7.1.1 简介
改论提出了一系列基于长短期记忆(LSTM)的序列标注模型。包括LSTM,BI-LSTM,LSTM-CRF和BI-LSTM-CRF,是首次将双向的LSTM CRF(简称BI-LSTM-CRF)模型应用于NLP基准序列标记数据集。论文中证明,由于双向LSTM组件,bilsm - crf模型可以有效地利用过去和未来的输入特性。由于CRF层,它还可以使用句子级别的标记信息。
7.2.2 LSTM
LSTM是一个可以记住上下文的RNN结构,RNN简单结构图如下:
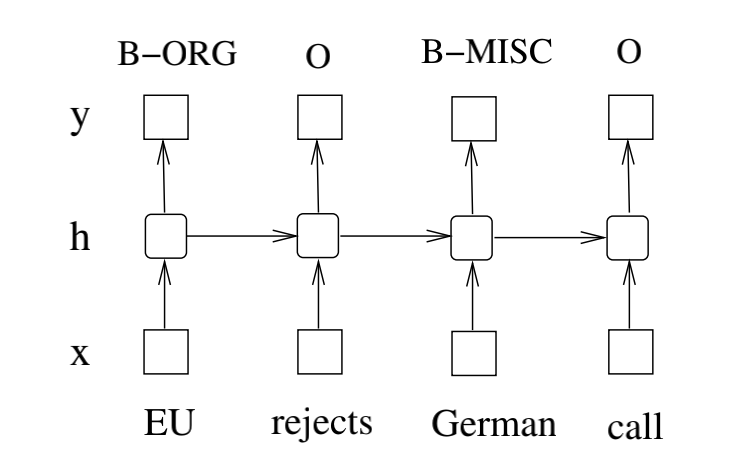
上图展示了RNN的结构,由输入层 x,隐藏层 h 以及输出层 y 组成。在命名实体标注的上下文中,x 表示输入特征而 y 表示标签。图1展示的命名实体识别系统中,每一个单词都标注为其他(O)或者四种实体类型(人名 - PER,地名 - LOC,组织机构 - ORG,杂项 - MISC)中的一个。句子 EU rejects German call to boycott British lamb. 被标注为B-ORG,O,B-MISC,O,O,O,B-MISC,O,O,。其中前缀 B- 和 I- 表示每一个实体的开始和中间的位置。
一个输入层表示时刻 t 的特征。可能是基于独热编码的词特征,密集的特征向量或者稀疏向量。输入层的维度与应当与特征的大小相等。一个输出层表示在时刻 t ,标签取值的概率分布。输出层的维度与标签数量大小相等。与前馈神经网络相比,RNN引入了上个隐藏状态与当前隐藏状态的连接(因而产生了循环层的权重参数)。这种循环层是设计用来保存历史信息的。隐藏层和输出层的值是通过下面的方式进行计算的:

U,W 以及 V 就是在训练时刻被计算的连接权重,并且 f(z) 和 g(z) 是 sigmoid 和 softmax 激活函数:
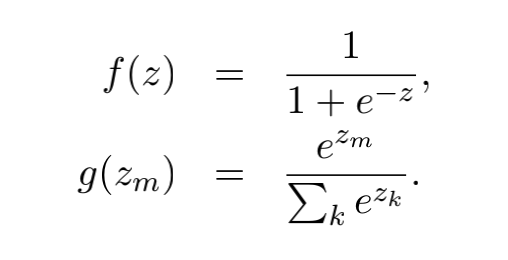
本文中,应用长短时记忆网络(Long Short-Term Memory)进行序列标注。LSTM 网络和 RNNs 一样,除了隐藏层的更新模块被专门构建的记忆细胞所取代。其结果就是,LSTM能够更好的发现和探索数据中长范围的依赖信息。下图展示了一个LSTM记忆细胞(cell)。

LSTM的记忆细胞是通过下面的公式实现:

其中 σ 是逻辑 sigmoid 函数,以及i,f, o 和 c 分别是输入门,遗忘门,输出门和细胞向量,所有这些都与隐藏向量 h 的大小相同。权重矩阵下标的含义与名称是等价的。举个例子,是隐藏 - 输入门矩阵,是输入 - 输出门矩阵。从细胞(cell)到门(gate)向量的权值矩阵是对角矩阵,因此,每一个门向量中的元素 m 只接受来自于细胞向量元素m 的输入。
下图展示了一个LSTM网络:
7.2.3 双向 LSTM 网络
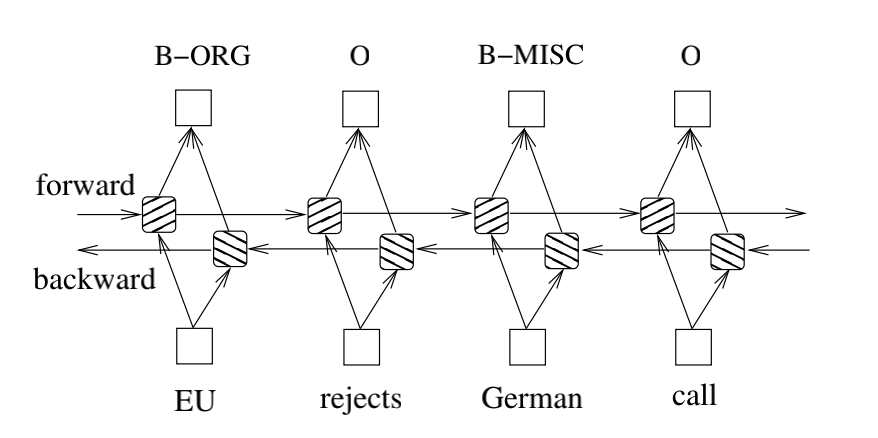
在序列标注任务中,需要在给定时间访问过去或未来的输入特征,因此可以利用双向 LSTM 网络。这样做,能够在指定的时间范围内有效地使用过去的特征(通过前向状态)和未来的特征(通过后向的状态)。可以使用通过时间的反向传播(BPTT)来训练双向LSTM网络。随着时间推移,在展开的网络上进行的前向和后向传递同常规网络中的前向和后向传递方式类似,论文中除了需要对所有的时间步骤展开隐藏状态。还需要在数据点的开始和结束时进行特殊的处理。在论文的实现中,对整个句子进行前向扫描和后向扫描的时候仅仅需要在句子的开头将隐藏状态重置为0。通过做了批量的实现,证明这使得多个句子可以同时被处理。
下图为双向神经网络结构图:

7.2.4 LSTM-CRF 网络
我们将LSTM网络和CRF网络整合成为LSTM-CRF模型,如下图所示。通过LSTM层,这个模型可以有效的利用过去的输入特征,通过CRF层,模型可以有效的利用句子级的标签信息。CRF层由连接连续输出层的线条表示。CRF层具有一个状态转移矩阵作为参数。利用这样的一个层,我们可以有效地利用过去和未来的标签来预测当前的标签,这类似于双向LSTM网络能够利用过去和未来的输入特征。我们将分数矩阵看做是网络的输出。我们丢弃输入来简化计数。矩阵携带θ的元素是网络输出的关于句子中第 t 个词的第 i 个标签的分数。我们引入转换分数来模拟一对连续的时间步长从第 i 个状态到第 j 个状态的转换。注意,这个转移矩阵与位置无关。现在我们来看看网络的新参数。然后,通过转移分数和网络分数的总和给出句子的分数以及标签的路径: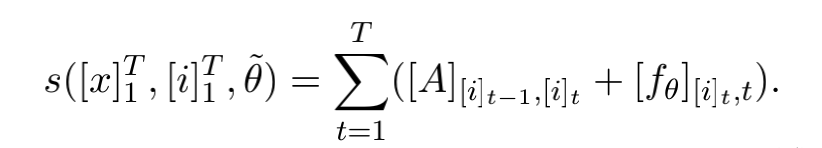
动态编程可以有效地用于计算和最佳标签的推理序列。
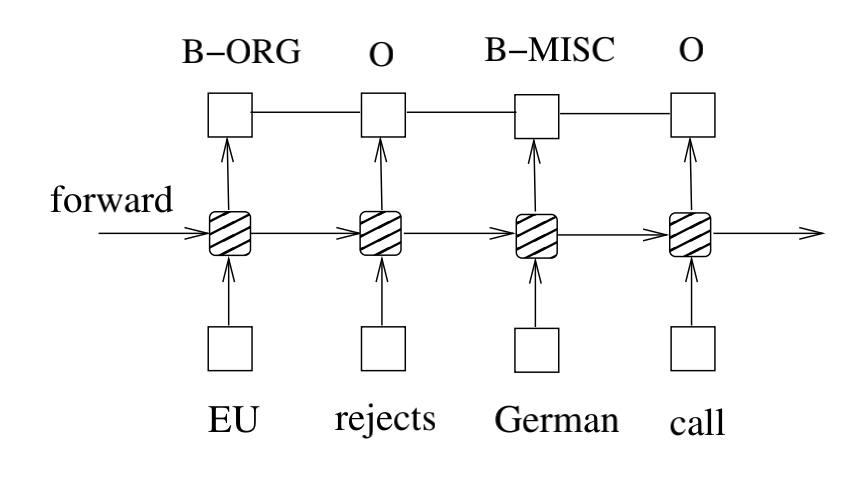
7.2.5 BI-LSTM-CRF网络
与LSTM-CRF网络类似,我们将一个双向LSTM网络和一个CRF网络合并成为一个BI-LSTM-CRF网络(下图)。除像LSTM-CRF模型那样能够利用过去的输入特征和句子级别的标签信息之外,BI-LSTM-CRF模型还能够利用未来的输入特征,这项额外的功能可以提高标注的准确性,正如我们将在实验中展示的那样。

7.2.6 训练过程
该论文使用的所有模型都有一个通用的SGD前向和后向的训练程序。我们选择最复杂的模型BI-LSTM-CRF,来展示算法1中描述的训练算法。在每一次迭代中,我们将整个训练数据分成很多批次,每一次处理一批。每一个批次包含一个句子列表,列表的大小由参数 batch size 决定。在我们的实验中,每一个批次的大小为100([ batch size ] = 100),这意味着每一次处理的句子列表的大小不会超出100。对于每个批次,我们首先运行BI-LSTM-CRF模型进行前向传递,其包括LSTM的前向状态和后向状态的前向传递。我们会获取所有位置的所有标签的输出分数作为结果。然后,我们运行CRF层的前向和后向传递,以计算网络输出和状态转换边缘的梯度。做完这些,我们将错误从输出反向传播到输入,这包括对LSTM前向和后向状态的反向传递。最后,我们更新网络参数,这包括转移矩阵 和原初的BI-LSTM的参数。

code:https://github.com/GlassyWing/bi-lstm-crf