Map体系集合

Map接口的特点:
用于存储任意键值对(Key-Value)。
键:无序、无下标、不允许重复(唯一)。
值:无序、无下标、允许重复。
特点:存储一对数据(Key-Value),无序、无下标,键不可重复。
方法:
V put(K key,V value)//将对象存入到集合中,关联键值。key重复则覆盖原值。
Object get(Object key)//根据键获取相应的值。
keySet//返回所有的key
Collection values()//返回包含所有值的Collection集合。
entrySet<Map.Entry<K,V>>//键值匹配的set集合


/**
* Map接口的使用
* 特点:1.存储键值对 2.键不能重复,值可以重复 3.无序
*/
public class Demo1 {
public static void main(String[] args) {
Map<String,Integer> map=new HashMap<String, Integer>();
//1.添加元素
map.put("tang", 21);
map.put("he", 22);
map.put("fan", 23);
System.out.println(map.toString());
//2.删除元素
map.remove("he");
System.out.println(map.toString());
//3.遍历
//3.1 使用keySet();
for (String key : map.keySet()) {
System.out.println(key+" "+map.get(key));
}
//3.2 使用entrySet();效率较高
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}
}
}
HashMap【重点】
JDK1.2版本,线程不安全,运行效率快;允许用null作为key或是value。
/**
* 学生类
*/
public class Student {
private String name;
private int id;
public Student(String name, int id) {
super();
this.name = name;
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + id + "]";
}
}
/**
* HashMap的使用
* 存储结构:哈希表(数组+链表+红黑树)
*/
public class Demo2 {
public static void main(String[] args) {
HashMap<Student, String> hashMap=new HashMap<Student, String>();
Student s1=new Student("tang", 36);
Student s2=new Student("yu", 101);
Student s3=new Student("he", 10);
//1.添加元素
hashMap.put(s1, "成都");
hashMap.put(s2, "杭州");
hashMap.put(s3, "郑州");
//添加失败,但会更新值
hashMap.put(s3,"上海");
//添加成功,不过两个属性一模一样;
//注:假如相同属性便认为是同一个对象,怎么修改?
hashMap.put(new Student("he", 10),"上海");
System.out.println(hashMap.toString());
//2.删除元素
hashMap.remove(s3);
System.out.println(hashMap.toString());
//3.遍历
//3.1 使用keySet()遍历
for (Student key : hashMap.keySet()) {
System.out.println(key+" "+hashMap.get(key));
}
//3.2 使用entrySet()遍历
for (Entry<Student, String> entry : hashMap.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}
//4.判断
//注:同上
System.out.println(hashMap.containsKey(new Student("he", 10)));
System.out.println(hashMap.containsValue("成都"));
}
}
注:和之前说过的HashSet类似,重复依据是hashCode和equals方法,重写即可:
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + id;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Student other = (Student) obj;
if (id != other.id)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
HashMap源码分析
默认初始化容量:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16

数组最大容量:
static final int MAXIMUM_CAPACITY = 1 << 30;
默认加载因子:
static final float DEFAULT_LOAD_FACTOR = 0.75f; //扩容
链表调整为红黑树的链表长度阈值(JDK1.8):
static final int TREEIFY_THRESHOLD = 8;
红黑树调整为链表的链表长度阈值(JDK1.8):
static final int UNTREEIFY_THRESHOLD = 6;
链表调整为红黑树的数组最小阈值(JDK1.8):
static final int MIN_TREEIFY_CAPACITY = 64;
HashMap存储的数组:
transient Node<K,V>[] table;
HashMap存储的元素个数:
transient int size;


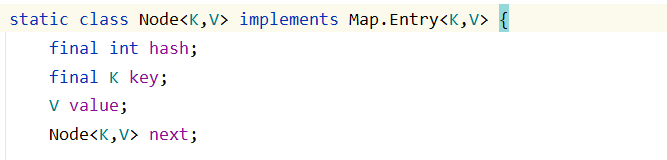
HashMap的数组table存储的就是一个个的Node<K,V>类型,很清晰地看到有一对键值,还有一个指向next的指针(以下只截取了部分源码):
之前的代码中在new对象时调用的是HashMap的无参构造方法,进入到该构造方法的源码查看一下:

static final float DEFAULT_LOAD_FACTOR = 0.75f;
发现没什么内容,只是赋值了一个默认加载因子;而在上文我们观察到源码中table和size都没有赋予初始值,说明刚创建的HashMap对象没有分配容量,并不拥有默认的16个空间大小,这样做的目的是为了节约空间,此时table为null,size为0
当我们往对象里添加元素时调用put方法:


这里面创建了一个tab数组和一个Node变量p,第一个if实际是判断table是否为空,而我们现在只关注刚创建HashMap对象时的状态,此时tab和table都为空,满足条件,执行内部代码,这条代码其实就是把resize()所返回的结果赋给tab,n就是tab的长度,resize顾名思义就是重新调整大小。查看resize()源码(部分):
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
if (oldCap > 0);
else if (oldThr > 0);
else {
// zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY; //16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); //12
}
@SuppressWarnings({
"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
return newTab;
}
该方法首先把table及其长度赋值给oldTab和oldCap;

threshold是阈值的意思,此时为0,
所以前两个if先不管,最后else里newCap的值为默认初始化容量16;往下创建了一个newCap大小的数组并将其赋给了table,刚创建的HashMap对象就在这里获得了初始容量。然后我们再回到putVal方法,第二个if就是根据哈希码得到的tab中的一个位置是否为空,为空便直接添加元素,此时数组中无元素所以直接添加。至此HashMap对象就完成了第一个元素的添加。当添加的元素超过16*0.75=12时,就会进行扩容
final Node<K,V>[] resize() {
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int newCap;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
//略}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
}
}
核心部分是else if里的移位操作,也就是说每次扩容都是原来大小的两倍。
HashSet源码分析
hashSet里面用的就是hashMap
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
}
可以看见HashSet的存储结构就是HashMap,那它的存储方式是怎样的呢?可以看一下add方法:
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
很明了地发现它的add方法调用的就是map的put方法,把元素作为map的key传进去的。
Hashtable
JDK1.0版本,线程安全,运行效率慢;不允许null作为key或是value。
初始容量11,加载因子0.75。
这个集合在开发过程中已经不用了,稍微了解即可。
Properties
Hashtable的子类,要求key和value都是String。通常用于配置文件的读取。
它继承了Hashtable的方法,与流关系密切,此处不详解。
TreeMap
实现了SortedMap接口(是Map的子接口),可以对key自动排序。
/**
* TreeMap的使用
* 存储结构:红黑树
*/
public class Test{
public static void main(String[] args) {
TreeMap<Student, Integer> treeMap=new TreeMap<Student, Integer>();
Student s1=new Student("tang", 36);
Student s2=new Student("yu", 101);
Student s3=new Student("he", 10);
//1.添加元素
treeMap.put(s1, 21);
treeMap.put(s2, 22);
treeMap.put(s3, 21);
//不能直接打印,需要实现Comparable接口,因为红黑树需要比较大小
System.out.println(treeMap.toString());
//2.删除元素
treeMap.remove(new Student("he", 10));
System.out.println(treeMap.toString());
//3.遍历
//3.1 使用keySet()
for (Student key : treeMap.keySet()) {
System.out.println(key+" "+treeMap.get(key));
}
//3.2 使用entrySet()
for (Entry<Student, Integer> entry : treeMap.entrySet()) {
System.out.println(entry.getKey()+" "+entry.getValue());
}
//4.判断
System.out.println(treeMap.containsKey(s1));
System.out.println(treeMap.isEmpty());
}
}
public class Student implements Comparable<Student>{
@Override
public int compareTo(Student o) {
int n1=this.id-o.id;
return n1;
}
TreeSet源码
和HashSet类似,放在TreeMap之后讲便一目了然(部分):
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
private transient NavigableMap<E,Object> m;
private static final Object PRESENT = new Object();
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap<E,Object>());
}
}
TreeSet的存储结构实际上就是TreeMap,再来看其存储方式:
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
它的add方法调用的就是TreeMap的put方法,将元素作为key传入到存储结构中
Collections工具类
概念:集合工具类,定义了除了存取以外的集合常用方法。
方法:
public static void reverse(List<?> list)//反转集合中元素的顺序
public static void shuffle(List<?> list)//随机重置集合元素的顺序
public static void sort(List list)//升序排序(元素类型必须实现Comparable接口)
/**
* 演示Collections工具类的使用
*
*/
public class Test{
public static void main(String[] args) {
List<Integer> list=new ArrayList<Integer>();
list.add(20);
list.add(10);
list.add(30);
list.add(90);
list.add(70);
//sort排序
System.out.println(list.toString());
Collections.sort(list);
System.out.println(list.toString());
System.out.println("---------");
//binarySearch二分查找
int i=Collections.binarySearch(list, 10);
System.out.println(i);
//copy复制
List<Integer> list2=new ArrayList<Integer>();
for(int i1=0;i1<5;++i1) {
list2.add(0);
}
//该方法要求目标元素容量大于等于源目标
Collections.copy(list2, list);
System.out.println(list2.toString());
//reserve反转
Collections.reverse(list2);
System.out.println(list2.toString());
//shuffle 打乱
Collections.shuffle(list2);
System.out.println(list2.toString());
//补充:list转成数组
Integer[] arr=list.toArray(new Integer[0]);
System.out.println(arr.length);
//补充:数组转成集合
String[] nameStrings= {
"tang","he","yu"};
//受限集合,不能添加和删除
List<String> list3=Arrays.asList(nameStrings);
System.out.println(list3);
//注:基本类型转成集合时需要修改为包装类
}
}