
文章目录

在谷歌搜索谁是澳大利亚第三任总理,会得到一个答案,包含了图片和简介。这个答案不是直接从结构化数据中搜索得来的,而是从网页(图中是从维基百科)中抽取出来的。文本问答就是完成的就是这样的任务。
motivation
- 拥有大量的全文文档集合,例如网络,简单地返回相关文档的作用是有限的
- 相反,我们经常想要得到问题的答案
- 尤其是在移动设备上
- 或是使用像Alexa、Google assistant这样的数字助理设备。
- 我们可以把它分解成两部分
- 查找(可能)包含答案的文档
可以通过传统的信息检索/web搜索处理
(下个季度我将讲授cs276,它将处理这个问题) - 在一段或一份文件中找到答案
这个问题通常被称为阅读理解
这就是我们今天要关注的
- 查找(可能)包含答案的文档

A Brief History of Reading Comprehension
- 很多早期的NLP工作尝试阅读理解
Schank, Abelson, Lehnert et al. c. 1977 –“Yale A.I. Project” - 由Lynette Hirschman在1999年复活
NLP系统能回答三至六年级学生的人类阅读理解问题吗?简单的方法尝试 - Chris Burges于2013年通过 MCTest 又重新复活 RC
再次通过简单的故事文本的问答 - 2015/16年,随着大型数据集的产生,闸门开启,这些数据集可以建立监督神经系统
Hermann et al. (NIPS 2015) DeepMind CNN/DM dataset
Rajpurkaret al. (EMNLP 2016) SQuAD
MS MARCO, TriviaQA, RACE, NewsQA, NarrativeQA, …
Machine Comprehension (Burges 2013)
“一台机器能够理解文本的段落,对于大多数母语使用者能够正确回答的关于文本的任何问题,该机器都能提供一个字符串,这些说话者既能回答该问题,又不会包含与该问题无关的信息。”
MCTestReading Comprehension

A Brief History of Open-domain Question Answering (开放域问答)
- Simmons et al. (1964)首次探索了基于问答匹配依赖性分析的说明文问答
- Murax(Kupiec1993)旨在使用IR和浅层语言处理回答在线百科全书上的问题
- NIST TREC QA跟踪始于1999年,首先对大量文件的事实问题进行了严格调查
- IBM的危险!系统(DeepQA,2011)引起了对问答的关注;它使用了许多方法的集成
- DrQA(Chen等人。2016)使用信息检索和神经阅读理解,为开放领域质量保证带来深度学习
Turn-of-the Millennium Full NLP QA:
[architecture of LCC (Harabagiu/Moldovan) QA system, circa 2003] Complex systems but they did work fairly well on “factoid” questions

Stanford Question Answering Dataset (SQuAD)
(Rajpurkaret al., 2016)

100K个例子,答案必须实在文章中,即就是抽取型问答
SQuADevaluation, v1.1
-
作者搜集三个正确答案

-
将会在两个方法对系统打分
精确匹配:精确到1/0,取决于你的答案是否与三个标准答案之一匹配
F1:将系统和每个答案都视为词袋,并评估
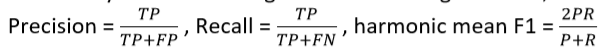
分数是(宏观)平均每题F1分数 -
F1测量被认为是更可靠的,作为主要指标使用
-
它不是基于选择与人类选择的完全相同的跨度,这很容易受到各种影响,包括换行
-
这两个指标忽视标点符号和冠词(a, an, the only)
SQuAD2.0
- SQuAD1.0的一个缺点是所有问题在段落中都有答案
- 系统(隐式)对候选进行排名并选择最佳答案
- 你不必判断一个span是否能回答这个问题
- 在SQuAD2.0中,1/3的训练集问题没有答案,1/2的开发集/测试集问题没有答案
- 对于No Answer examples, no answer 获得的得分为1,对于精确匹配和F1,任何其他响应的得分都为0
- SQuAD2.0最简单的系统方法
- 设置一个分数threshold来决定一个span是否回答了一个问题
- 或可设置第二个组件来确认是否是真的答案
- 类似 自然语言推理 或者 答案验证
- 例子

Good systems are great, but still basic NLU errors
得分高的系统很好,但依旧含有简单的自然语言理解问题

SQuADlimitations
- SQuAD 也有其他一些关键限制
- 只有 span-based 答案(没有 yes/no,计数,隐式的为什么)
- 问题是看着段落构造的
- 通常不是真正的信息需求
- 一般来说,问题和答案之间的词汇和句法匹配比IRL更大
- 问题与文章高度重叠,无论是单词还是句法结构
- 除了共同参照,几乎没有任何多事实/句子推理
- 不过这是一个目标明确,结构良好的干净的数据集
- 它一直是QA dataset上最常用和最具竞争力的数据集
- 它也是构建行业系统的一个有用的起点(尽管领域内数据总是很有帮助!)
- 并且我们正在使用它
一些QA系统
Stanford Attentive Reader
[Chen, Bolton, & Manning 2016] [Chen, Fisch, Weston & Bordes2017] DrQA [Chen 2018]
- 展示了一个非常成功的阅读理解和问答系统
- 后来被称为Stanford Attentive Reader
- 架构

问题:使用BiLSTM对问题进行编码,因为问题较短,所以只使用正向和反向得到的编码,对其进行拼接得到问题的最终表示

文章:同样使用BiLSTM对文章进行编码,因为文章较长,不能只使用RNN最后一个时间步来表示(seq2seq中提到的信息瓶颈问题),而是使用每个词的隐藏状态表示,将正反向拼接起来就得到了文章的最终表示,如下式所示
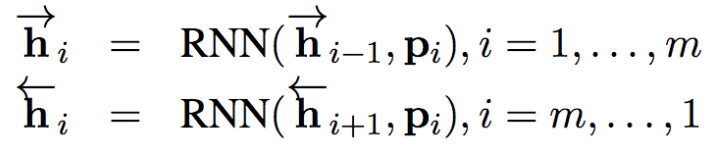
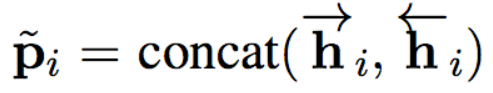
问题和文章的交互(attention层):这一层通过使用注意力机制,来获取文章中的哪些词对于问题更加重要。文章表示就相当于我们之前提到的value,问题表示相当于query。以下为计算公式, 为本层输出,即文章和问题的最终表示。
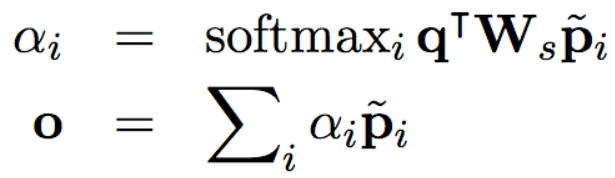
根据我们之前所学的注意力机制,我们可以知道,这里使用了第二种计算注意力分数的方法
预测层:直接使用softmax求解答案起始位置和结束位置。如下式
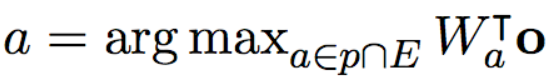
细节请看解析博客:https://www.imooc.com/article/28801
Stanford Attentive Reader++


问题部分:
- 不再使用BiLSTM最后的隐藏状态,而是每个词隐藏状态的加权和(类似于self-attention的weighted sum)
- 采用了更深的BiLSTM(3层最好)
文章部分: - 依旧采用每个词的嵌入来表示
- 不过嵌入发生了改变,由以下几部分组成
- 词嵌入(GloVe300d)
- 语言学特征:如POS(part of speech)和NER(named entity recognition) tag
- term frequency (unigram probability)
- 精确匹配:词是否在问题中出现
- 又分为三种即exact match, uncased match(不区分大小写), lemma match(如drive和driving)
- aligned question embedding
与exact match相比,这可以看做是对于相似却不完全相同的单词(如car与vehicle)的soft alignment
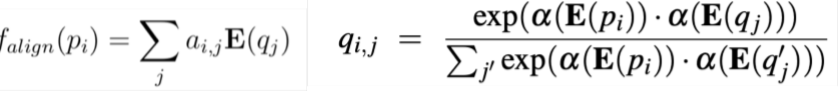
右边的式子有错误,应该求的是 ,表示文章中单词 与问题中单词 的相似度, 是一层简单的FFNN


BiDAF: Bi-Directional Attention Flow for Machine Comprehension
(Seo, Kembhavi, Farhadi, Hajishirzi, ICLR 2017)

BiDAF的核心思想在于the Attention Flow layer
- 注意力应该是双向的,既有从Context(即passage)到Query(即Question)的attention,又有从Query到Context的attention。
- 首先计算相似矩阵
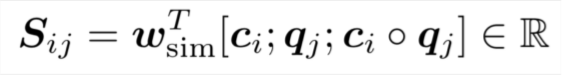
其中 分别代表context vector与query vector。求得的 表示 的相似度值,为一个实数。 的维度为6d(每个向量维度为2h,因为是双向拼接,所以是2h,有三个向量拼接在一起(分号表示拼接),所以是6h) - 然后计算Context-to-Question (C2Q) attention,即对于每个context word,哪些query words更相关,计算结果为用query words词向量表示context word,即对所有query words词向量求一个加权和,权值为注意力分布。
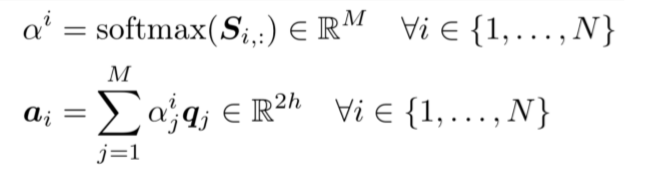
注意这里的符号与架构图中的符号不太一样,其中 相当于图中的 表示问题的单词数目, 相当于图中的 ,表示文章的长度。 - Question-to-Context (Q2C) attention:
关于query,求文章中最重要词的加权和,这里只用一个向量表示整个问题,故对每列求了最大值,然后使用siftmax求文章中每个词的权值。

- 该层最终的输出为
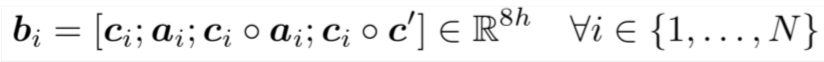
分号表示向量拼接,其中 :文章中第i个词的词向量, :文章中第i个词关于问题的注意力表示, 表示问题的注意力表示
更加详细的解释看博客:https://zhuanlan.zhihu.com/p/53626872
- modeling layer
将上一层的输入经过一个2层的BiLSTM编码 - answer span selection更加复杂
- Start:通过BiDAF 和 modelling 的输出层连接到一个密集的全连接层然后softmax
- End:把 modelling 的输出 通过另一个BiLSTM得到 ,然后再与BiDAF layer连接,并通过密集的全连接层和softmax
Recent, more advanced architectures
- 2016年、2017年和2018年的大部分工作都采用了越来越复杂的架构,并有许多不同的注意力机制,通常会带来良好的任务收益
Dynamic Coattention Networks for Question Answering
(CaimingXiong, Victor Zhong, Richard Socher ICLR 2017)
- 缺陷:问题具有独立于输入的表示
- 一个全面的QA模型需要相互依赖

CoattentionEncoder

- 首先得到文章P和问题Q的编码,然后计算相关性矩阵,对其进行softmax分别得到question里面每一个词和passage里面每一个词的attention分数 和passage里面的每一个词和question的attention分数 。然后计算经过attention的问题的新表示 ,将问题的源编码矩阵 和经过attention的新表示 拼接在一起,然后根据 计算文章的新表示得到 ,将 和 拼接在一起,最后经过BiLSTM得到最终的文章和问题的表示。
- 详细过程见博客:https://blog.csdn.net/chazhongxinbitc/article/details/78825704
- 使用了双层注意力机制,将第一层注意力的输出作为第二层注意力的输入。
- 这样做的好处,我的观点是:经过两层注意力,获取了更多了文章和问题之间的联系。
- 在SQUAD上的表现

- SQUAD最近的结果:https://rajpurkar.github.io/SQuAD-explorer/
FusionNet(Huang, Zhu, Shen, Chen 2017)
- Attention functions
- MLP (Additive) form:
space: is kxd - Bilinear (Product) form:
空间小,非线性
空间:$O((m+n)k)
- MLP (Additive) form:
- FusionNet tries to combine many forms of attention**

- Multi-level inter-attention

经过多层inter-attention,使用RNN,自注意力和 另一个RNN来获得context的最终表示:

ELMo and BERT preview
-
使用类似语言模型的目标函数的上下文单词表示

-
transformer:(Vaswani et al, 2017)
-
DrQA: Open-domain Question Answering
(Chen, et al. ACL 2017) https://arxiv.org/abs/1704.00051

-
Document Retriever

-
General questions
结合网络搜索,DrQA可以正确回答57.5%的琐碎问题总结
-
QA的历史
-
开放域QA的步骤:1.找到包含答案的一份文件或一段文本 2.从文本中找到答案
-
数据集:SQUAD1.1 和 SQUAD 2.0
-
一些架构:
- Stanford Attentive Reader:文章和问题编码,然后使用注意力获得两者语义联系,最后找出答案
- Stanford Attentive Reader++:文章表示更加复杂,结合了多个特征。使用了更深的网络
- BiADF:引入双向注意力
- DCN:使用双向两层注意力
- FusionNet:多层注意力
-
ELMo和BERT:类似语言模型的上下文的词表示
