积有效地变成余弦相似度。此外,作者还以类似方式计算段落级别的稀疏向量,并将其添加到每个文档稀疏向量中,以提高对本地信息的敏感性。 但是请注意,DrQA的稀疏向量仅用于检索几(5-10)个文档,本文将稀疏向量连接到密集向量以形成独立的单短语向量,如公式1所示。
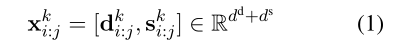
4.3 Question Embedding Model
在推理时,question同样被编码为: q q q =
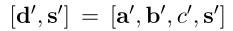
对于dense向量 d d d ’ ^’ ’
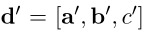
取[CLS]位置的输出即可: h h h 1 _1 1。所以给定一个question,直接通过取BERT的[CLS]输出得到dense向量 P ‘ P^‘ P‘:
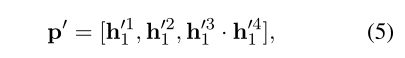
对于question的sparse向量,直接采用 t t t f f f − - − i i i d d d f f f获得。
5 Training, Indexing & Search
5.1 Training
给定question和dense phrase embeddings ,首先优化question和dense phrase的稠密表示:
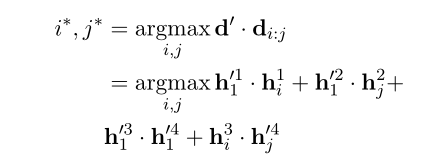
d d d ’ ^’ ’表示question的dense表示, d d d i _i i : _: : j _j j表示为dense phrase 的dense表示。(都用BERT,question取[CLS],dense phrase(理解为文档)取 H H H=[ h 1 h_1 h1,…, h N h_N hN])
然后令:
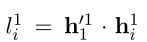
这个式子表示为phrase start logits(对应于优化目标的第一部分)
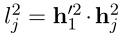
表示为phrase end logits(对应于优化目标的第二部分),然后令 l l l i _i i , _, , j _j j =
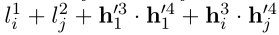
表示为要优化的最大值。
定义Loss的一个简单方法是将其定义为正确答案的负对数概率:
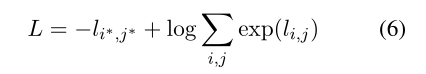
注:在训练期间显式地枚举所有可能的短语(枚举所有( i i i, j j j)对)将是内存密集型的。
No-Answer Bias
构造Train负例:相同文章中的不同passages(通过内积选择最大内积的passages)作为 hard negative examples,不同文章的passages作为 negative examples
技巧
- 为提升训练速度,文章借助矩阵运算进行批量训练;计算loss时改变运算次序,将部分指数运算转化为加和(见原文);
- 为降低索引phrase embedding所用的空间,同时提升检索phrase的速度,文章压缩phrase embedding的长度,丢弃冷门phrase,利用phrase的前缀后缀和指针优化检索过程;
- 文章提供了灵活的检索策略,包括dense-first search,sparse-first search,hybrid。在dense-first search策略中,也使用了faiss。
6 Experiments
data:SQuAD v1.1
结果:

(1) DENSPI大幅度优于查询agnostic基线,EM :20.1%,F1 :18.5%。这在很大程度上归功于BERT编码器的使用,它在顶部具有有效的短语嵌入机制。
(2) DENSPI优于DrQA EM :3.3% 。这意味着短语索引的模型现在可以胜过中早期最先进的模型。
(3) DENSPI比目前的技术水平低9.2%(BERT)。
(4)与查询相关的表示模型相比,查询无关的模型可以更快地处理(读取)单词。在一个受控的环境中,所有信息都在内存中,文档都是预先索引的,DENSPI每秒可以处理2870万字,比DrQA快6000倍,比BERT快563000倍,没有任何近似值。
消融

“s/Q”是CPU上每个查询的秒数,“D/Q”是每个查询访问的文档数。
BERTserini为在encoder上面加一个线性层,性能大幅度下降。
case study
看一下DENSOI的效果:

