摘要
我们针对诸如语法错误校正(GEC)之类的任务中出现的局部序列转换问题,提出了并行迭代编辑(PIE)模型。最近的方法是基于流行的编解码器(ED)模型进行序列到序列学习的。ED模型自回归地捕获输出字符之间的完全依赖关系,但由于顺序解码的特性导致较慢的解码速度。PIE模型进行并行解码,放弃了对输出中的完全依存关系进行建模的优势,但由于以下四个原因,其与ED模型相比具有很高的准确性:1.预测编辑而不是字符; 2.标记序列而不是生成序列; 3.迭代地完善预测以捕获依赖性,4.通过编辑将logits分解为因数及其字符参数,以利用诸如BERT之类的经过预训练的语言模型。在涵盖GEC,OCR校正和拼写校正的任务上进行的实验表明,PIE模型是局部序列转换任务中准确且明显更快的替代方法。可在https://github.com/awasthiabhijeet/PIE上找到GEC的代码和预训练模型。
1.介绍
在局部序列转换(LST)中,需要将输入序列 x 1 , . . . , x n x_1,...,x_n x1,...,xn映射到输出序列 y 1 , . . . , y m y_1,...,y_m y1,...,ym,其中 x x x和 y y y序列仅在几个位置上不同,且 m m m接近 n n n,并且 x i , y j x_i,y_j xi,yj来自相同的词表 Σ Σ Σ。我们在本文中重点介绍的局部序列转换的重要应用是语法错误纠正(GEC)。我们将局部转换与更通用的序列转换任务(例如翻译和释义)进行对比,这些任务可能需要不同的输入输出词汇和非局部比对。一般序列转换任务被定义为序列到序列(seq2seq)学习,并广泛使用注意力编码器-解码器(ED)模型进行建模。ED模型以所有先前字符 y 1 , . . . , y t − 1 y_1,...,y_{t-1} y1,...,yt−1为条件,自回归生成输出序列中的每个字符 y t y_t yt。由于该模型在诸如翻译等具有挑战性的任务中取得了巨大成功,因此几乎所有GEC的最新神经模型都使用了它。
我们重新审视了局部序列转换任务,并提出了一种新的并行迭代编辑(PIE)架构。与以受约束地在输出中顺序生成字符的流行ED模型不同,PIE模型并行生成输出,从而大大减少了长输入上顺序解码的延迟。然而,在不具备条件生成能力的情况下,达到与现有ED模型相当的准确性是非常具有挑战性的。最近,在翻译和语音合成等任务中也探索了并行模型 ,但其准确性明显低于相应的ED模型。PIE模型结合了以下四个思想,即使并行解码,也可以在GEC之类的任务上实现可比的准确性。
1.输出编辑而不是字符:首先,不是输出具有大词汇量的字符,而是输出诸如复制,追加,删除,替换和大小写更改之类的编辑,这些编辑可以更好地概括标记并产生更小的词汇量。假设在GEC中我们有一个输入语句: f o w l e r f e d d o g fowler~fed~dog fowler fed dog。现有的seq2seq学习方法将需要从词汇表中输出四个字符 F o w l e r , f e d , t h e , d o g Fowler,fed,the,dog Fowler,fed,the,dog,而我们将预测编辑 { C a p i t a l i z e t o k e n 1 , A p p e n d ( t h e ) t o t o k e n 2 , C o p y t o k e n 3 } \{Capitalize~token~1, Append(the)~to~token~2,Copy~token~3\} {
Capitalize token 1,Append(the) to token 2,Copy token 3}。
2.序列标注而不是序列生成:第二,我们对源字符执行局部编辑,并在使用编辑命令来标记输入字符,而不是解决涉及单独解码器和注意力的难度更大的整个序列生成任务。由于输入和输出长度通常是不同的,因此这种形式是不容易实现的,特别是由于插入单词的编辑。我们创建了特殊的组合编辑,将字符插入操作与之前的字符合并在一起,比以前的独立预测插入项的方法产生的准确性更高。
3.迭代细化:第三,我们通过迭代输入模型自己的输出以进一步细化来提高并行模型的推理能力。这以隐式方式处理依赖关系,其方式使人联想到图形模型推断中的迭代条件模式(ICM)和 Ge et al. (2018b)也使用ED模型进行迭代改进。
4.分解预训练的双向LM:最后,我们通过在编辑命令及其字符参数上分解logit层,来适应最近的预训练双向模型,例如BERT。现有的GEC系统通常依靠传统的前向LM来预训练其解码器,而我们展示了如何在编码器中使用双向LM,以及如何预测编辑。
我们工作的主要贡献如下:
- 将GEC视为局部序列转换(LST)问题,而不是机器翻译。然后,相对于现有的自回归编码器/解码器模型,我们将LST转换为快速的非自回归,序列标注模型。
- 我们将LST定义为非自回归序列标注的方法具有许多新的元素:输出编辑操作而不是字符,APPEND操作而不是在编辑空间中INSERT,以及使用自定义转换来替换。
- 我们展示了如何使用我们的分解logit架构以及特定于编辑的注意力MASK来有效利用像BERT这样的预训练语言模型。
- PIE中的并行推理比基于ED的GEC模型要快5至15倍,后者使用集束搜索执行顺序解码。在标准GEC数据集上,PIE的性能也接近最先进的水平。在其他两个局部转换任务(即OCR和拼写更正)上,PIE模型同样快速准确。
2.方法
我们假设有一个完全监督的训练环境,其为我们提供了不正确到正确序列的平行数据集: D = { ( x i , y i ) : i = 1... N } D=\{(x^i,y^i):i=1...N\} D={
(xi,yi):i=1...N},以及可选的正确序列的大型语料 L = { y ~ 1 , . . . , y ~ U } \mathcal L=\{\tilde y^1,...,\tilde y^U\} L={
y~1,...,y~U}。在GEC中,这可能是用于对语言模型进行预训练的语法正确的语料库。
现有的seq2seq ED模型将 P r ( y ∣ x ) Pr(\textbf y|\textbf x) Pr(y∣x)分解为 ∏ t = 1 m P r ( y t ∣ y < t , x ) \prod^m_{t=1}Pr(y_t|y_{<t},\textbf x) ∏t=1mPr(yt∣y<t,x),以捕获 y t y_t yt与所有先前 y < t = y 1 , . . . , y t − 1 y_{<t}=y_1,...,y_{t-1} y<t=y1,...,yt−1之间的完全依赖关系。编码器将输入字符 x 1 , . . . , x n x_1,...,x_n x1,...,xn转换到上下文状态 h 1 , . . . , h n \textbf h_1,...,\textbf h_n h1,...,hn,解码器则将 y < t y_{<t} y<t汇总为状态 s t \textbf s_t st。从 s t s_t st计算出的上下文状态的注意力分布确定了相关的输入上下文 c t \textbf c_t ct,而输出字符分布的计算公式为 P r ( y t ∣ y < t , x ) = P r ( y t ∣ c t , s t ) Pr(y_t|y_{<t},\textbf x)=Pr(y_t|c_t,s_t) Pr(yt∣y<t,x)=Pr(yt∣ct,st)。使用波束搜索顺序进行解码。当有正确的序列语料库 L \mathcal L L可用时,对解码器进行下一字符预测损失的预训练和/或使用经过训练的LM对波束搜索输出进行重新排序。
2.1 PIE模型综述
我们从使用单独的解码器在输出序列 y y y中生成字符,过渡到使用编辑 e 1 , . . . , e n e_1,...,e_n e1,...,en来标记输入序列 x 1 , . . . , x n x_1,...,x_n x1,...,xn。为此,我们需要设计一个函数Seq2Edits,该函数将 D D D中的 ( x , y ) (\textbf x,\textbf y) (x,y)对作为输入,并从编辑空间 E \mathcal E E输出编辑序列 e \textbf e e,其中尽管 x \textbf x x和 y \textbf y y具有不同的长度,但是 e \textbf e e与 x \textbf x x的长度相同。在2.2节中,我们展示了如何设计这样的函数。
(1)训练
我们在 D D D上调用Seq2Edits并学习概率模型 P r ( e ∣ x , θ ) Pr(\textbf e|\textbf x,θ) Pr(e∣x,θ)的参数,以对输入序列中的每个字符赋予编辑标签分布。在2.3节中,我们将更详细地描述PIE体系结构。正确的语料库 L \mathcal L L(如果可用)用于对编码器进行预训练,以预测 L \mathcal L L中序列 y \textbf y y中的任意mask字符 y t y_t yt,就像在BERT中一样。与现有的seq2seq系统不同,在现有的seq2seq系统中, L \mathcal L L用于预训练仅捕获前向依赖性的解码器,而在我们的预训练中,预测字符 y t y_t yt既依赖于前向上下文,也依赖于后向上下文。这对于未来上下文 y t + 1 . . . y m y_{t+1}...y_m yt+1...ym的GEC类型任务特别有用。
(2)推理
给定输入 x \textbf x x时,训练后的模型会预测每个输入字符的编辑分布,而与其他字符无关,即 P r ( e ∣ x , θ ) = ∏ t = 1 n P r ( e t ∣ x , t , θ ) Pr(\textbf e|\textbf x,θ)=\prod^n_{t=1}Pr(e_t|\textbf x,t,θ) Pr(e∣x,θ)=∏t=1nPr(et∣x,t,θ),因此不需要ED模型的顺序生成字符所带来的延迟。我们输出最可能的编辑 e ^ = a r g m a x e P r ( e ∣ x , θ ) \hat \textbf e=argmax_ePr(\textbf e|\textbf x,θ) e^=argmaxePr(e∣x,θ)。通过设计较好的编辑空间,以便在对 x \textbf x x应用 e ^ \hat \textbf e e^之后可以轻松获得已编辑序列 y ^ \hat \textbf y y^。通过将模型迭代应用到生成的输出 y ^ \hat \textbf y y^上,来进一步细化 y ^ \hat \textbf y y^,直到得到与先前序列之一相同的序列或最大迭代次数 I I I。
2.2 Seq2Edits函数

给定 x = x 1 , . . . , x n \textbf x=x_1,...,x_n x=x1,...,xn和 y = y 1 , . . . , y m \textbf y=y_1,...,y_m y=y1,...,ym,其中 m m m可能不等于 n n n,我们的目标是获得一系列编辑操作 e = ( e 1 , . . . , e n ) : e i ∈ E e=(e_1,...,e_n):e_i∈\mathcal E e=(e1,...,en):ei∈E,从而能够在每个位置 i i i上对输入字符 x i x_i xi应用编辑 e i e_i ei来重建输出序列 y \textbf y y。在 x \textbf x x和 y \textbf y y之间调用现成的编辑距离算法可以为我们提供一系列任意长度的复制,删除,替换和插入操作。主要困难是将插入操作转换为每个 x i x_i xi的就地编辑。其他并行模型使用了诸如在预处理步骤中预测插入插槽,或在 x \textbf x x任意两个字符之间预测零个或多个字符的方法。我们将在第3.1.4节中看到,这些效果不佳。因此,我们设计了一个替代的编辑空间 E \mathcal E E,它将插入内容与之前的编辑操作合并,从而创建复合的追加或替换操作。此外,我们创建了在训练数据中观察到的常见q-gram插入或替换的字典 Σ a Σ_a Σa。
我们的编辑空间( E \mathcal E E)包括 c o p y ( C ) x i copy(C)~x_i copy(C) xi, d e l e t e ( D ) x i delete(D)~x_i delete(D) xi,在 c o p y ( C ) x i copy(C)~x_i copy(C) xi之后 a p p e n d ( A ) q − g r a m w ∈ Σ a append(A)~q-gram~w∈Σ_a append(A) q−gram w∈Σa,用 q − g r a m w ∈ Σ a r e p l a c e ( R ) x i q-gram~w∈Σ_a~replace(R)~x_i q−gram w∈Σa replace(R) xi。对于GEC,我们另外使用表示为 T 1 , . . . , T k T_1,...,T_k T1,...,Tk的变换进行单词变形(例如 a r r i v e arrive arrive到 a r r i v a l arrival arrival)。因此,所有的编辑空间为:
E = { C , D , T 1 , . . . , T k } ∪ { A ( w ) : w ∈ Σ a } ∪ { R ( w ) : w ∈ Σ a } (1) \mathcal E=\{C,D,T_1,...,T_k\}\\ \cup \{A(w):w\in Σ_a\}\\ \cup \{R(w):w\in Σ_a\}\tag{1} E={
C,D,T1,...,Tk}∪{
A(w):w∈Σa}∪{
R(w):w∈Σa}(1)
我们提出了使用图1中的上述编辑空间将序列 x \text x x和 y \textbf y y转换为 x \textbf x x对应编辑的算法。表1给出了将 ( x , y ) (x,y) (x,y)对转换为编辑序列的示例。我们首先调用Levenshtein距离算法,以通常的删除和插入获得 x x x和 y y y之间的差异,然后使用一个修改后的替代从而有利于相关单词的匹配。我们在附录中详细介绍了此修改,并举例说明了此修改如何导致更明智的编辑。对diff进行后处理,以将替换转换为删除,对于插入,将连续的插入合并为q-gram。然后,我们在训练集中创建 M M M个最常见q-gram插入的字典 Σ a Σ_a Σa。之后,我们从左到右扫描diff: x i x_i xi处为copy则 e i = C e_i=C ei=C, x i x_i xi处为delete则 e i = D e_i=D ei=D, x i x_i xi处为插入 w w w,如果 w w w在 Σ a Σ_a Σa中则为 e i = A ( w ) e_i=A(w) ei=A(w),否则 e i = C e_i=C ei=C,如果在 x i x_i xi处插入 w w w,并且 e i = D e_i=D ei=D,则将 e i e_i ei翻转为 e i = T ( w ) e_i=T(w) ei=T(w)(如果找到匹配项),否则使用 R ( w ) R(w) R(w)(如果 w w w在 Σ a Σ_a Σa中),否则它被丢弃。

上面的算法不能保证当在 x x x上应用 e e e时,我们将为训练数据中的所有序列恢复 y y y。这是因为我们限制 Σ a Σ_a Σa仅包括 M M M个最频繁插入的 q − g r a m q-gram q−gram。对于局部序列转换任务,我们希望很少有连续插入的长序列,因此我们的实验是用 q = 2 q=2 q=2进行的。例如,在NUCLE数据集中,大约有57.1K个句子,其中有少于3%的句子连续插入了三个或更多的字符。
2.3 并行编辑预测模型
接下来,我们描述在输入序列 x : x 1 , . . . , x n \textbf x:x_1,...,x_n x:x1,...,xn上用于预测编辑 e : e 1 , . . . , e n \textbf e:e_1,...,e_n e:e1,...,en的模型。我们使用双向编码器来提供每个 x i x_i xi的上下文编码。 这可以是多层双向RNN,CNN,也可以是深层双向transformers。我们采用深度双向transformers架构,因为它可以并行编码输入。我们使用 L \mathcal L L对模型进行预训练,就像最近针对语言模型提出的BERT预训练一样。我们首先介绍BERT,然后描述我们的模型。
背景:BERT。输入是序列 x \textbf x x中每个字符 x i x_i xi的词嵌入 x i \textbf x_i xi和位置嵌入 p i \textbf p_i pi。将他们共同表示为 h i 0 = [ x i , p i ] \textbf h^0_i=[\textbf x_i,\textbf p_i] hi0=[xi,pi]。每一层 l l l在每个位置 i i i处都产生 h i l h^l_i hil,它是 h i l − 1 \textbf h^{l-1}_i hil−1和在所有 h j l − 1 , j ∈ [ 1 , n ] \textbf h^{l-1}_j,j∈[1,n] hjl−1,j∈[1,n]上的自注意力的函数。通过使用特殊的MASK屏蔽掉一小部分输入字符,并从最后一层输出的双向上下文 h 1 , . . . , h n h_1,...,h_n h1,...,hn中预测被屏蔽的单词,可以对BERT模型进行预训练。
2.3.1 BERT的默认使用
由于我们已将我们的任务转换为序列标注任务,因此默认的输出层将是计算每个 h i \textbf h_i hi的编辑空间 E \mathcal E E上的 P r ( e i ∣ x ) Pr(e_i|\textbf x) Pr(ei∣x)作为softmax。如果 W e W_e We表示用于编辑 e e e的softmax参数,则得到:
P r ( e i = e ∣ X ) = s o f t m a x ( W e T h i ) (2) Pr(e_i=e|\textbf X)=softmax(W^T_e \textbf h_i)\tag{2} Pr(ei=e∣X)=softmax(WeThi)(2)
方程2中的softmax参数 W e W_e We必须从头开始进行训练。我们提出一种方法,利用预训练语言模型的字符嵌入来热启动与字符参数相关联的诸如 A P P E N D APPEND APPEND和 R E P L A C E REPLACE REPLACE之类编辑的训练。此外,对于 A P P E N D APPEND APPEND和 R E P L A C E REPLACE REPLACE,我们提供了一种通过替代输入位置嵌入和自我关注来计算隐藏层输出的新方法。我们这样做没有在BERT的隐藏层中引入任何新参数。
2.3.2 编辑分解的BERT架构
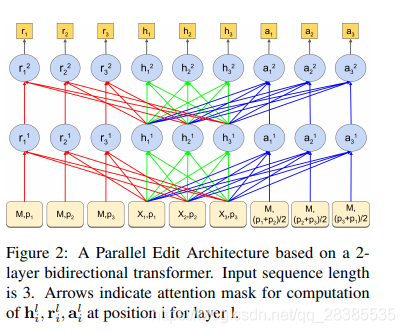
我们采用预训练的类似BERT的双向语言模型来学习预测如下的编辑。为了适当地捕获 R E P L A C E REPLACE REPLACE编辑的上下文,对于每个位置 i i i,我们创建一个包含 r i 0 = [ M , p i ] \textbf r^0_i=[M,\textbf p_i] ri0=[M,pi]的附加输入,其中 M M M是LM中MASK字符的嵌入。同样,对于 i i i和 i + 1 i+1 i+1之间的 A P P E N D APPEND APPEND操作,我们创建输入 a i 0 = [ M , p i + p i + 1 2 ] \textbf a^0_i=[M,\frac{p_i+p_{i+1}}{2}] ai0=[M,2pi+pi+1],其中第二个分量表示第 i i i个和第 i + 1 i+1 i+1个位置的位置嵌入的平均值。如图2所示,对于所有 j ≠ i j\neq i j=i,我们在每一层 l l l上计算第 i i i个 R E P L A C E REPLACE REPLACE单元 r i l \textbf r^l_i ril在 h j l \textbf h^l_j hjl上及其自身的自注意力,对于 A P P E N D APPEND APPEND单元 a i l \textbf a^l_i ail也是如此。在最后一层,我们有 h 1 , . . . , h n , r 1 , . . . , r n , a 1 , . . . , a n \textbf h_1,...,\textbf h_n,\textbf r_1,...,\textbf r_n,\textbf a_1,...,\textbf a_n h1,...,hn,r1,...,rn,a1,...,an,使用这些,我们计算因编辑及其字符参数而分解的logits。对于位置 i i i处的编辑 e ∈ E e∈\mathcal E e∈E,令 w w w表示编辑的参数(如果有)。如前所述, w w w可以是 A P P E N D APPEND APPEND和 R E P L A C E REPLACE REPLACE编辑的q-gram。通过对w中的字符的各个输出嵌入求和来获得 w w w的嵌入,用 φ ( w ) φ(w) φ(w)表示。此外,在外层,我们分配与 E \mathcal E E中每个不同命令相对应的特定于编辑的参数 θ θ θ。使用这些参数,可以按以下方式计算各种编辑logit:
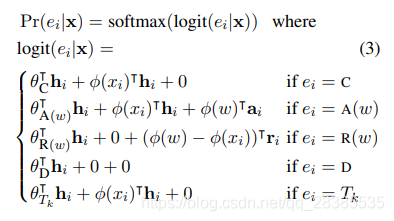
以上等式的RHS中的第一项记录编辑特定分数。第二项捕获将当前单词 x i x_i xi复制到输出的分数。第三项模拟了新的字符在替换或追加编辑获得的输出中的影响。对于替换编辑,从输入单词的分数中减去替换单词的分数。对于转换,我们添加复制分数,因为它们通常仅修改单词形式,因此我们不希望转换后的单词的含义发生显着变化。
上面的等式提供了关于为什么预测独立编辑比预测独立字符更容易的见解。考虑 A P P E N D APPEND APPEND编辑( A ( w ) A(w) A(w))。与其独立预测 i i i和 i + 1 i+1 i+1处的 x i x_i xi,我们不如共同预测这两个时刻中的字符,并与在单个softmax中的 x i x_i xi之后不插入任何新w$进行对比。我们将通过经验证明(第3.1.4节),尽管进行了并行解码,但这种选择性联合预测仍是获得高精度的关键。