- AlexNet是2012年ISLVRC 2012竞赛的冠军网络,分类准确率由70%提升到了80%,在当时由于瓶颈期,提升百分之十是令人印象非常深刻的,这个网络的设计者是Hinton和他的学术Alex Krizhevsky,也是从这一年以后,深度学习就开始迅速发展。
下图是从AlexNet网络的论文中截取而来:

该网络的两点在于:
1>首次利用GPU进行网络加速;
2>使用了ReLU激活函数,而不是传统的Sigmoid激活函数(求导的过程中比较麻烦且当网络比较深的时候会出现梯度消失的现象)以及Tanh激活函数;
3>使用了LRN局部响应归一化;
4>在全连接层的前两层中使用了Dropout随机失活神经元操作,以减少过拟合。
注:Dropout操作是在最大池化下采样展平和全连接层之间使用的且Dropout失活的是输入的神经元
那么什么是过拟合现象呢?
过拟合的根本原因是特征维度过多、模型假设过于复杂、训练集过少,噪声过多,导致拟合出来的网络完美的预测了训练集,但对新数据的测试集预测结果差,过度的拟合了训练数据,而没有考虑到模型的泛化。

如何去解决过拟合现象呢?
- AlexNet的作者提出了使用Dropout的方式在网络正向传播过程中随机失活一部分神经元,左图是一个正常的全连接的正向传播过程,每个结点都与下层节点进行全连接,如果使用了Dropout之后,就会每一层中随机的失活一部分神经元,可以变向的认为Dropout操作减少了网络中的训练参数,从而达到解决过拟合。

下面就开始对AlexNet的网络结构进行详解:
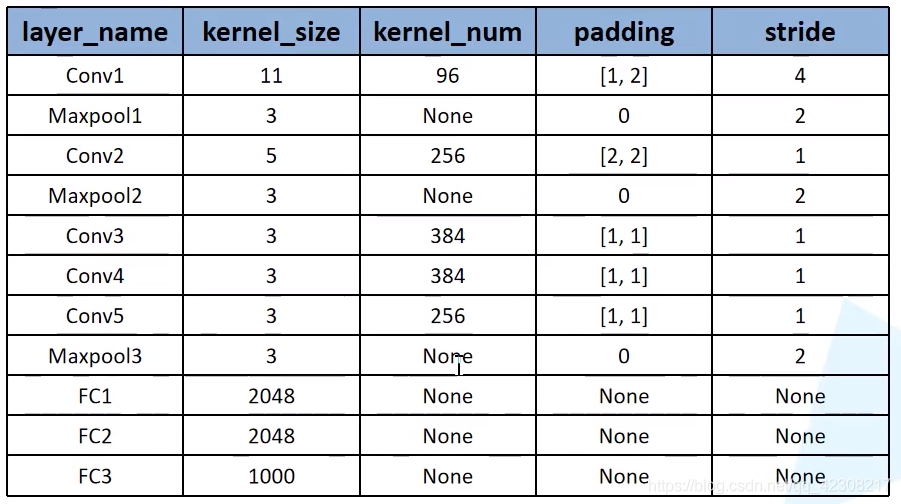
原文中的网络有上下两层,其原因是当时作者是用两块GPU进行并行运算,为了方便理解只用看其中一部分,因为网络的上下两层都是一模一样的,从图中可以看出原始图像是[224,224,3]的彩色图像,
- 第一个卷积层的卷积核大小为[11,11],stride=4,卷积核个数为48,由于上下两层都有48个,所以一共有96个卷积核,当然这个图并没有标注padding的个数,能够得到的只有卷积后的特征层的大小为[55,55,96],用公式可以推算出,在输入的左边加一列0,右边加两列0,上面加上一列0,下面加上两列0;
- 第二个层是最大池化下采样,图中并没有给出池化核的大小和stride,但可以通过查一些其他资料得出,其kernel_size=3,padding=0,stride=2,注意,池化操作只会改变特征的宽高,不会改变特征矩阵的深度;
- 再下一次又是一个卷积层,根据图中的标注可以得出卷积核的个数为128×2=256个,卷积核的大小为5,同时根据查阅的资料和一些源码,可以得出padding=[2,2],stride=1,最后通过公式得到输出为[27,27,256];
- 在跟一个最大池化下采样,其卷积核的大小也是等于3,padding=1,stride=2,输出为[13,13,256];
- 第三个卷积层:从图中信息可以得出卷积核的个数为192×2=384,卷积核大小为3,查阅资料得出,padding=[1,1],stride=1,代入公式得到输出[13,13,384];
- 第四个卷积层:和第三个卷积层的配置一模一样,所以输入和输出的维度都是[13,13,384]
- 第五个卷积层:卷积核的个数为158×2=256,卷积核大小=3,padding=[1,1],stride=1,输出为[13,13,256]
- 最后一个最大池化下采样层,图中并没有给出这个层的任何信息,通过参考一些资料和源码,得到kernel_size=3,padding=0,stride=2,所以最终输出是[6,6,256]
- 最后接了三个全连接层,就不需要对其进行分析了,只需要对下采样后的输出进行展平进行全连接就可以了,这里有必要提一下最后一个层,图中是1000个结点,因为论文的数据集有一千个类别,所以有一千个结点,如果要将网络运用到我们自己的数据集,则有几个分类改成几就okay了。

AlexNet网络结构总体如下: